 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoPA: Scaling dLLM Inference via Lookahead Parallel Decoding
Dec 22, 2025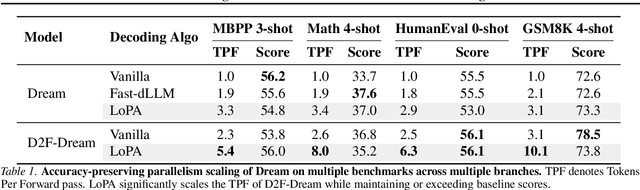
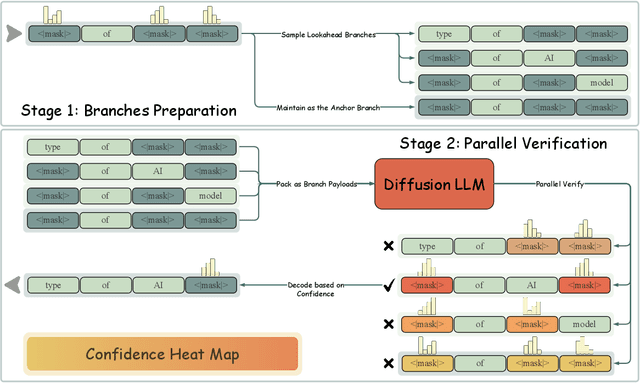
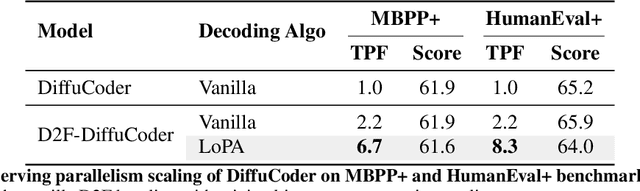
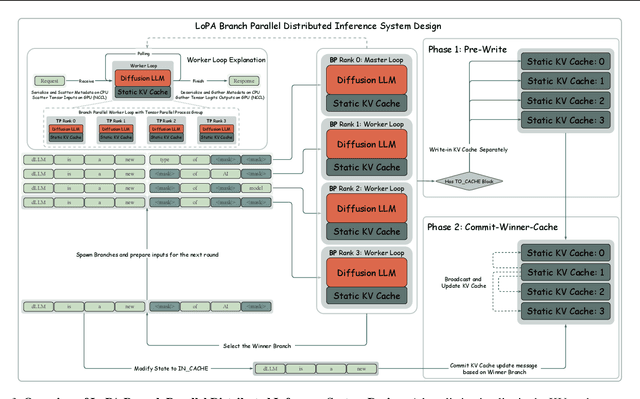
Diffusion Large Language Models (dLLMs) have demonstrated significant potential for high-speed inference. However, current confidence-driven decoding strategies are constrained by limited parallelism, typically achieving only 1--3 tokens per forward pass (TPF). In this work, we identify that the degree of parallelism during dLLM inference is highly sensitive to the Token Filling Order (TFO). Then, we introduce Lookahead PArallel Decoding LoPA, a training-free, plug-and-play algorithm, to identify a superior TFO and hence accelerate inference. LoPA concurrently explores distinct candidate TFOs via parallel branches, and selects the one with the highest potential for future parallelism based on branch confidence. We apply LoPA to the state-of-the-art D2F model and observe a substantial enhancement in decoding efficiency. Notably, LoPA increases the TPF of D2F-Dream to 10.1 on the GSM8K while maintaining performance superior to the Dream baseline. Furthermore, to facilitate this unprecedented degree of parallelism, we develop a specialized multi-device inference system featuring Branch Parallelism (BP), which achieves a single-sample throughput of 1073.9 tokens per second under multi-GPU deployment. The code is available at https://github.com/zhijie-group/LoPA.
Show-o Turbo: Towards Accelerated Unified Multimodal Understanding and Generation
Feb 08, 2025There has been increasing research interest in building unified multimodal understanding and generation models, among which Show-o stands as a notable representative, demonstrating great promise for both text-to-image and image-to-text generation. The inference of Show-o involves progressively denoising image tokens and autoregressively decoding text tokens, and hence, unfortunately, suffers from inefficiency issues from both sides. This paper introduces Show-o Turbo to bridge the gap. We first identify a unified denoising perspective for the generation of images and text in Show-o based on the parallel decoding of text tokens. We then propose to extend consistency distillation (CD), a qualified approach for shortening the denoising process of diffusion models, to the multimodal denoising trajectories of Show-o. We introduce a trajectory segmentation strategy and a curriculum learning procedure to improve the training convergence. Empirically, in text-to-image generation, Show-o Turbo displays a GenEval score of 0.625 at 4 sampling steps without using classifier-free guidance (CFG), outperforming that of the original Show-o with 8 steps and CFG; in image-to-text generation, Show-o Turbo exhibits a 1.5x speedup without significantly sacrificing performance. The code is available at https://github.com/zhijie-group/Show-o-Turbo.
High-Dimensional Data Set Simplification by Laplace-Beltrami Operator
Mar 23, 2020
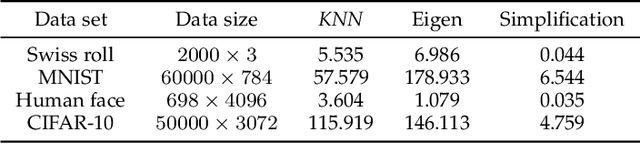

With the development of the Internet and other digital technologies, the speed of data generation has become considerably faster than the speed of data processing. Because big data typically contain massive redundant information, it is possible to significantly simplify a big data set while maintaining the key information it contains. In this paper, we develop a big data simplification method based on the eigenvalues and eigenfunctions of the Laplace-Beltrami operator (LBO). Specifically, given a data set that can be considered as an unorganized data point set in high-dimensional space, a discrete LBO defined on the big data set is constructed and its eigenvalues and eigenvectors are calculated. Then, the local extremum and the saddle points of the eigenfunctions are proposed to be the feature points of a data set in high-dimensional space, constituting a simplified data set. Moreover, we develop feature point detection methods for the functions defined on an unorganized data point set in high-dimensional space, and devise metrics for measuring the fidelity of the simplified data set to the original set. Finally, examples and applications are demonstrated to validate the efficiency and effectiveness of the proposed methods, demonstrating that data set simplification is a method for processing a maximum-sized data set using a limited data processing capability.