 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePansharpening for Thin-Cloud Contaminated Remote Sensing Images: A Unified Framework and Benchmark Dataset
Mar 16, 2026Pansharpening under thin cloudy conditions is a practically significant yet rarely addressed task, challenged by simultaneous spatial resolution degradation and cloud-induced spectral distortions. Existing methods often address cloud removal and pansharpening sequentially, leading to cumulative errors and suboptimal performance due to the lack of joint degradation modeling. To address these challenges, we propose a Unified Pansharpening Model with Thin Cloud Removal (Pan-TCR), an end-to-end framework that integrates physical priors. Motivated by theoretical analysis in the frequency domain, we design a frequency-decoupled restoration (FDR) block that disentangles the restoration of multispectral image (MSI) features into amplitude and phase components, each guided by complementary degradation-robust prompts: the near-infrared (NIR) band amplitude for cloud-resilient restoration, and the panchromatic (PAN) phase for high-resolution structural enhancement. To ensure coherence between the two components, we further introduce an interactive inter-frequency consistency (IFC) module, enabling cross-modal refinement that enforces consistency and robustness across frequency cues. Furthermore, we introduce the first real-world thin-cloud contaminated pansharpening dataset (PanTCR-GF2), comprising paired clean and cloudy PAN-MSI images, to enable robust benchmarking under realistic conditions. Extensive experiments on real-world and synthetic datasets demonstrate the superiority and robustness of Pan-TCR, establishing a new benchmark for pansharpening under realistic atmospheric degradations.
Super4DR: 4D Radar-centric Self-supervised Odometry and Gaussian-based Map Optimization
Dec 10, 2025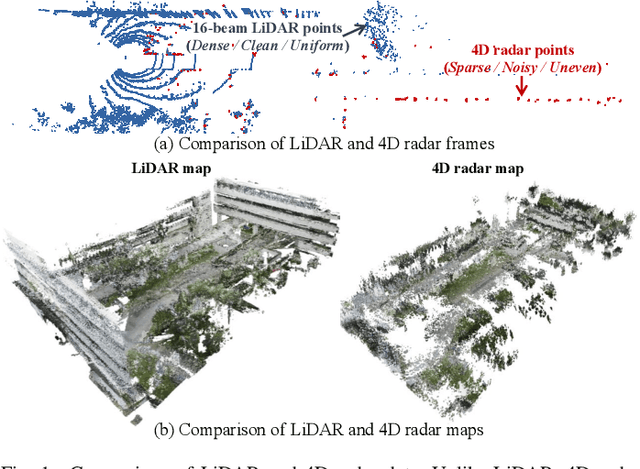
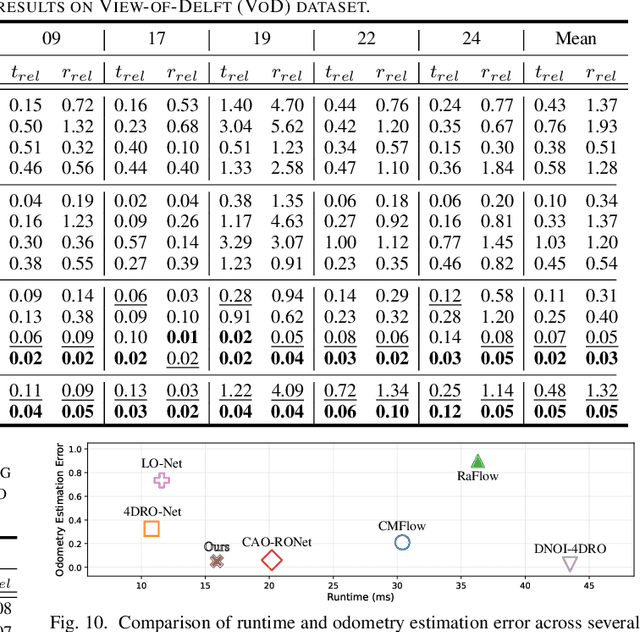
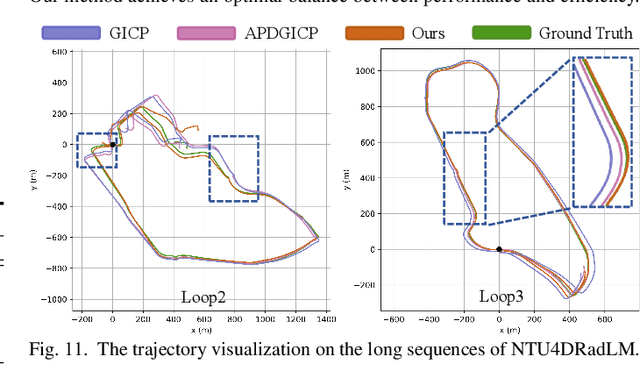

