 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLLoRA: An Approach to Measure the Effects of the Context Length for LLM Fine-Tuning
Feb 26, 2025Large language model fine-tuning has been identified as an efficient approach to applying the pre-trained Large language models to other domains. To guarantee data privacy for different data owners, models are often fine-tuned in federated learning environments across different data owners, which often involve data heterogeneity issues and affect the fine-tuning performance. In addition, the length of the context for the training data has been identified as a major factor that affects the LLM's model performance. To efficiently measure how the context length affects the LLM's model performance in heterogeneous federated learning environments, we propose CLLoRA. CLLoRA utilizes the parameter-efficient fine-tuning approach LoRA based on different kinds of LLMs with varying sizes as the fine-tuning approach to investigate whether the quality and length of contexts can serve as standards for measuring non-IID context. The findings indicate that an imbalance in context quality not only affects local training on clients but also impacts the global model's performance. However, context length has a minimal effect on local training but a more significant influence on the global model. These results provide insights into how context quality and length affect the model performance for LLM fine-tuning in federated learning environments.
Mitigating Unfairness via Evolutionary Multi-objective Ensemble Learning
Oct 30, 2022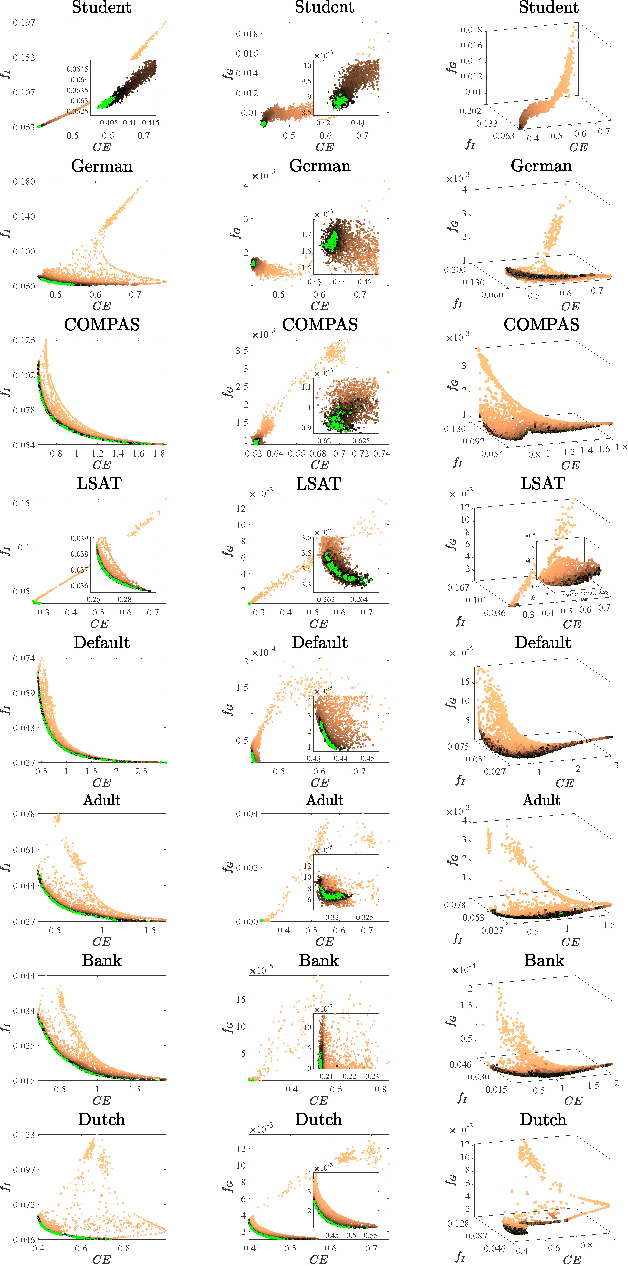
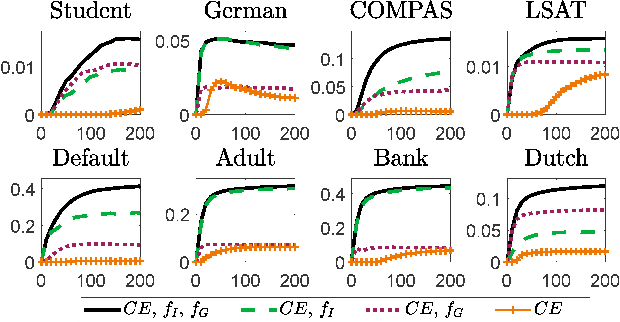
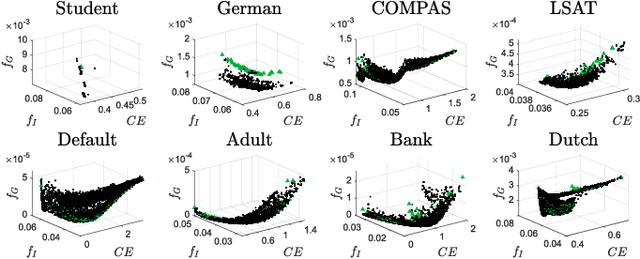
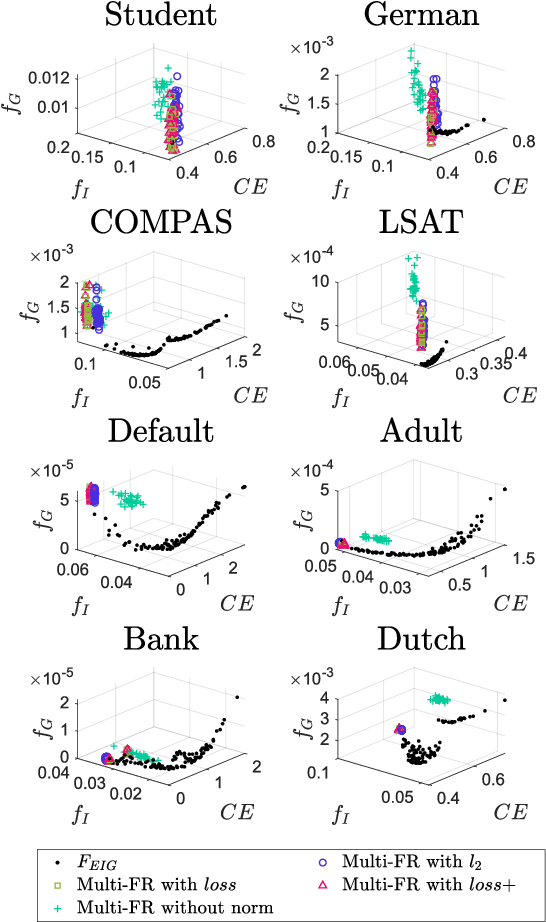
In the literature of mitigating unfairness in machine learning, many fairness measures are designed to evaluate predictions of learning models and also utilised to guide the training of fair models. It has been theoretically and empirically shown that there exist conflicts and inconsistencies among accuracy and multiple fairness measures. Optimising one or several fairness measures may sacrifice or deteriorate other measures. Two key questions should be considered, how to simultaneously optimise accuracy and multiple fairness