 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Learning-Based Inter Prediction for Future Video Coding
Nov 24, 2024



In the fourth generation Audio Video coding Standard (AVS4), the Inter Prediction Filter (INTERPF) reduces discontinuities between prediction and adjacent reconstructed pixels in inter prediction. The paper proposes a low complexity learning-based inter prediction (LLIP) method to replace the traditional INTERPF. LLIP enhances the filtering process by leveraging a lightweight neural network model, where parameters can be exported for efficient inference. Specifically, we extract pixels and coordinates utilized by the traditional INTERPF to form the training dataset. Subsequently, we export the weights and biases of the trained neural network model and implement the inference process without any third-party dependency, enabling seamless integration into video codec without relying on Libtorch, thus achieving faster inference speed. Ultimately, we replace the traditional handcraft filtering parameters in INTERPF with the learned optimal filtering parameters. This practical solution makes the combination of deep learning encoding tools with traditional video encoding schemes more efficient. Experimental results show that our approach achieves 0.01%, 0.31%, and 0.25% coding gain for the Y, U, and V components under the random access (RA) configuration on average.
A Neural-network Enhanced Video Coding Framework beyond ECM
Feb 21, 2024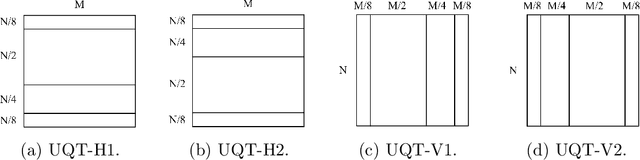

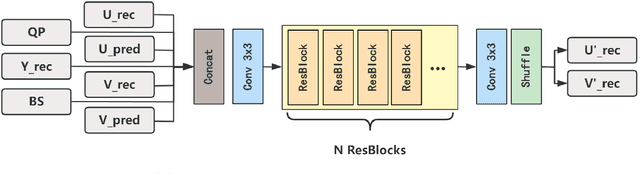
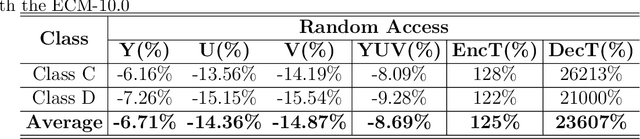
In this paper, a hybrid video compression framework is proposed that serves as a demonstrative showcase of deep learning-based approaches extending beyond the confines of traditional coding methodologies. The proposed hybrid framework is founded upon the Enhanced Compression Model (ECM), which is a further enhancement of the Versatile Video Coding (VVC) standard. We have augmented the latest ECM reference software with well-designed coding techniques, including block partitioning, deep learning-based loop filter, and the activation of block importance mapping (BIM) which was integrated but previously inactive within ECM, further enhancing coding performance. Compared with ECM-10.0, our method achieves 6.26, 13.33, and 12.33 BD-rate savings for the Y, U, and V components under random access (RA) configuration, respectively.