Conventional SLAM systems using visual or LiDAR data often struggle in poor lighting and severe weather. Although 4D radar is suited for such environments, its sparse and noisy point clouds hinder accurate odometry estimation, while the radar maps suffer from obscure and incomplete structures. Thus, we propose Super4DR, a 4D radar-centric framework for learning-based odometry estimation and gaussian-based map optimization. First, we design a cluster-aware odometry network that incorporates object-level cues from the clustered radar points for inter-frame matching, alongside a hierarchical self-supervision mechanism to overcome outliers through spatio-temporal consistency, knowledge transfer, and feature contrast. Second, we propose using 3D gaussians as an intermediate representation, coupled with a radar-specific growth strategy, selective separation, and multi-view regularization, to recover blurry map areas and those undetected based on image texture. Experiments show that Super4DR achieves a 67% performance gain over prior self-supervised methods, nearly matches supervised odometry, and narrows the map quality disparity with LiDAR while enabling multi-modal image rendering.
Modality Decoupling is All You Need: A Simple Solution for Unsupervised Hyperspectral Image Fusion
Dec 06, 2024Hyperspectral Image Fusion (HIF) aims to fuse low-resolution hyperspectral images (LR-HSIs) and high-resolution multispectral images (HR-MSIs) to reconstruct high spatial and high spectral resolution images. Current methods typically apply direct fusion from the two modalities without valid supervision, failing to fully perceive the deep modality-complementary information and hence, resulting in a superficial understanding of inter-modality connections. To bridge this gap, we propose a simple and effective solution for unsupervised HIF with an assumption that modality decoupling is essential for HIF. We introduce the modality clustering loss that ensures clear guidance of the modality, decoupling towards modality-shared features while steering clear of modality-complementary ones. Also, we propose an end-to-end Modality-Decoupled Spatial-Spectral Fusion (MossFuse) framework that decouples shared and complementary information across modalities and aggregates a concise representation of the LR-HSI and HR-MSI to reduce the modality redundancy. Systematic experiments over multiple datasets demonstrate that our simple and effective approach consistently outperforms the existing HIF methods while requiring considerably fewer parameters with reduced inference time.
