 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Mitigating Code LLM Hallucinations with API Documentation
Jul 13, 2024



In this study, we address the issue of API hallucinations in various software engineering contexts. We introduce CloudAPIBench, a new benchmark designed to measure API hallucination occurrences. CloudAPIBench also provides annotations for frequencies of API occurrences in the public domain, allowing us to study API hallucinations at various frequency levels. Our findings reveal that Code LLMs struggle with low frequency APIs: for e.g., GPT-4o achieves only 38.58% valid low frequency API invocations. We demonstrate that Documentation Augmented Generation (DAG) significantly improves performance for low frequency APIs (increase to 47.94% with DAG) but negatively impacts high frequency APIs when using sub-optimal retrievers (a 39.02% absolute drop). To mitigate this, we propose to intelligently trigger DAG where we check against an API index or leverage Code LLMs' confidence scores to retrieve only when needed. We demonstrate that our proposed methods enhance the balance between low and high frequency API performance, resulting in more reliable API invocations (8.20% absolute improvement on CloudAPIBench for GPT-4o).
On the Origins of Self-Modeling
Sep 05, 2022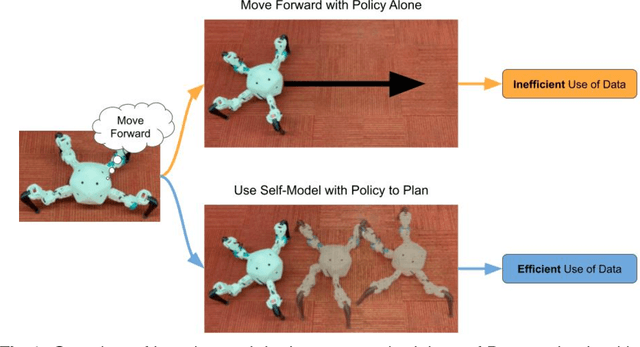
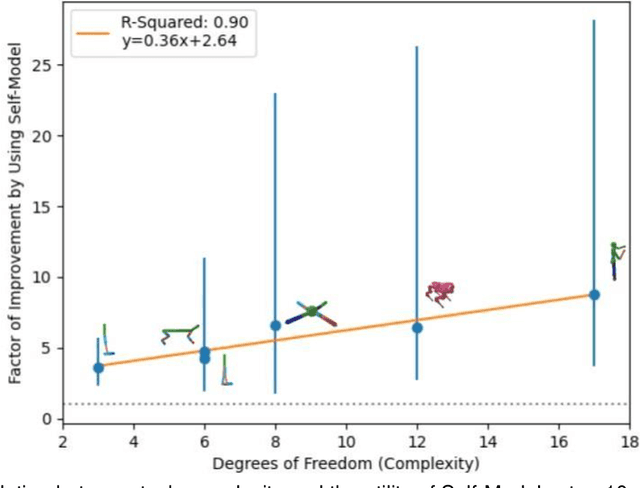

Self-Modeling is the process by which an agent, such as an animal or machine, learns to create a predictive model of its own dynamics. Once captured, this self-model can then allow the agent to plan and evaluate various potential behaviors internally using the self-model, rather than using costly physical experimentation. Here, we quantify the benefits of such self-modeling against the complexity of the robot. We find a R2 =0.90 correlation between the number of degrees of freedom a robot has, and the added value of self-modeling as compared to a direct learning baseline. This result may help motivate self modeling in increasingly complex robotic systems, as well as shed light on the origins of self-modeling, and ultimately self-awareness, in animals and humans.
