 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Perception-Driven Image Compression: A Layered Generative Approach
Apr 14, 2023
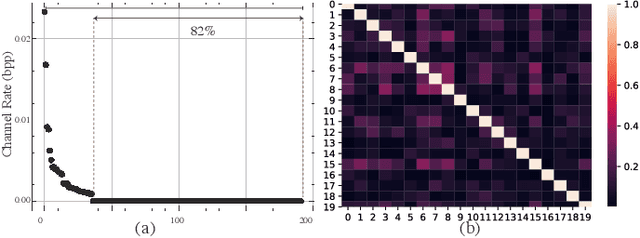


In this age of information, images are a critical medium for storing and transmitting information. With the rapid growth of image data amount, visual compression and visual data perception are two important research topics attracting a lot attention. However, those two topics are rarely discussed together and follow separate research path. Due to the compact compressed domain representation offered by learning-based image compression methods, there exists possibility to have one stream targeting both efficient data storage and compression, and machine perception tasks. In this paper, we propose a layered generative image compression model achieving high human vision-oriented image reconstructed quality, even at extreme compression ratios. To obtain analysis efficiency and flexibility, a task-agnostic learning-based compression model is proposed, which effectively supports various compressed domain-based analytical tasks while reserves outstanding reconstructed perceptual quality, compared with traditional and learning-based codecs. In addition, joint optimization schedule is adopted to acquire best balance point among compression ratio, reconstructed image quality, and downstream perception performance. Experimental results verify that our proposed compressed domain-based multi-task analysis method can achieve comparable analysis results against the RGB image-based methods with up to 99.6% bit rate saving (i.e., compared with taking original RGB image as the analysis model input). The practical ability of our model is further justified from model size and information fidelity aspects.