3C: Confidence-Guided Clustering and Contrastive Learning for Unsupervised Person Re-Identification
Aug 18, 2024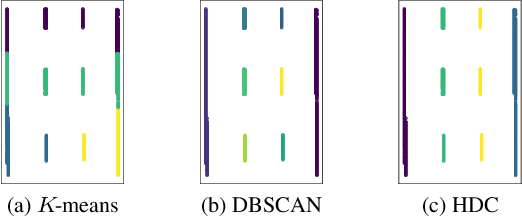

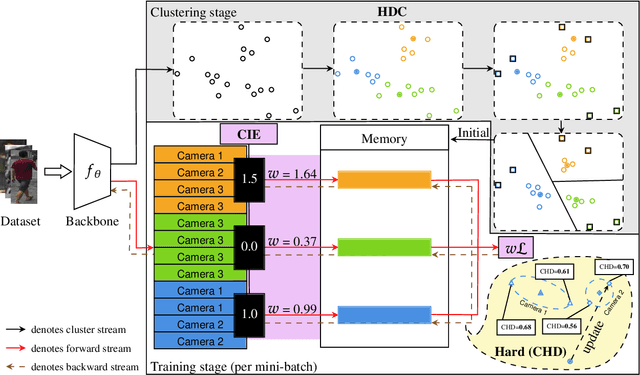

Unsupervised person re-identification (Re-ID) aims to learn a feature network with cross-camera retrieval capability in unlabelled datasets. Although the pseudo-label based methods have achieved great progress in Re-ID, their performance in the complex scenario still needs to sharpen up. In order to reduce potential misguidance, including feature bias, noise pseudo-labels and invalid hard samples, accumulated during the learning process, in this pa per, a confidence-guided clustering and contrastive learning (3C) framework is proposed for unsupervised person Re-ID. This 3C framework presents three confidence degrees. i) In the clustering stage, the confidence of the discrepancy between samples and clusters is proposed to implement a harmonic discrepancy clustering algorithm (HDC). ii) In the forward-propagation training stage, the confidence of the camera diversity of a cluster is evaluated via a novel camera information entropy (CIE). Then, the clusters with high CIE values will play leading roles in training the model. iii) In the back-propagation training stage, the confidence of the hard sample in each cluster is designed and further used in a confidence integrated harmonic discrepancy (CHD), to select the informative sample for updating the memory in contrastive learning. Extensive experiments on three popular Re-ID benchmarks demonstrate the superiority of the proposed framework. Particularly, the 3C framework achieves state-of-the-art results: 86.7%/94.7%, 45.3%/73.1% and 47.1%/90.6% in terms of mAP/Rank-1 accuracy on Market-1501, the com plex datasets MSMT17 and VeRi-776, respectively. Code is available at https://github.com/stone5265/3C-reid.
DCF-ASN: Coarse-to-fine Real-time Visual Tracking via Discriminative Correlation Filter and Attentional Siamese Network
Mar 19, 2021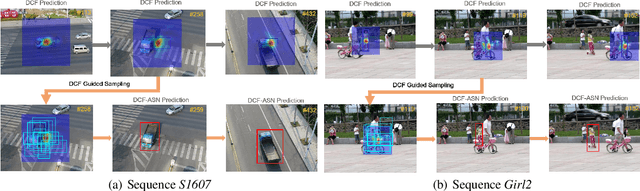
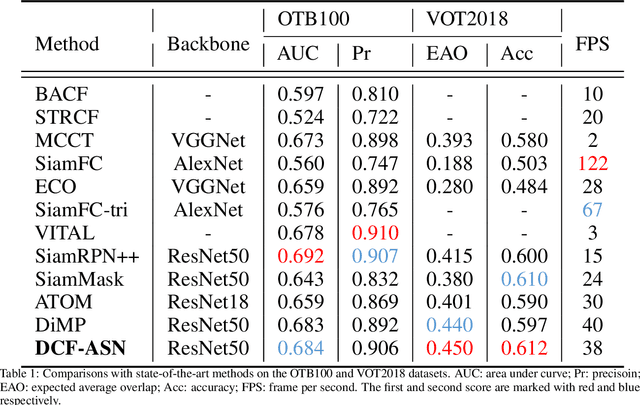
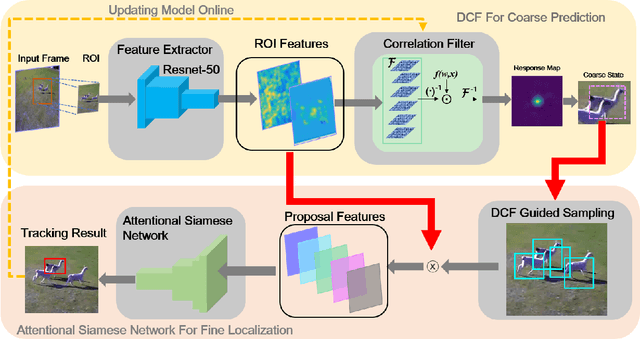

Discriminative correlation filters (DCF) and siamese networks have achieved promising performance on visual tracking tasks thanks to their superior computational efficiency and reliable similarity metric learning, respectively. However, how to effectively take advantages of powerful deep networks, while maintaining the real-time response of DCF, remains a challenging problem. Embedding the cross-correlation operator as a separate layer into siamese networks is a popular choice to enhance the tracking accuracy. Being a key component of such a network, the correlation layer is updated online together with other parts of the network. Yet, when facing serious disturbance, fused trackers may still drift away from the target completely due to accumulated errors. To address these issues, we propose a coarse-to-fine tracking framework, which roughly infers the target state via an online-updating DCF module first and subsequently, finely locates the target through an offline-training asymmetric siamese network (ASN). Benefitting from the guidance of DCF and the learned channel weights obtained through exploiting the given ground-truth template, ASN refines feature representation and implements precise target localization. Systematic experiments on five popular tracking datasets demonstrate that the proposed DCF-ASN achieves the state-of-the-art performance while exhibiting good tracking efficiency.
