 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAME: Self-Supervised Masked Autoencoder for No-Reference Point Cloud Quality Assessment
Paper and Code
Mar 15, 2024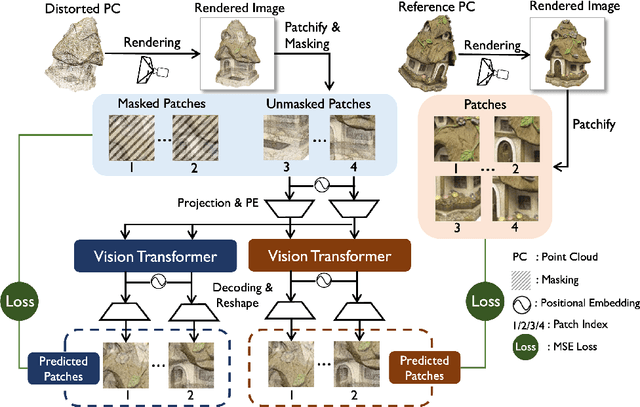
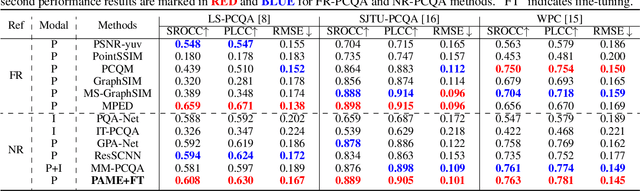
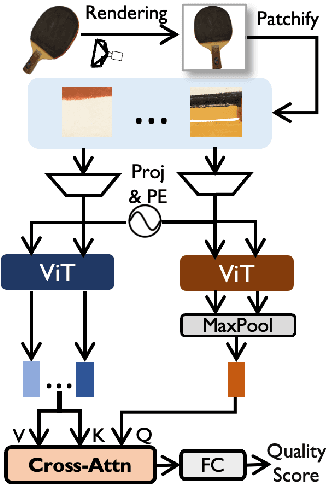
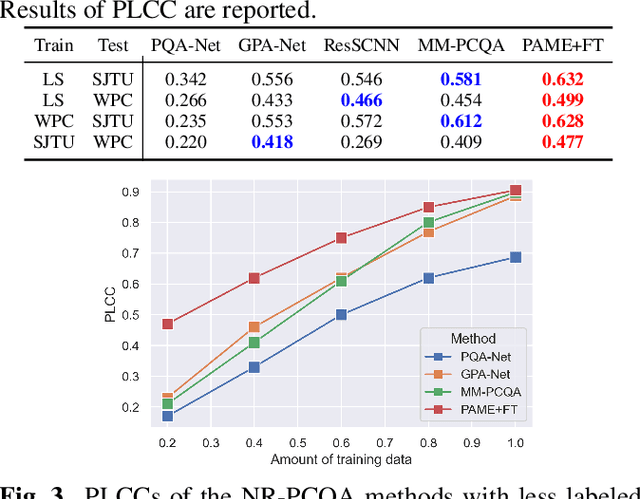
No-reference point cloud quality assessment (NR-PCQA) aims to automatically predict the perceptual quality of point clouds without reference, which has achieved remarkable performance due to the utilization of deep learning-based models. However, these data-driven models suffer from the scarcity of labeled data and perform unsatisfactorily in cross-dataset evaluations. To address this problem, we propose a self-supervised pre-training framework using masked autoencoders (PAME) to help the model learn useful representations without labels. Specifically, after projecting point clouds into images, our PAME employs dual-branch autoencoders, reconstructing masked patches from distorted images into the original patches within reference and distorted images. In this manner, the two branches can separately learn content-aware features and distortion-aware features from the projected images. Furthermore, in the model fine-tuning stage, the learned content-aware features serve as a guide to fuse the point cloud quality features extracted from different perspectives. Extensive experiments show that our method outperforms the state-of-the-art NR-PCQA methods on popular benchmarks in terms of prediction accuracy and generalizability.