 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Prune-And-Factorize for Language Model Compression
Paper and Code
Jun 25, 2023


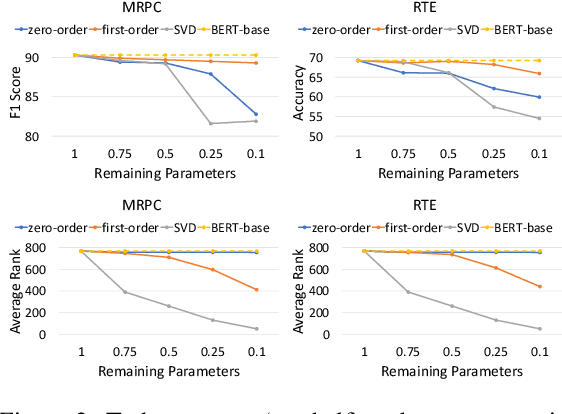
The components underpinning PLMs -- large weight matrices -- were shown to bear considerable redundancy. Matrix factorization, a well-established technique from matrix theory, has been utilized to reduce the number of parameters in PLM. However, it fails to retain satisfactory performance under moderate to high compression rate. In this paper, we identify the \textit{full-rankness} of fine-tuned PLM as the fundamental bottleneck for the failure of matrix factorization and explore the use of network pruning to extract low-rank sparsity pattern desirable to matrix factorization. We find such low-rank sparsity pattern exclusively exists in models generated by first-order pruning, which motivates us to unite the two approaches and achieve more effective model compression. We further propose two techniques: sparsity-aware SVD and mixed-rank fine-tuning, which improve the initialization and training of the compression procedure, respectively. Experiments on GLUE and question-answering tasks show that the proposed method has superior compression-performance trade-off compared to existing approaches.