 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-OmniClaw Technical Report: A Unified Mobile Agent for Multimodal Understanding and Interaction
May 07, 2026Inspired by the development of OpenClaw, there is a growing demand for mobile-based personal agents capable of handling complex and intuitive interactions. In this technical report, we introduce X-OmniClaw, a unified mobile agent designed for multimodal understanding and interaction in the Android ecosystem. This unified architecture of perception, memory, and action enables the agent to handle complex mobile tasks with high contextual awareness. Specifically, Omni Perception provides a unified multimodal ingress pipeline that integrates UI states, real-world visual contexts, and speech inputs, leveraging a temporal alignment module to decompose raw data into structured multimodal intent representations. Omni Memory leverages multimodal memory optimization to enhance personalized intelligence by integrating runtime working memory for task continuity with long-term personal memory distilled from local data, enabling highly context-aware and personalized interactions. Finally, Omni Action employs a hybrid grounding strategy that combines structural XML metadata with visual perception for robust interaction. Through Behavior Cloning and Trajectory Replay, the system captures user navigation as reusable skills, enabling precise direct-access execution. Demonstrations across diverse scenarios show that X-OmniClaw effectively enhances interaction efficiency and task reliability, providing a practical architectural blueprint for the next generation of mobile-native personal assistants.
Improved Visual-Spatial Reasoning via R1-Zero-Like Training
Apr 01, 2025Increasing attention has been placed on improving the reasoning capacities of multi-modal large language models (MLLMs). As the cornerstone for AI agents that function in the physical realm, video-based visual-spatial intelligence (VSI) emerges as one of the most pivotal reasoning capabilities of MLLMs. This work conducts a first, in-depth study on improving the visual-spatial reasoning of MLLMs via R1-Zero-like training. Technically, we first identify that the visual-spatial reasoning capacities of small- to medium-sized Qwen2-VL models cannot be activated via Chain of Thought (CoT) prompts. We then incorporate GRPO training for improved visual-spatial reasoning, using the carefully curated VSI-100k dataset, following DeepSeek-R1-Zero. During the investigation, we identify the necessity to keep the KL penalty (even with a small value) in GRPO. With just 120 GPU hours, our vsGRPO-2B model, fine-tuned from Qwen2-VL-2B, can outperform the base model by 12.1% and surpass GPT-4o. Moreover, our vsGRPO-7B model, fine-tuned from Qwen2-VL-7B, achieves performance comparable to that of the best open-source model LLaVA-NeXT-Video-72B. Additionally, we compare vsGRPO to supervised fine-tuning and direct preference optimization baselines and observe strong performance superiority. The code and dataset will be available soon.
Show-o Turbo: Towards Accelerated Unified Multimodal Understanding and Generation
Feb 08, 2025There has been increasing research interest in building unified multimodal understanding and generation models, among which Show-o stands as a notable representative, demonstrating great promise for both text-to-image and image-to-text generation. The inference of Show-o involves progressively denoising image tokens and autoregressively decoding text tokens, and hence, unfortunately, suffers from inefficiency issues from both sides. This paper introduces Show-o Turbo to bridge the gap. We first identify a unified denoising perspective for the generation of images and text in Show-o based on the parallel decoding of text tokens. We then propose to extend consistency distillation (CD), a qualified approach for shortening the denoising process of diffusion models, to the multimodal denoising trajectories of Show-o. We introduce a trajectory segmentation strategy and a curriculum learning procedure to improve the training convergence. Empirically, in text-to-image generation, Show-o Turbo displays a GenEval score of 0.625 at 4 sampling steps without using classifier-free guidance (CFG), outperforming that of the original Show-o with 8 steps and CFG; in image-to-text generation, Show-o Turbo exhibits a 1.5x speedup without significantly sacrificing performance. The code is available at https://github.com/zhijie-group/Show-o-Turbo.
Fine-tuning Diffusion Models for Enhancing Face Quality in Text-to-image Generation
Jun 24, 2024



