 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevance Assessments for Web Search Evaluation: Should We Randomise or Prioritise the Pooled Documents? (CORRECTED VERSION)
Nov 02, 2022
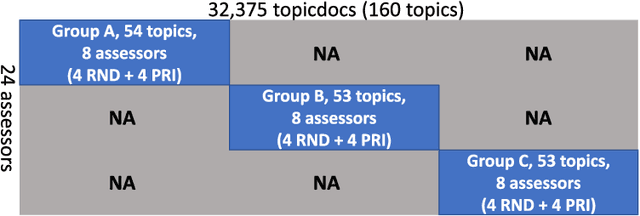

In the context of depth-$k$ pooling for constructing web search test collections, we compare two approaches to ordering pooled documents for relevance assessors: the prioritisation strategy (PRI) used widely at NTCIR, and the simple randomisation strategy (RND). In order to address research questions regarding PRI and RND, we have constructed and released the WWW3E8 data set, which contains eight independent relevance labels for 32,375 topic-document pairs, i.e., a total of 259,000 labels. Four of the eight relevance labels were obtained from PRI-based pools; the other four were obtained from RND-based pools. Using WWW3E8, we compare PRI and RND in terms of inter-assessor agreement, system ranking agreement, and robustness to new systems that did not contribute to the pools. We also utilise an assessor activity log we obtained as a byproduct of WWW3E8 to compare the two strategies in terms of assessment efficiency.
Corrected Evaluation Results of the NTCIR WWW-2, WWW-3, and WWW-4 English Subtasks
Oct 19, 2022



Unfortunately, the official English (sub)task results reported in the NTCIR-14 WWW-2, NTCIR-15 WWW-3, and NTCIR-16 WWW-4 overview papers are incorrect due to noise in the official qrels files; this paper reports results based on the corrected qrels files. The noise is due to a fatal bug in the backend of our relevance assessment interface. More specifically, at WWW-2, WWW-3, and WWW-4, two versions of pool files were created for each English topic: a PRI ("prioritised") file, which uses the NTCIRPOOL script to prioritise likely relevant documents, and a RND ("randomised") file, which randomises the pooled documents. This was done for the purpose of studying the effect of document ordering for relevance assessors. However, the programmer who wrote the interface backend assumed that a combination of a topic ID and a document rank in the pool file uniquely determines a document ID; this is obviously incorrect as we have two versions of pool files. The outcome is that all the PRI-based relevance labels for the WWW-2 test collection are incorrect (while all the RND-based relevance labels are correct), and all the RND-based relevance labels for the WWW-3 and WWW-4 test collections are incorrect (while all the PRI-based relevance labels are correct). This bug was finally discovered at the NTCIR-16 WWW-4 task when the first seven authors of this paper served as Gold assessors (i.e., topic creators who define what is relevant) and closely examined the disagreements with Bronze assessors (i.e., non-topic-creators; non-experts). We would like to apologise to the WWW participants and the NTCIR chairs for the inconvenience and confusion caused due to this bug.