Hyperspectral Classification Based on Lightweight 3-D-CNN With Transfer Learning
Dec 07, 2020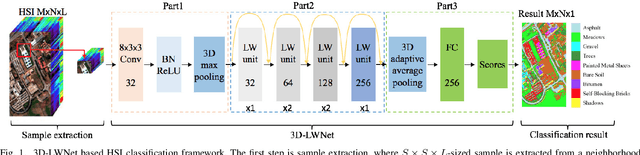
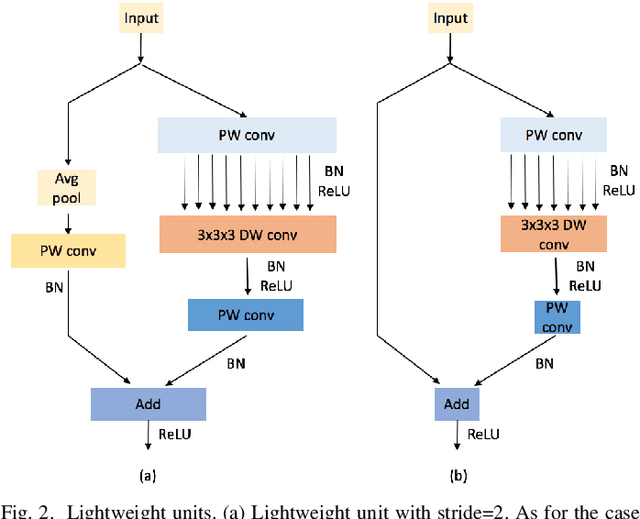
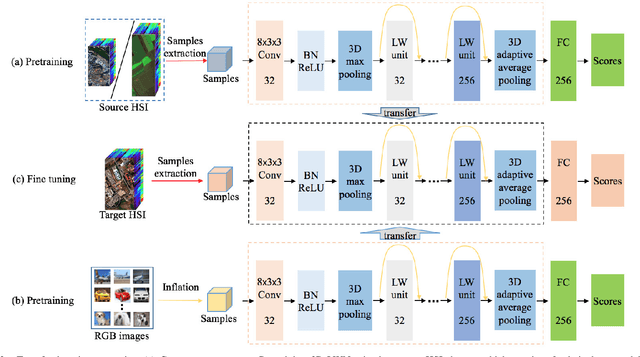

Recently, hyperspectral image (HSI) classification approaches based on deep learning (DL) models have been proposed and shown promising performance. However, because of very limited available training samples and massive model parameters, DL methods may suffer from overfitting. In this paper, we propose an end-to-end 3-D lightweight convolutional neural network (CNN) (abbreviated as 3-D-LWNet) for limited samples-based HSI classification. Compared with conventional 3-D-CNN models, the proposed 3-D-LWNet has a deeper network structure, less parameters, and lower computation cost, resulting in better classification performance. To further alleviate the small sample problem, we also propose two transfer learning strategies: 1) cross-sensor strategy, in which we pretrain a 3-D model in the source HSI data sets containing a greater number of labeled samples and then transfer it to the target HSI data sets and 2) cross-modal strategy, in which we pretrain a 3-D model in the 2-D RGB image data sets containing a large number of samples and then transfer it to the target HSI data sets. In contrast to previous approaches, we do not impose restrictions over the source data sets, in which they do not have to be collected by the same sensors