 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Third Eye! Benchmarking Privacy Awareness in MLLM-powered Smartphone Agents
Aug 27, 2025



Smartphones bring significant convenience to users but also enable devices to extensively record various types of personal information. Existing smartphone agents powered by Multimodal Large Language Models (MLLMs) have achieved remarkable performance in automating different tasks. However, as the cost, these agents are granted substantial access to sensitive users' personal information during this operation. To gain a thorough understanding of the privacy awareness of these agents, we present the first large-scale benchmark encompassing 7,138 scenarios to the best of our knowledge. In addition, for privacy context in scenarios, we annotate its type (e.g., Account Credentials), sensitivity level, and location. We then carefully benchmark seven available mainstream smartphone agents. Our results demonstrate that almost all benchmarked agents show unsatisfying privacy awareness (RA), with performance remaining below 60% even with explicit hints. Overall, closed-source agents show better privacy ability than open-source ones, and Gemini 2.0-flash achieves the best, achieving an RA of 67%. We also find that the agents' privacy detection capability is highly related to scenario sensitivity level, i.e., the scenario with a higher sensitivity level is typically more identifiable. We hope the findings enlighten the research community to rethink the unbalanced utility-privacy tradeoff about smartphone agents. Our code and benchmark are available at https://zhixin-l.github.io/SAPA-Bench.
RTV-Bench: Benchmarking MLLM Continuous Perception, Understanding and Reasoning through Real-Time Video
May 04, 2025Multimodal Large Language Models (MLLMs) increasingly excel at perception, understanding, and reasoning. However, current benchmarks inadequately evaluate their ability to perform these tasks continuously in dynamic, real-world environments. To bridge this gap, we introduce RTV-Bench, a fine-grained benchmark for MLLM real-time video analysis. RTV-Bench uses three key principles: (1) Multi-Timestamp Question Answering (MTQA), where answers evolve with scene changes; (2) Hierarchical Question Structure, combining basic and advanced queries; and (3) Multi-dimensional Evaluation, assessing the ability of continuous perception, understanding, and reasoning. RTV-Bench contains 552 diverse videos (167.2 hours) and 4,631 high-quality QA pairs. We evaluated leading MLLMs, including proprietary (GPT-4o, Gemini 2.0), open-source offline (Qwen2.5-VL, VideoLLaMA3), and open-source real-time (VITA-1.5, InternLM-XComposer2.5-OmniLive) models. Experiment results show open-source real-time models largely outperform offline ones but still trail top proprietary models. Our analysis also reveals that larger model size or higher frame sampling rates do not significantly boost RTV-Bench performance, sometimes causing slight decreases. This underscores the need for better model architectures optimized for video stream processing and long sequences to advance real-time video analysis with MLLMs. Our benchmark toolkit is available at: https://github.com/LJungang/RTV-Bench.
A Metropolis-Adjusted Langevin Algorithm for Sampling Jeffreys Prior
Apr 08, 2025Inference and estimation are fundamental aspects of statistics, system identification and machine learning. For most inference problems, prior knowledge is available on the system to be modeled, and Bayesian analysis is a natural framework to impose such prior information in the form of a prior distribution. However, in many situations, coming out with a fully specified prior distribution is not easy, as prior knowledge might be too vague, so practitioners prefer to use a prior distribution that is as `ignorant' or `uninformative' as possible, in the sense of not imposing subjective beliefs, while still supporting reliable statistical analysis. Jeffreys prior is an appealing uninformative prior because it offers two important benefits: (i) it is invariant under any re-parameterization of the model, (ii) it encodes the intrinsic geometric structure of the parameter space through the Fisher information matrix, which in turn enhances the diversity of parameter samples. Despite these benefits, drawing samples from Jeffreys prior is a challenging task. In this paper, we propose a general sampling scheme using the Metropolis-Adjusted Langevin Algorithm that enables sampling of parameter values from Jeffreys prior, and provide numerical illustrations of our approach through several examples.