Full-Body Visual Self-Modeling of Robot Morphologies
Nov 21, 2021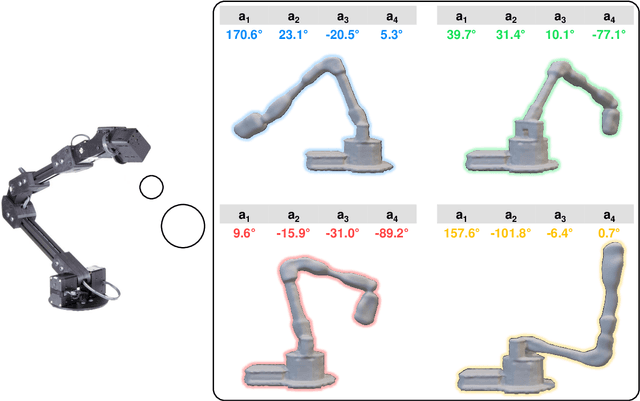
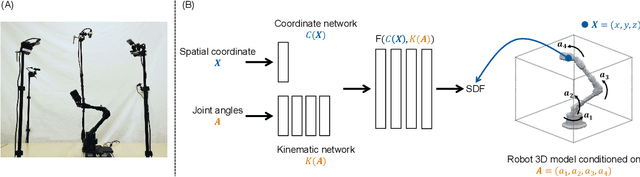
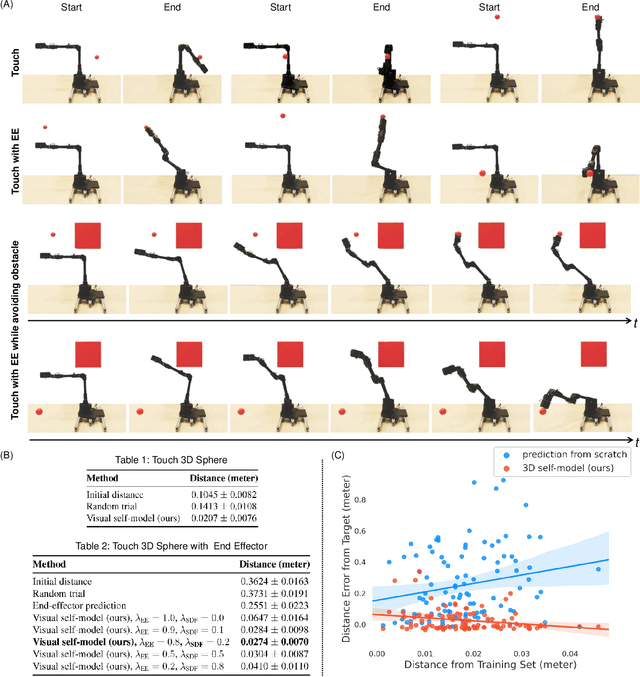

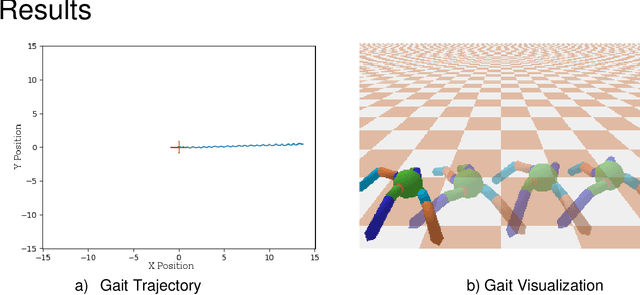
Internal computational models of physical bodies are fundamental to the ability of robots and animals alike to plan and control their actions. These "self-models" allow robots to consider outcomes of multiple possible future actions, without trying them out in physical reality. Recent progress in fully data-driven self-modeling has enabled machines to learn their own forward kinematics directly from task-agnostic interaction data. However, forward-kinema\-tics models can only predict limited aspects of the morphology, such as the position of end effectors or velocity of joints and masses. A key challenge is to model the entire morphology and kinematics, without prior knowledge of what aspects of the morphology will be relevant to future tasks. Here, we propose that instead of directly modeling forward-kinematics, a more useful form of self-modeling is one that could answer space occupancy queries, conditioned on the robot's state. Such query-driven self models are continuous in the spatial domain, memory efficient, fully differentiable and kinematic aware. In physical experiments, we demonstrate how a visual self-model is accurate to about one percent of the workspace, enabling the robot to perform various motion planning and control tasks. Visual self-modeling can also allow the robot to detect, localize and recover from real-world damage, leading to improved machine resiliency. Our project website is at: https://robot-morphology.cs.columbia.edu/
Visual Perspective Taking for Opponent Behavior Modeling
May 11, 2021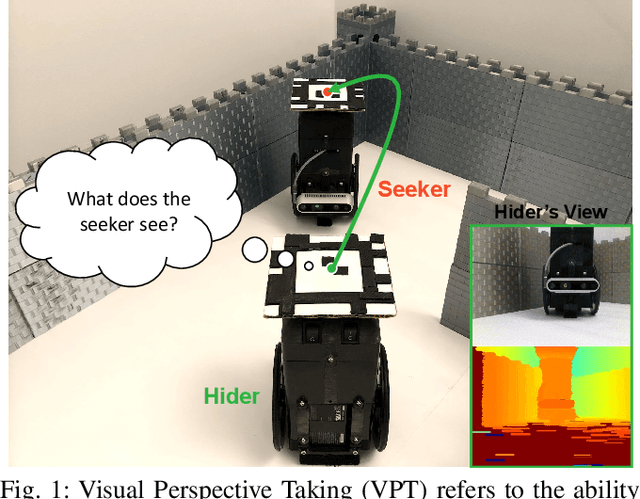
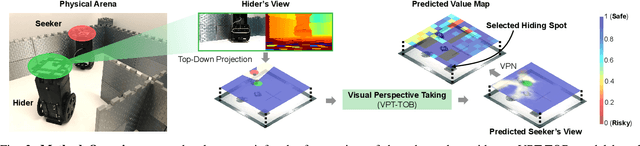
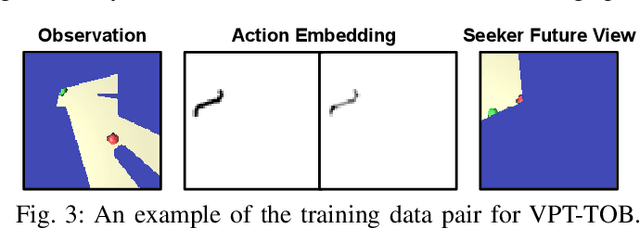
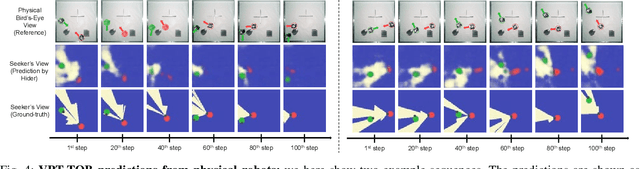