as the target data sets. Experiments on three public HSI data sets captured by different sensors demonstrate that our model achieves competitive performance for HSI classification compared to several state-of-the-art methods
* 16 pages. Accepted to IEEE Trans. Geosci. Remote Sens. Code is available at: https://github.com/hkzhang91/LWNet
Robust Correlation Tracking via Multi-channel Fused Features and Reliable Response Map
Nov 25, 2020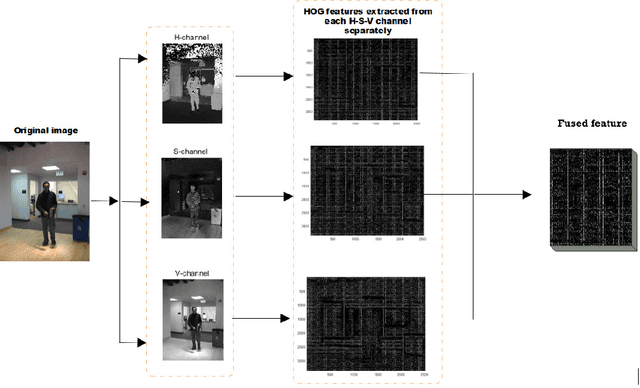

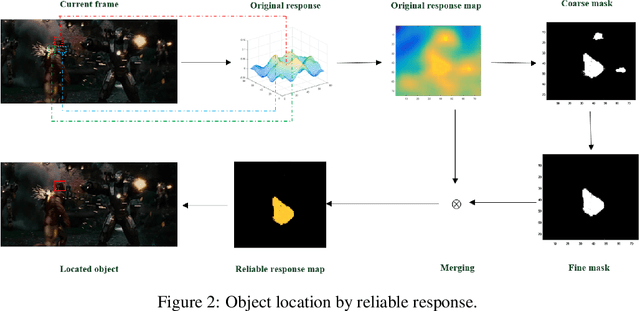
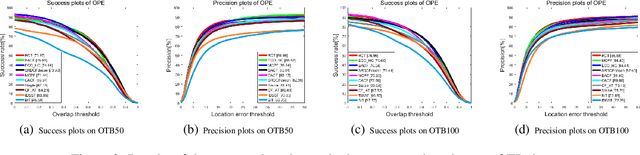
Benefiting from its ability to efficiently learn how an object is changing, correlation filters have recently demonstrated excellent performance for rapidly tracking objects. Designing effective features and handling model drifts are two important aspects for online visual tracking. This paper tackles these challenges by proposing a robust correlation tracking algorithm (RCT) based on two ideas: First, we propose a method to fuse features in order to more naturally describe the gradient and color information of the tracked object, and introduce the fused features into a background aware correlation filter to obtain the response map. Second, we present a novel strategy to significantly reduce noise in the response map and therefore ease the problem of model drift. Systematic comparative evaluations performed over multiple tracking benchmarks demonstrate the efficacy of the proposed approach.