Hierarchical B-frame Video Coding for Long Group of Pictures
Jun 24, 2024Learned video compression methods already outperform VVC in the low-delay (LD) case, but the random-access (RA) scenario remains challenging. Most works on learned RA video compression either use HEVC as an anchor or compare it to VVC in specific test conditions, using RGB-PSNR metric instead of Y-PSNR and avoiding comprehensive evaluation. Here, we present an end-to-end learned video codec for random access that combines training on long sequences of frames, rate allocation designed for hierarchical coding and content adaptation on inference. We show that under common test conditions (JVET-CTC), it achieves results comparable to VTM (VVC reference software) in terms of YUV-PSNR BD-Rate on some classes of videos, and outperforms it on almost all test sets in terms of VMAF BD-Rate. On average it surpasses open LD and RA end-to-end solutions in terms of VMAF and YUV BD-Rates.
High Visual-Fidelity Learned Video Compression
Oct 07, 2023With the growing demand for video applications, many advanced learned video compression methods have been developed, outperforming traditional methods in terms of objective quality metrics such as PSNR. Existing methods primarily focus on objective quality but tend to overlook perceptual quality. Directly incorporating perceptual loss into a learned video compression framework is nontrivial and raises several perceptual quality issues that need to be addressed. In this paper, we investigated these issues in learned video compression and propose a novel High Visual-Fidelity Learned Video Compression framework (HVFVC). Specifically, we design a novel confidence-based feature reconstruction method to address the issue of poor reconstruction in newly-emerged regions, which significantly improves the visual quality of the reconstruction. Furthermore, we present a periodic compensation loss to mitigate the checkerboard artifacts related to deconvolution operation and optimization. Extensive experiments have shown that the proposed HVFVC achieves excellent perceptual quality, outperforming the latest VVC standard with only 50% required bitrate.
Content-oriented learned image compression
Aug 01, 2022
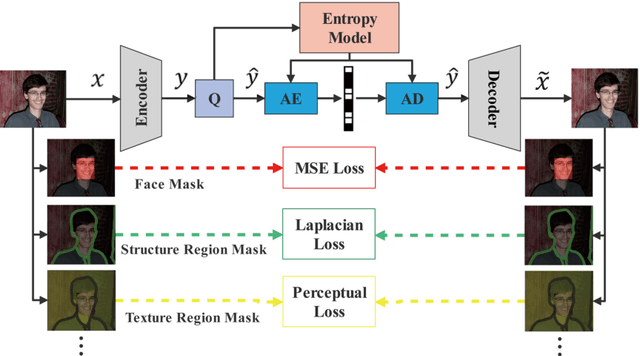
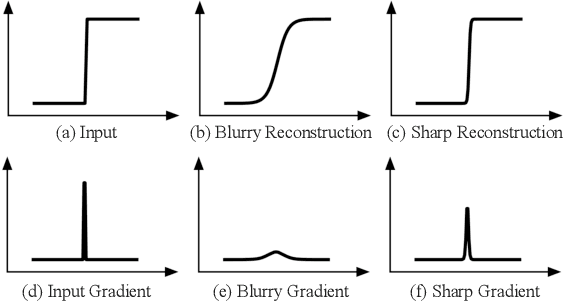
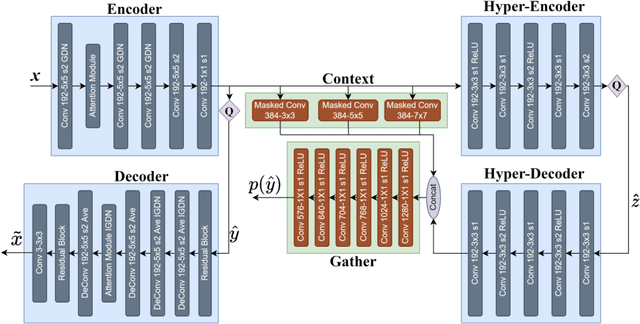
In recent years, with the development of deep neural networks, end-to-end optimized image compression has made significant progress and exceeded the classic methods in terms of rate-distortion performance. However, most learning-based image compression methods are unlabeled and do not consider image semantics or content when optimizing the model. In fact, human eyes have different sensitivities to different content, so the image content also needs to be considered. In this paper, we propose a content-oriented image compression method, which handles different kinds of image contents with different strategies. Extensive experiments show that the proposed method achieves competitive subjective results compared with state-of-the-art end-to-end learned image compression methods or classic methods.