Diffusion models (DMs) have achieved significant success in generating imaginative images given textual descriptions. However, they are likely to fall short when it comes to real-life scenarios with intricate details.The low-quality, unrealistic human faces in text-to-image generation are one of the most prominent issues, hindering the wide application of DMs in practice. Targeting addressing such an issue, we first assess the face quality of generations from popular pre-trained DMs with the aid of human annotators and then evaluate the alignment between existing metrics such as ImageReward, Human Preference Score, Aesthetic Score Predictor, and Face Quality Assessment, with human judgments. Observing that existing metrics can be unsatisfactory for quantifying face quality, we develop a novel metric named Face Score (FS) by fine-tuning ImageReward on a dataset of (good, bad) face pairs cheaply crafted by an inpainting pipeline of DMs. Extensive studies reveal that FS enjoys a superior alignment with humans. On the other hand, FS opens up the door for refining DMs for better face generation. To achieve this, we incorporate a guidance loss on the denoising trajectories of the aforementioned face pairs for fine-tuning pre-trained DMs such as Stable Diffusion V1.5 and Realistic Vision V5.1. Intuitively, such a loss pushes the trajectory of bad faces toward that of good ones. Comprehensive experiments verify the efficacy of our approach for improving face quality while preserving general capability.
MLCM: Multistep Consistency Distillation of Latent Diffusion Model
Jun 12, 2024



Distilling large latent diffusion models (LDMs) into ones that are fast to sample from is attracting growing research interest. However, the majority of existing methods face a dilemma where they either (i) depend on multiple individual distilled models for different sampling budgets, or (ii) sacrifice generation quality with limited (e.g., 2-4) and/or moderate (e.g., 5-8) sampling steps. To address these, we extend the recent multistep consistency distillation (MCD) strategy to representative LDMs, establishing the Multistep Latent Consistency Models (MLCMs) approach for low-cost high-quality image synthesis. MLCM serves as a unified model for various sampling steps due to the promise of MCD. We further augment MCD with a progressive training strategy to strengthen inter-segment consistency to boost the quality of few-step generations. We take the states from the sampling trajectories of the teacher model as training data for MLCMs to lift the requirements for high-quality training datasets and to bridge the gap between the training and inference of the distilled model. MLCM is compatible with preference learning strategies for further improvement of visual quality and aesthetic appeal. Empirically, MLCM can generate high-quality, delightful images with only 2-8 sampling steps. On the MSCOCO-2017 5K benchmark, MLCM distilled from SDXL gets a CLIP Score of 33.30, Aesthetic Score of 6.19, and Image Reward of 1.20 with only 4 steps, substantially surpassing 4-step LCM [23], 8-step SDXL-Lightning [17], and 8-step HyperSD [33]. We also demonstrate the versatility of MLCMs in applications including controllable generation, image style transfer, and Chinese-to-image generation.
LOVECon: Text-driven Training-Free Long Video Editing with ControlNet
Oct 15, 2023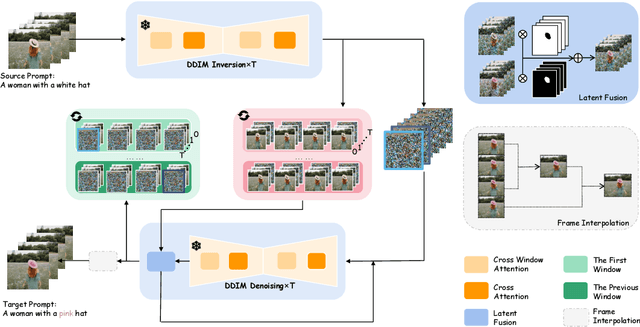
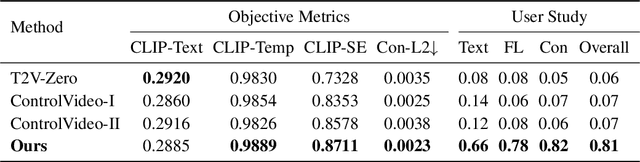


Leveraging pre-trained conditional diffusion models for video editing without further tuning has gained increasing attention due to its promise in film production, advertising, etc. Yet, seminal works in this line fall short in generation length, temporal coherence, or fidelity to the source video. This paper aims to bridge the gap, establishing a simple and effective baseline for training-free diffusion model-based long video editing. As suggested by prior arts, we build the pipeline upon ControlNet, which excels at various image editing tasks based on text prompts. To break down the length constraints caused by limited computational memory, we split the long video into consecutive windows and develop a novel cross-window attention mechanism to ensure the consistency of global style and maximize the smoothness among windows. To achieve more accurate control, we extract the information from the source video via DDIM inversion and integrate the outcomes into the latent states of the generations. We also incorporate a video frame interpolation model to mitigate the frame-level flickering issue. Extensive empirical studies verify the superior efficacy of our method over competing baselines across scenarios, including the replacement of the attributes of foreground objects, style transfer, and background replacement. In particular, our method manages to edit videos with up to 128 frames according to user requirements. Code is available at https://github.com/zhijie-group/LOVECon.