 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
Multi-Modal Subjective Context Modelling and Recognition
Nov 19, 2020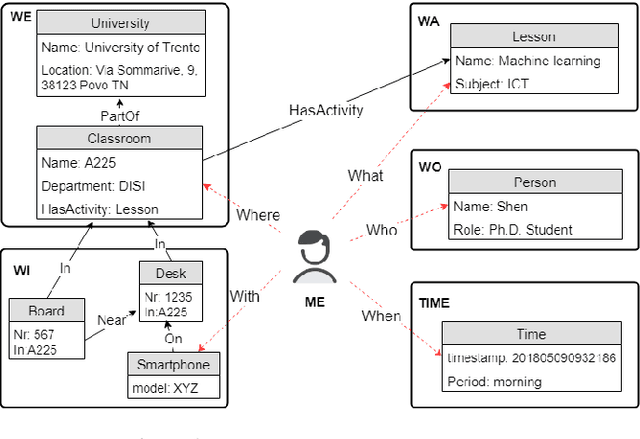

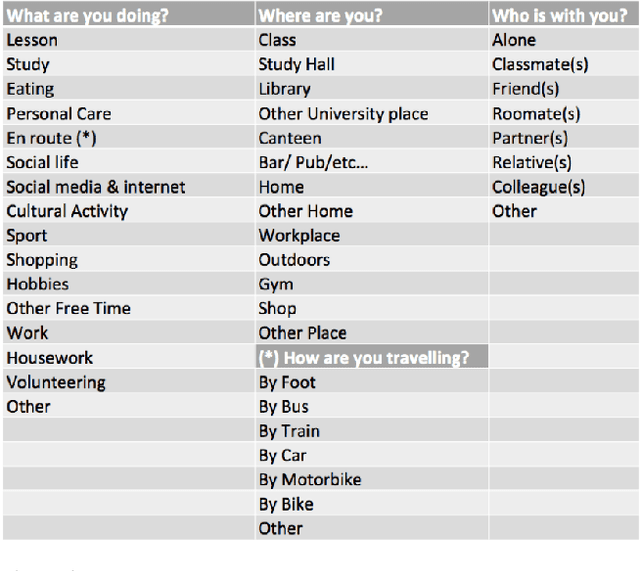
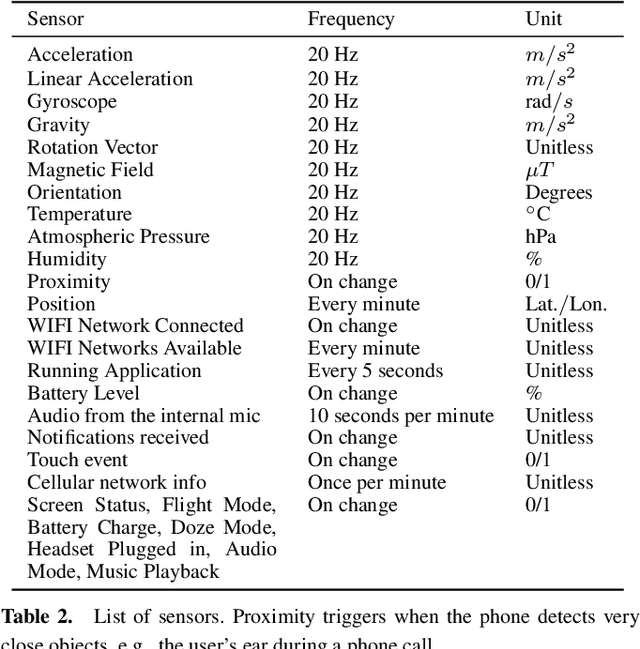
Applications like personal assistants need to be aware ofthe user's context, e.g., where they are, what they are doing, and with whom. Context information is usually inferred from sensor data, like GPS sensors and accelerometers on the user's smartphone. This prediction task is known as context recognition. A well-defined context model is fundamental for successful recognition. Existing models, however, have two major limitations. First, they focus on few aspects, like location or activity, meaning that recognition methods based onthem can only compute and leverage few inter-aspect correlations. Second, existing models typically assume that context is objective, whereas in most applications context is best viewed from the user's perspective. Neglecting these factors limits the usefulness of the context model and hinders recognition. We present a novel ontological context model that captures five dimensions, namely time, location, activity, social relations and object. Moreover, our model defines three levels of description(objective context, machine context and subjective context) that naturally support subjective annotations and reasoning.An initial context recognition experiment on real-world data hints at the promise of our model.
Breast Cancer Classification with Ultrasound Images Based on SLIC
Apr 25, 2019

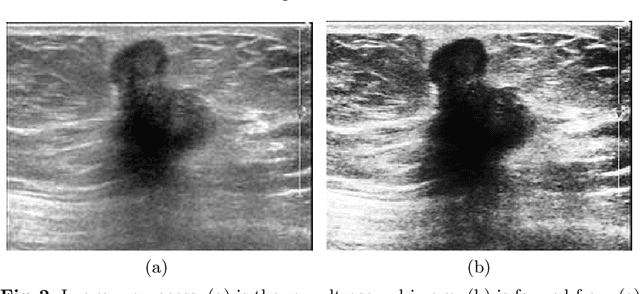

Ultrasound image diagnosis of breast tumors has been widely used in recent years. However, there are some problems of it, for instance, poor quality, intense noise and uneven echo distribution, which has created a huge obstacle to diagnosis. To overcome these problems, we propose a novel method, a breast cancer classification with ultrasound images based on SLIC (BCCUI). We first utilize the Region of Interest (ROI) extraction based on Simple Linear Iterative Clustering (SLIC) algorithm and region growing algorithm to extract the ROI at the super-pixel level. Next, the features of ROI are extracted. Furthermore, the Support Vector Machine (SVM) classifier is applied. The calculation states that the accuracy of this segment algorithm is up to 88.00% and the sensitivity of the algorithm is up to 92.05%, which proves that the classifier presents in this paper has certain research meaning and applied worthiness.