 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Pre-Training with Multi-View Fusion for No-Reference Point Cloud Quality Assessment
Mar 27, 2024

No-reference point cloud quality assessment (NR-PCQA) aims to automatically evaluate the perceptual quality of distorted point clouds without available reference, which have achieved tremendous improvements due to the utilization of deep neural networks. However, learning-based NR-PCQA methods suffer from the scarcity of labeled data and usually perform suboptimally in terms of generalization. To solve the problem, we propose a novel contrastive pre-training framework tailored for PCQA (CoPA), which enables the pre-trained model to learn quality-aware representations from unlabeled data. To obtain anchors in the representation space, we project point clouds with different distortions into images and randomly mix their local patches to form mixed images with multiple distortions. Utilizing the generated anchors, we constrain the pre-training process via a quality-aware contrastive loss following the philosophy that perceptual quality is closely related to both content and distortion. Furthermore, in the model fine-tuning stage, we propose a semantic-guided multi-view fusion module to effectively integrate the features of projected images from multiple perspectives. Extensive experiments show that our method outperforms the state-of-the-art PCQA methods on popular benchmarks. Further investigations demonstrate that CoPA can also benefit existing learning-based PCQA models.
PAME: Self-Supervised Masked Autoencoder for No-Reference Point Cloud Quality Assessment
Mar 15, 2024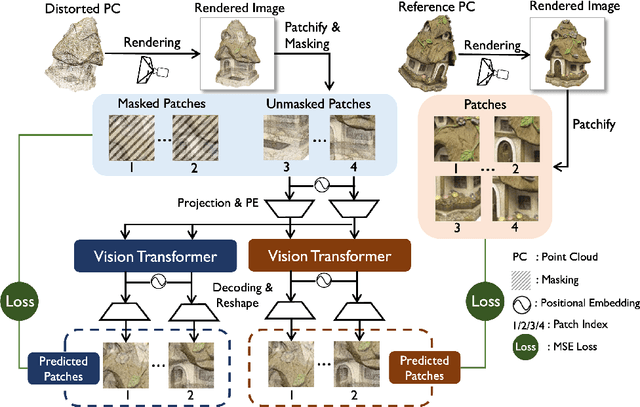
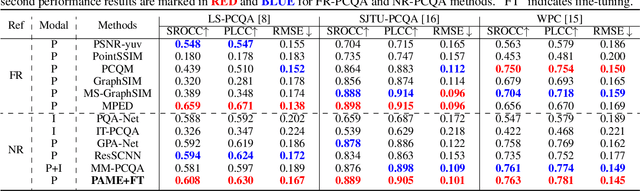
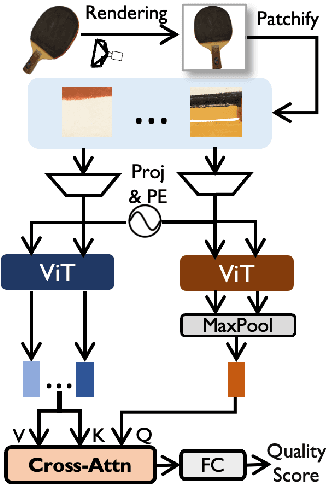
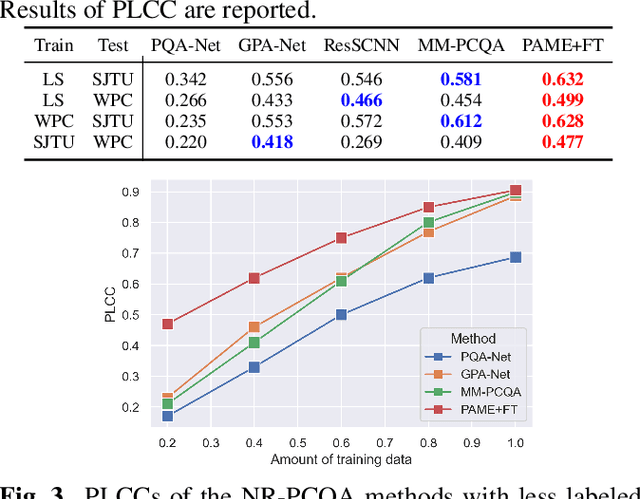
No-reference point cloud quality assessment (NR-PCQA) aims to automatically predict the perceptual quality of point clouds without reference, which has achieved remarkable performance due to the utilization of deep learning-based models. However, these data-driven models suffer from the scarcity of labeled data and perform unsatisfactorily in cross-dataset evaluations. To address this problem, we propose a self-supervised pre-training framework using masked autoencoders (PAME) to help the model learn useful representations without labels. Specifically, after projecting point clouds into images, our PAME employs dual-branch autoencoders, reconstructing masked patches from distorted images into the original patches within reference and distorted images. In this manner, the two branches can separately learn content-aware features and distortion-aware features from the projected images. Furthermore, in the model fine-tuning stage, the learned content-aware features serve as a guide to fuse the point cloud quality features extracted from different perspectives. Extensive experiments show that our method outperforms the state-of-the-art NR-PCQA methods on popular benchmarks in terms of prediction accuracy and generalizability.