Multi-Modal Subjective Context Modelling and Recognition
Nov 19, 2020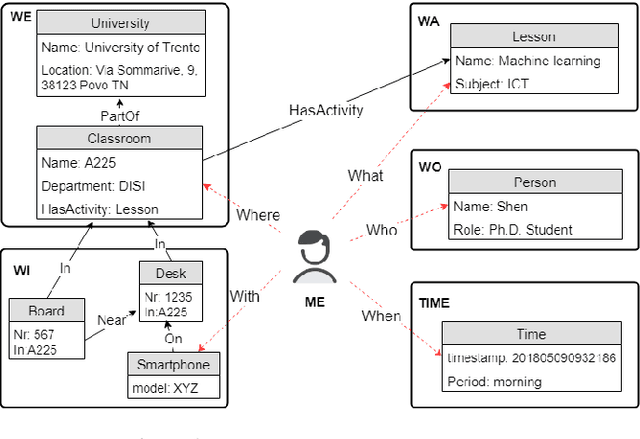

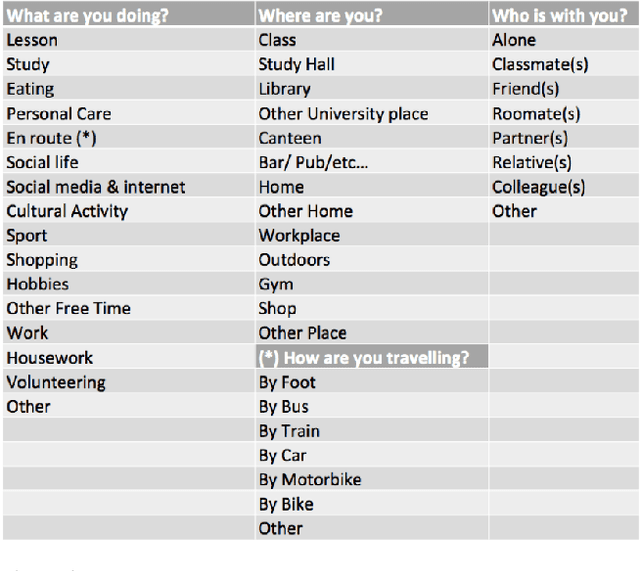
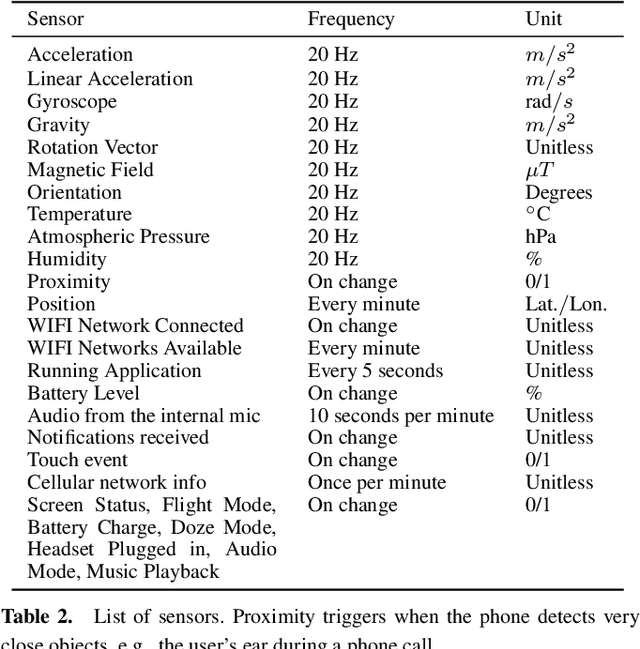
Applications like personal assistants need to be aware ofthe user's context, e.g., where they are, what they are doing, and with whom. Context information is usually inferred from sensor data, like GPS sensors and accelerometers on the user's smartphone. This prediction task is known as context recognition. A well-defined context model is fundamental for successful recognition. Existing models, however, have two major limitations. First, they focus on few aspects, like location or activity, meaning that recognition methods based onthem can only compute and leverage few inter-aspect correlations. Second, existing models typically assume that context is objective, whereas in most applications context is best viewed from the user's perspective. Neglecting these factors limits the usefulness of the context model and hinders recognition. We present a novel ontological context model that captures five dimensions, namely time, location, activity, social relations and object. Moreover, our model defines three levels of description(objective context, machine context and subjective context) that naturally support subjective annotations and reasoning.An initial context recognition experiment on real-world data hints at the promise of our model.