measures, and how to optimise all the considered fairness measures more effectively. In this paper, we view the mitigating unfairness problem as a multi-objective learning problem considering the conflicts among fairness measures. A multi-objective evolutionary learning framework is used to simultaneously optimise several metrics (including accuracy and multiple fairness measures) of machine learning models. Then, ensembles are constructed based on the learning models in order to automatically balance different metrics. Empirical results on eight well-known datasets demonstrate that compared with the state-of-the-art approaches for mitigating unfairness, our proposed algorithm can provide decision-makers with better tradeoffs among accuracy and multiple fairness metrics. Furthermore, the high-quality models generated by the framework can be used to construct an ensemble to automatically achieve a better tradeoff among all the considered fairness metrics than other ensemble methods. Our code is publicly available at https://github.com/qingquan63/FairEMOL
Universal Learned Image Compression With Low Computational Cost
Jun 23, 2022


Recently, learned image compression methods have developed rapidly and exhibited excellent rate-distortion performance when compared to traditional standards, such as JPEG, JPEG2000 and BPG. However, the learning-based methods suffer from high computational costs, which is not beneficial for deployment on devices with limited resources. To this end, we propose shift-addition parallel modules (SAPMs), including SAPM-E for the encoder and SAPM-D for the decoder, to largely reduce the energy consumption. To be specific, they can be taken as plug-and-play components to upgrade existing CNN-based architectures, where the shift branch is used to extract large-grained features as compared to small-grained features learned by the addition branch. Furthermore, we thoroughly analyze the probability distribution of latent representations and propose to use Laplace Mixture Likelihoods for more accurate entropy estimation. Experimental results demonstrate that the proposed methods can achieve comparable or even better performance on both PSNR and MS-SSIM metrics to that of the convolutional counterpart with an about 2x energy reduction.