 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCH-2: A Parallel Customer-Helpdesk Dialogue Corpus with Distributions of Annotators' Labels
Paper and Code
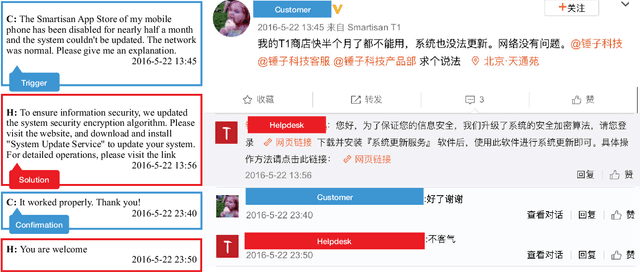
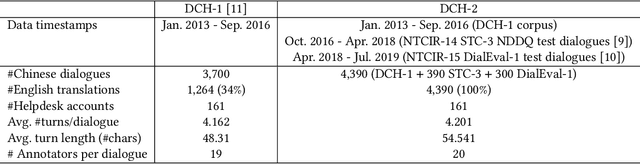

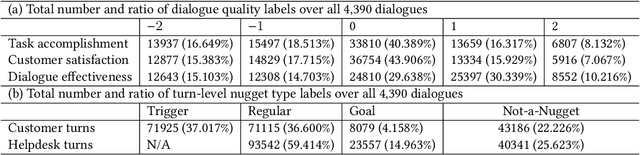
We introduce a data set called DCH-2, which contains 4,390 real customer-helpdesk dialogues in Chinese and their English translations. DCH-2 also contains dialogue-level annotations and turn-level annotations obtained independently from either 19 or 20 annotators. The data set was built through our effort as organisers of the NTCIR-14 Short Text Conversation and NTCIR-15 Dialogue Evaluation tasks, to help researchers understand what constitutes an effective customer-helpdesk dialogue, and thereby build efficient and helpful helpdesk systems that are available to customers at all times. In addition, DCH-2 may be utilised for other purposes, for example, as a repository for retrieval-based dialogue systems, or as a parallel corpus for machine translation in the helpdesk domain.