 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Perspective on Privacy Protection in Federated Learning with Granular-Ball Computing
Jan 09, 2025Federated Learning (FL) facilitates collaborative model training while prioritizing privacy by avoiding direct data sharing. However, most existing articles attempt to address challenges within the model's internal parameters and corresponding outputs, while neglecting to solve them at the input level. To address this gap, we propose a novel framework called Granular-Ball Federated Learning (GrBFL) for image classification. GrBFL diverges from traditional methods that rely on the finest-grained input data. Instead, it segments images into multiple regions with optimal coarse granularity, which are then reconstructed into a graph structure. We designed a two-dimensional binary search segmentation algorithm based on variance constraints for GrBFL, which effectively removes redundant information while preserving key representative features. Extensive theoretical analysis and experiments demonstrate that GrBFL not only safeguards privacy and enhances efficiency but also maintains robust utility, consistently outperforming other state-of-the-art FL methods. The code is available at https://github.com/AIGNLAI/GrBFL.
Content-oriented learned image compression
Aug 01, 2022
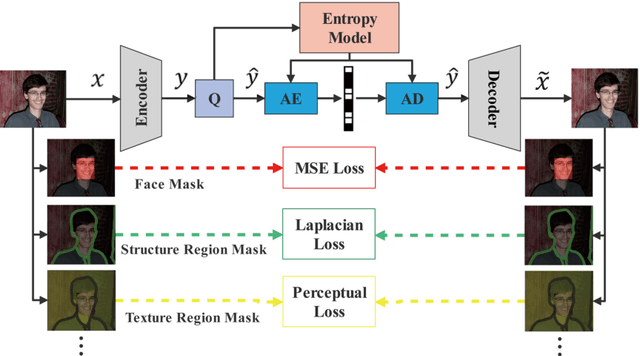
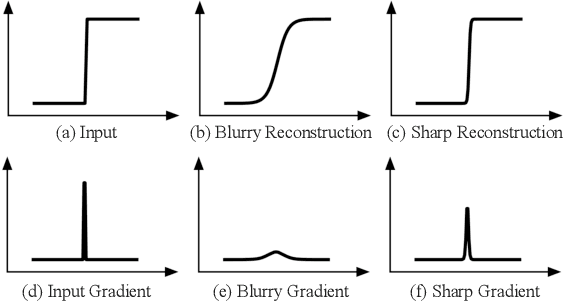
In recent years, with the development of deep neural networks, end-to-end optimized image compression has made significant progress and exceeded the classic methods in terms of rate-distortion performance. However, most learning-based image compression methods are unlabeled and do not consider image semantics or content when optimizing the model. In fact, human eyes have different sensitivities to different content, so the image content also needs to be considered. In this paper, we propose a content-oriented image compression method, which handles different kinds of image contents with different strategies. Extensive experiments show that the proposed method achieves competitive subjective results compared with state-of-the-art end-to-end learned image compression methods or classic methods.
G-VAE: A Continuously Variable Rate Deep Image Compression Framework
Mar 04, 2020

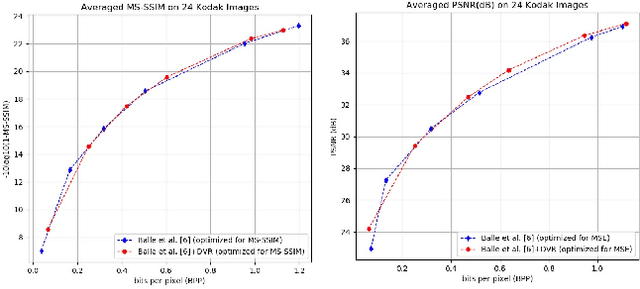
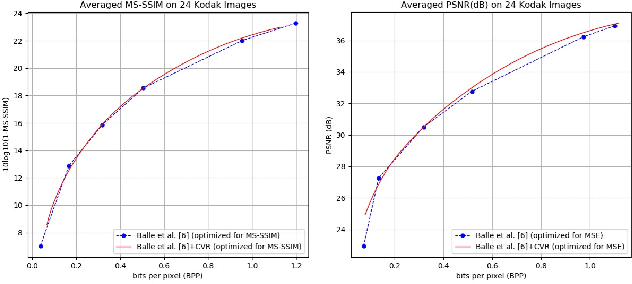
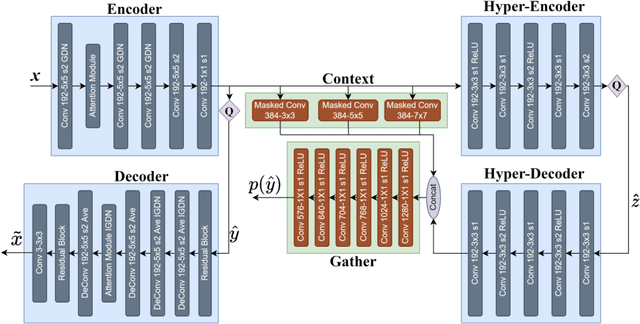
Rate adaption of deep image compression in a single model will become one of the decisive factors competing with the classical image compression codecs. However, until now, there is no perfect solution that neither increases the computation nor affects the compression performance. In this paper, we propose a novel image compression framework G-VAE (Gained Variational Autoencoder), which could achieve continuously variable rate in a single model. Unlike the previous solutions that encode progressively or change the internal unit of the network, G-VAE only adds a pair of gain units at the output of encoder and the input of decoder. It is so concise that G-VAE could be applied to almost all the image compression methods and achieve continuously variable rate with negligible additional parameters and computation. We also propose a new deep image compression framework, which outperforms all the published results on Kodak datasets in PSNR and MS-SSIM metrics. Experimental results show that adding a pair of gain units will not affect the performance of the basic models while endowing them with continuously variable rate.