AlphaVC: High-Performance and Efficient Learned Video Compression
Jul 29, 2022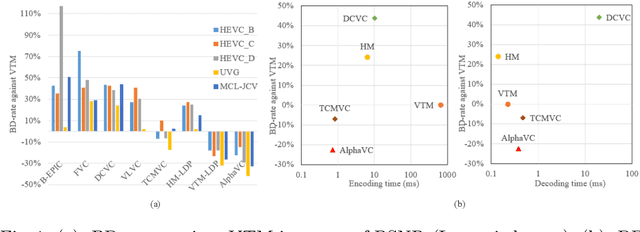
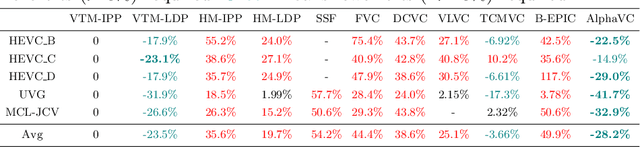
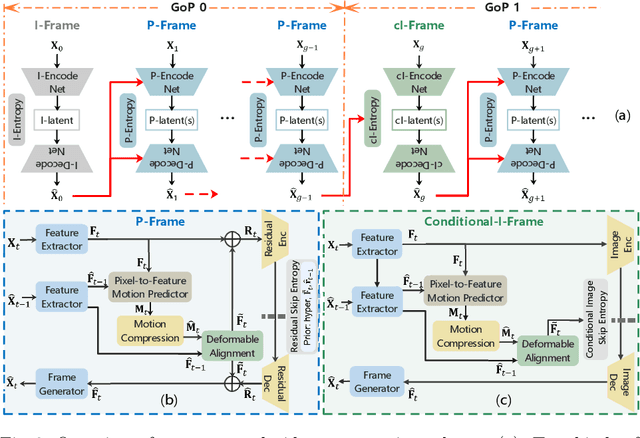
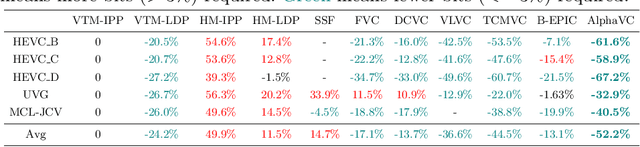
Recently, learned video compression has drawn lots of attention and show a rapid development trend with promising results. However, the previous works still suffer from some criticial issues and have a performance gap with traditional compression standards in terms of widely used PSNR metric. In this paper, we propose several techniques to effectively improve the performance. First, to address the problem of accumulative error, we introduce a conditional-I-frame as the first frame in the GoP, which stabilizes the reconstructed quality and saves the bit-rate. Second, to efficiently improve the accuracy of inter prediction without increasing the complexity of decoder, we propose a pixel-to-feature motion prediction method at encoder side that helps us to obtain high-quality motion information. Third, we propose a probability-based entropy skipping method, which not only brings performance gain, but also greatly reduces the runtime of entropy coding. With these powerful techniques, this paper proposes AlphaVC, a high-performance and efficient learned video compression scheme. To the best of our knowledge, AlphaVC is the first E2E AI codec that exceeds the latest compression standard VVC on all common test datasets for both PSNR (-28.2% BD-rate saving) and MSSSIM (-52.2% BD-rate saving), and has very fast encoding (0.001x VVC) and decoding (1.69x VVC) speeds.