Decoder Choice Network for Meta-Learning
Sep 25, 2019
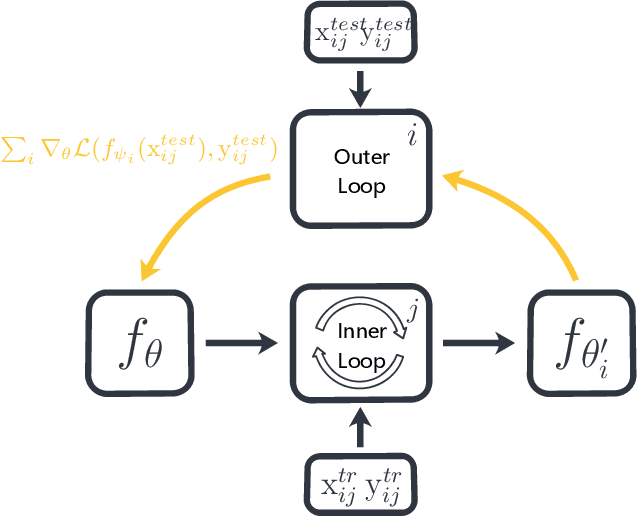
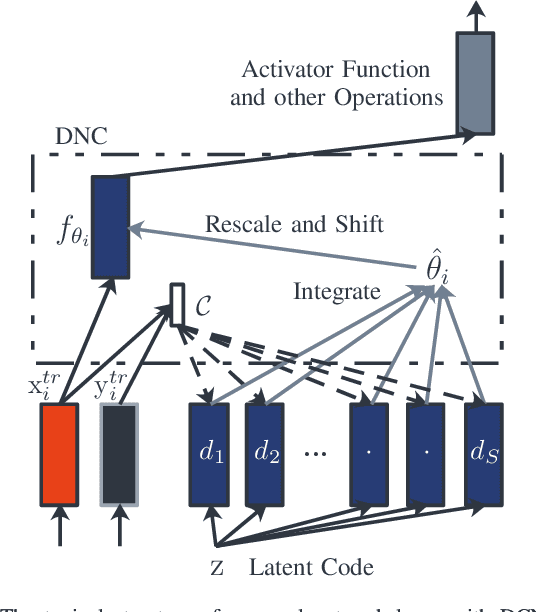
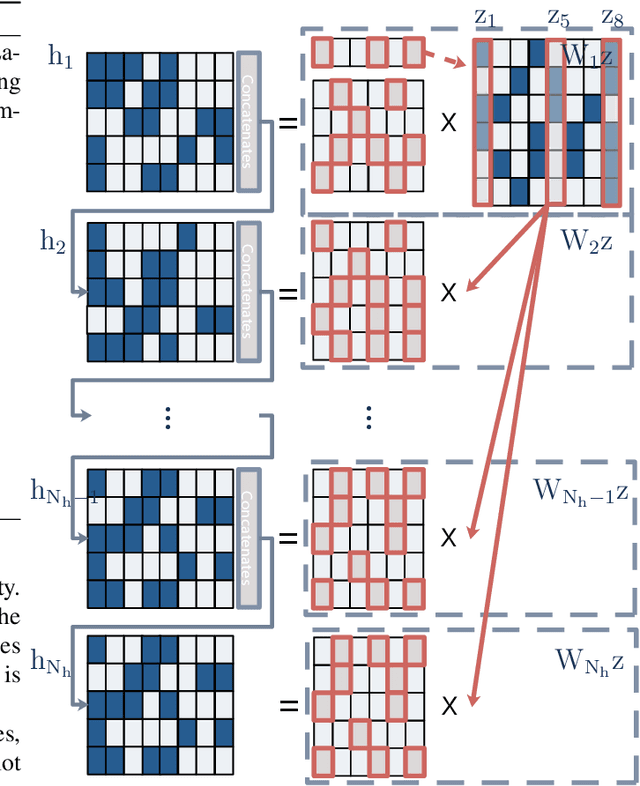
Meta-learning has been widely used for implementing few-shot learning and fast model adaptation. One kind of meta-learning methods attempt to learn how to control the gradient descent process in order to make the gradient-based learning have high speed and generalization. This work proposes a method that controls the gradient descent process of the model parameters of a neural network by limiting the model parameters in a low-dimensional latent space. The main challenge of this idea is that a decoder with too many parameters is required. This work designs a decoder with typical structure and shares a part of weights in the decoder to reduce the number of the required parameters. Besides, this work has introduced ensemble learning to work with the proposed approach for improving performance. The results show that the proposed approach is witnessed by the superior performance over the Omniglot classification and the miniImageNet classification tasks.
