 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevance Assessments for Web Search Evaluation: Should We Randomise or Prioritise the Pooled Documents? (CORRECTED VERSION)
Nov 02, 2022
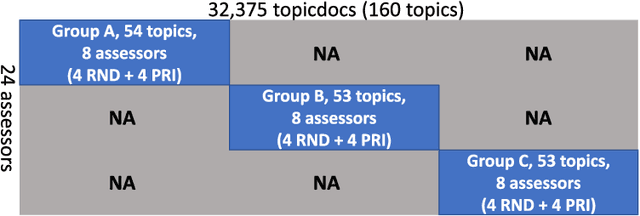

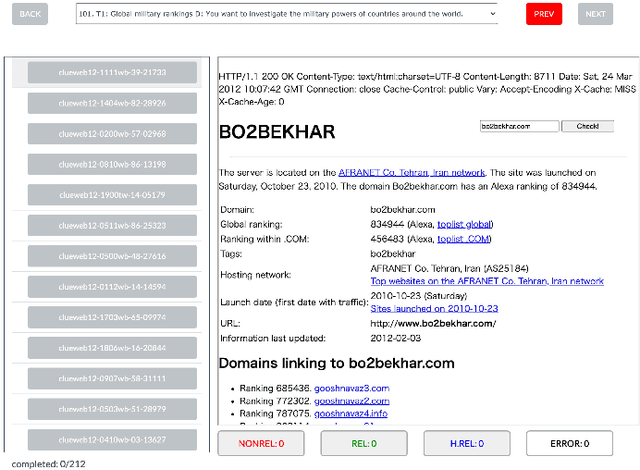
In the context of depth-$k$ pooling for constructing web search test collections, we compare two approaches to ordering pooled documents for relevance assessors: the prioritisation strategy (PRI) used widely at NTCIR, and the simple randomisation strategy (RND). In order to address research questions regarding PRI and RND, we have constructed and released the WWW3E8 data set, which contains eight independent relevance labels for 32,375 topic-document pairs, i.e., a total of 259,000 labels. Four of the eight relevance labels were obtained from PRI-based pools; the other four were obtained from RND-based pools. Using WWW3E8, we compare PRI and RND in terms of inter-assessor agreement, system ranking agreement, and robustness to new systems that did not contribute to the pools. We also utilise an assessor activity log we obtained as a byproduct of WWW3E8 to compare the two strategies in terms of assessment efficiency.
DCH-2: A Parallel Customer-Helpdesk Dialogue Corpus with Distributions of Annotators' Labels
Apr 18, 2021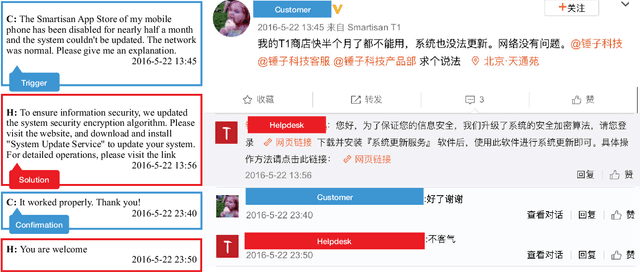
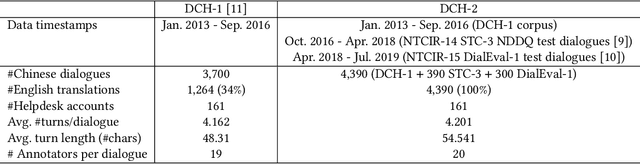

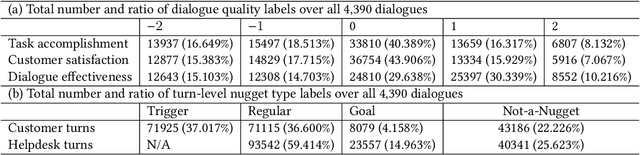
We introduce a data set called DCH-2, which contains 4,390 real customer-helpdesk dialogues in Chinese and their English translations. DCH-2 also contains dialogue-level annotations and turn-level annotations obtained independently from either 19 or 20 annotators. The data set was built through our effort as organisers of the NTCIR-14 Short Text Conversation and NTCIR-15 Dialogue Evaluation tasks, to help researchers understand what constitutes an effective customer-helpdesk dialogue, and thereby build efficient and helpful helpdesk systems that are available to customers at all times. In addition, DCH-2 may be utilised for other purposes, for example, as a repository for retrieval-based dialogue systems, or as a parallel corpus for machine translation in the helpdesk domain.