 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric Visual Self-Modeling for Legged Robot Locomotion
Paper and Code
Jul 07, 2022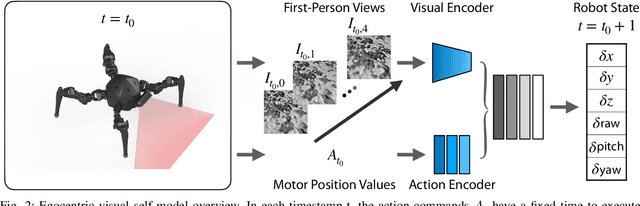

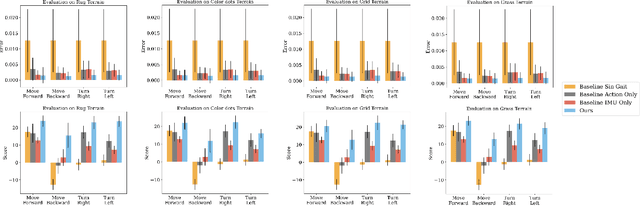

Inertial Measurement Unit (IMU) is ubiquitous in robotic research. It provides posture information for robots to realize balance and navigation. However, humans and animals can perceive the movement of their bodies in the environment without precise orientation or position values. This interaction inherently involves a fast feedback loop between perception and action. This work proposed an end-to-end approach that uses high dimension visual observation and action commands to train a visual self-model for legged locomotion. The visual self-model learns the spatial relationship between the robot body movement and the ground texture changes from image sequences. We demonstrate that the robot can leverage the visual self-model to achieve various locomotion tasks in the real-world environment that the robot does not see during training. With our proposed method, robots can do locomotion without IMU or in an environment with no GPS or weak geomagnetic fields like the indoor and urban canyons in the city.