 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-Compression: How the Compression Error of Experts Affects the Inference Accuracy of MoE Model?
Sep 09, 2025With the widespread application of Mixture of Experts (MoE) reasoning models in the field of LLM learning, efficiently serving MoE models under limited GPU memory constraints has emerged as a significant challenge. Offloading the non-activated experts to main memory has been identified as an efficient approach to address such a problem, while it brings the challenges of transferring the expert between the GPU memory and main memory. We need to explore an efficient approach to compress the expert and analyze how the compression error affects the inference performance. To bridge this gap, we propose employing error-bounded lossy compression algorithms (such as SZ3 and CuSZp) to compress non-activated experts, thereby reducing data transfer overhead during MoE inference. We conduct extensive experiments across various benchmarks and present a comprehensive analysis of how compression-induced errors in different experts affect overall inference accuracy. The results indicate that experts in the shallow layers, which are primarily responsible for the attention mechanism and the transformation of input tokens into vector representations, exhibit minimal degradation in inference accuracy when subjected to bounded errors. In contrast, errors in the middle-layer experts, which are central to model reasoning, significantly impair inference accuracy. Interestingly, introducing bounded errors in the deep-layer experts, which are mainly responsible for instruction following and output integration, can sometimes lead to improvements in inference accuracy.
CLLoRA: An Approach to Measure the Effects of the Context Length for LLM Fine-Tuning
Feb 26, 2025Large language model fine-tuning has been identified as an efficient approach to applying the pre-trained Large language models to other domains. To guarantee data privacy for different data owners, models are often fine-tuned in federated learning environments across different data owners, which often involve data heterogeneity issues and affect the fine-tuning performance. In addition, the length of the context for the training data has been identified as a major factor that affects the LLM's model performance. To efficiently measure how the context length affects the LLM's model performance in heterogeneous federated learning environments, we propose CLLoRA. CLLoRA utilizes the parameter-efficient fine-tuning approach LoRA based on different kinds of LLMs with varying sizes as the fine-tuning approach to investigate whether the quality and length of contexts can serve as standards for measuring non-IID context. The findings indicate that an imbalance in context quality not only affects local training on clients but also impacts the global model's performance. However, context length has a minimal effect on local training but a more significant influence on the global model. These results provide insights into how context quality and length affect the model performance for LLM fine-tuning in federated learning environments.
FedFa: A Fully Asynchronous Training Paradigm for Federated Learning
Apr 17, 2024
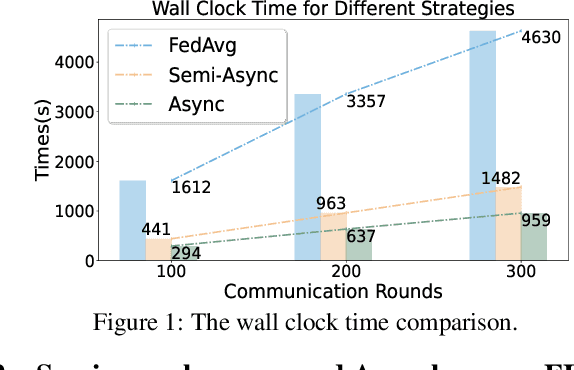
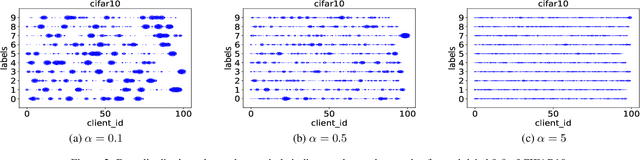
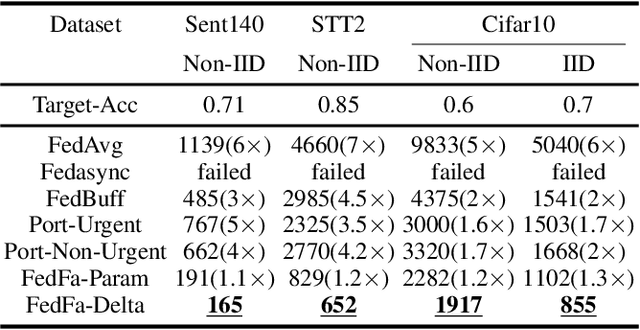
Federated learning has been identified as an efficient decentralized training paradigm for scaling the machine learning model training on a large number of devices while guaranteeing the data privacy of the trainers. FedAvg has become a foundational parameter update strategy for federated learning, which has been promising to eliminate the effect of the heterogeneous data across clients and guarantee convergence. However, the synchronization parameter update barriers for each communication round during the training significant time on waiting, slowing down the training procedure. Therefore, recent state-of-the-art solutions propose using semi-asynchronous approaches to mitigate the waiting time cost with guaranteed convergence. Nevertheless, emerging semi-asynchronous approaches are unable to eliminate the waiting time completely. We propose a full asynchronous training paradigm, called FedFa, which can guarantee model convergence and eliminate the waiting time completely for federated learning by using a few buffered results on the server for parameter updating. Further, we provide theoretical proof of the convergence rate for our proposed FedFa. Extensive experimental results indicate our approach effectively improves the training performance of federated learning by up to 6x and 4x speedup compared to the state-of-the-art synchronous and semi-asynchronous strategies while retaining high accuracy in both IID and Non-IID scenarios.