 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLM-as-a-Judge for Long-Form Output Evaluation
Jun 01, 2026As large language models (LLMs) are increasingly used for long-form generation, reliably evaluating long-form outputs has become a critical challenge. LLM-as-a-judge offers a scalable alternative to human evaluation, yet its reliability in long-form output evaluation remains underexamined: existing meta-evaluation benchmarks focus mainly on short-form outputs. Compared with short-form evaluation, long-form evaluation is not merely a matter of output length; it often requires judges to handle more complex document-level demands. In this work, we introduce LongJudgeBench, a comprehensive benchmark for evaluating LLM judges on long-form outputs across diverse real-world scenarios and judging protocols. We systematically evaluate a broad range of LLM judges, covering multiple base models and judging settings. Our results reveal a substantial reliability gap: current LLM judges remain unstable across scenarios, and rubrics or references are helpful but not always sufficient. We hope LongJudgeBench will support future research on more robust, context-aware, and human-aligned LLM-as-a-judge methods. Our code is available at https://anonymous.4open.science/r/LongJudgeBench-F782.
An Automatic and Cost-Efficient Peer-Review Framework for Language Generation Evaluation
Oct 16, 2024
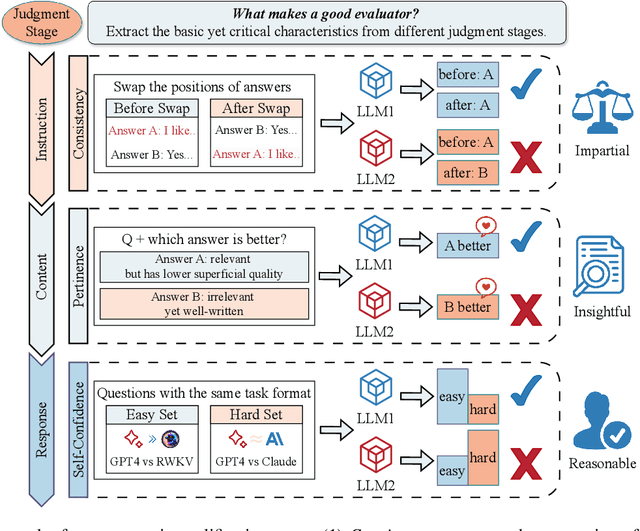

With the rapid development of large language models (LLMs), how to efficiently evaluate them has become an important research question. Existing evaluation methods often suffer from high costs, limited test formats, the need of human references, and systematic evaluation biases. To address these limitations, our study introduces the Auto-PRE, an automatic LLM evaluation framework based on peer review. In contrast to previous studies that rely on human annotations, Auto-PRE selects evaluator LLMs automatically based on their inherent traits including consistency, self-confidence, and pertinence. We conduct extensive experiments on three tasks: summary generation, non-factoid question-answering, and dialogue generation. Experimental results indicate our Auto-PRE achieves state-of-the-art performance at a lower cost. Moreover, our study highlights the impact of prompt strategies and evaluation formats on evaluation performance, offering guidance for method optimization in the future.