DS-VIO: Robust and Efficient Stereo Visual Inertial Odometry based on Dual Stage EKF
May 02, 2019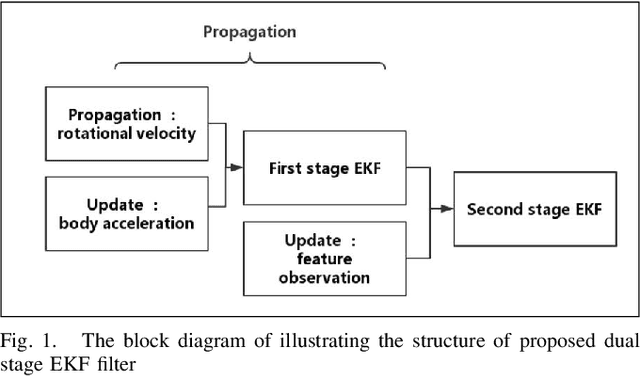
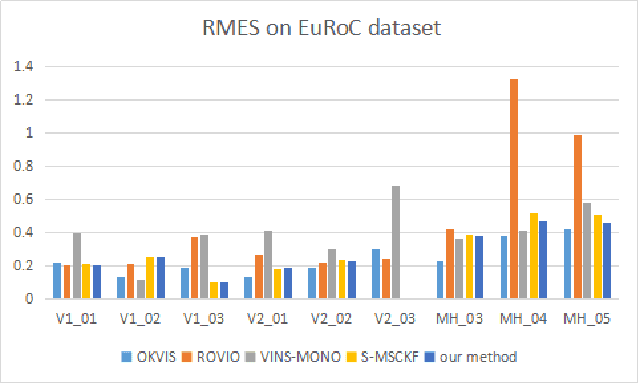

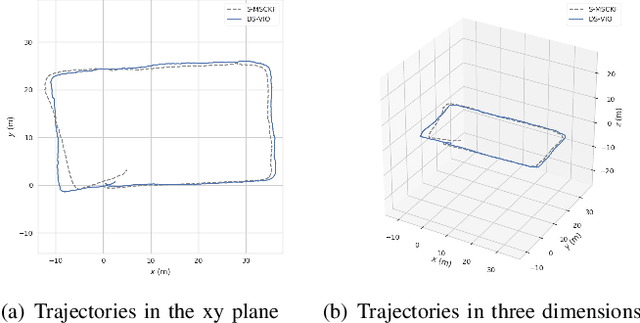
This paper presents a dual stage EKF (Extended Kalman Filter)-based algorithm for the real-time and robust stereo VIO (visual inertial odometry). The first stage of this EKF-based algorithm performs the fusion of accelerometer and gyroscope while the second performs the fusion of stereo camera and IMU. Due to the sufficient complementary characteristics between accelerometer and gyroscope as well as stereo camera and IMU, the dual stage EKF-based algorithm can achieve a high precision of odometry estimations. At the same time, because of the low dimension of state vector in this algorithm, its computational efficiency is comparable to previous filter-based approaches. We call our approach DS-VIO (dual stage EKFbased stereo visual inertial odometry) and evaluate our DSVIO algorithm by comparing it with the state-of-art approaches including OKVIS, ROVIO, VINS-MONO and S-MSCKF on the EuRoC dataset. Results show that our algorithm can achieve comparable or even better performances in terms of the RMS error