In order to engage in complex social interaction, humans learn at a young age to infer what others see and cannot see from a different point-of-view, and learn to predict others' plans and behaviors. These abilities have been mostly lacking in robots, sometimes making them appear awkward and socially inept. Here we propose an end-to-end long-term visual prediction framework for robots to begin to acquire both these critical cognitive skills, known as Visual Perspective Taking (VPT) and Theory of Behavior (TOB). We demonstrate our approach in the context of visual hide-and-seek - a game that represents a cognitive milestone in human development. Unlike traditional visual predictive model that generates new frames from immediate past frames, our agent can directly predict to multiple future timestamps (25s), extrapolating by 175% beyond the training horizon. We suggest that visual behavior modeling and perspective taking skills will play a critical role in the ability of physical robots to fully integrate into real-world multi-agent activities. Our website is at http://www.cs.columbia.edu/~bchen/vpttob/.
Zero Shot Learning on Simulated Robots
Oct 04, 2019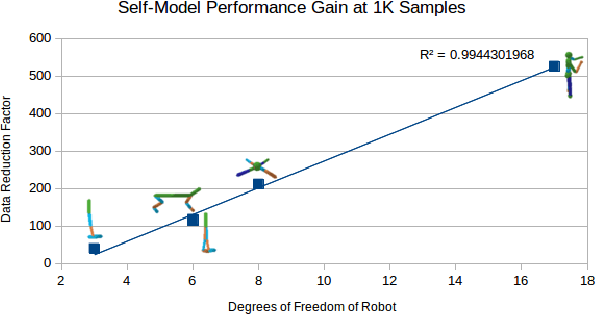
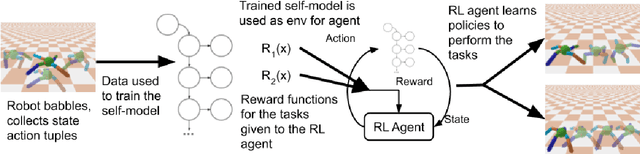
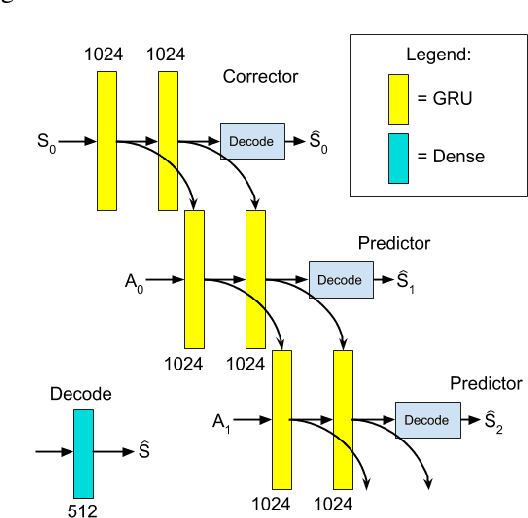
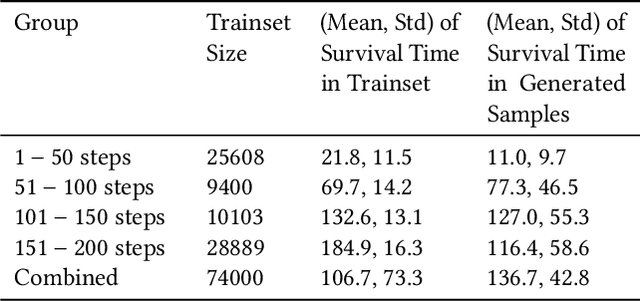
In this work we present a method for leveraging data from one source to learn how to do multiple new tasks. Task transfer is achieved using a self-model that encapsulates the dynamics of a system and serves as an environment for reinforcement learning. To study this approach, we train a self-models on various robot morphologies, using randomly sampled actions. Using a self-model, an initial state and corresponding actions, we can predict the next state. This predictive self-model is then used by a standard reinforcement learning algorithm to accomplish tasks without ever seeing a state from the "real" environment. These trained policies allow the robots to successfully achieve their goals in the "real" environment. We demonstrate that not only is training on the self-model far more data efficient than learning even a single task, but also that it allows for learning new tasks without necessitating any additional data collection, essentially allowing zero-shot learning of new tasks.
Agent Embeddings: A Latent Representation for Pole-Balancing Networks
Nov 12, 2018
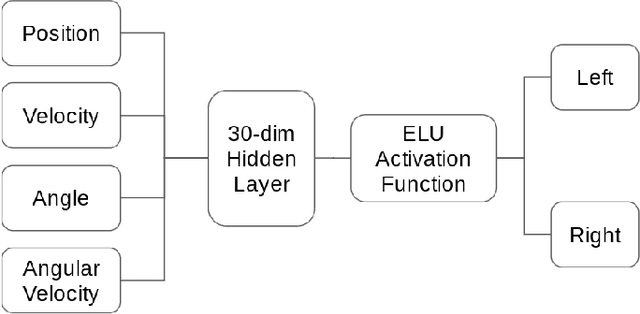

We show that it is possible to reduce a high-dimensional object like a neural network agent into a low-dimensional vector representation with semantic meaning that we call agent embeddings, akin to word or face embeddings. This can be done by collecting examples of existing networks, vectorizing their weights, and then learning a generative model over the weight space in a supervised fashion. We investigate a pole-balancing task, Cart-Pole, as a case study and show that multiple new pole-balancing networks can be generated from their agent embeddings without direct access to training data from the Cart-Pole simulator. In general, the learned embedding space is helpful for mapping out the space of solutions for a given task. We observe in the case of Cart-Pole the surprising finding that good agents make different decisions despite learning similar representations, whereas bad agents make similar (bad) decisions while learning dissimilar representations. Linearly interpolating between the latent embeddings for a good agent and a bad agent yields an agent embedding that generates a network with intermediate performance, where the performance can be tuned according to the coefficient of interpolation. Linear extrapolation in the latent space also results in performance boosts, up to a point.
Gradient Normalization & Depth Based Decay For Deep Learning
Feb 28, 2018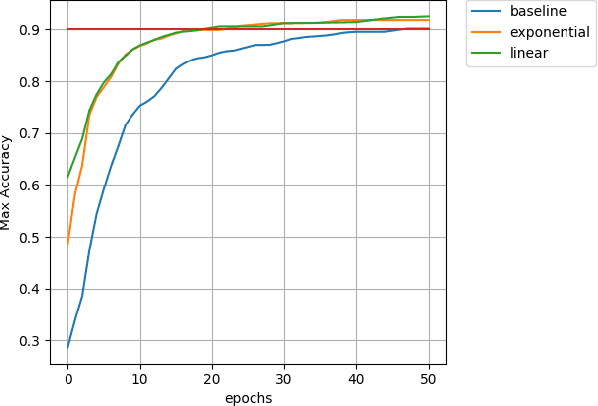
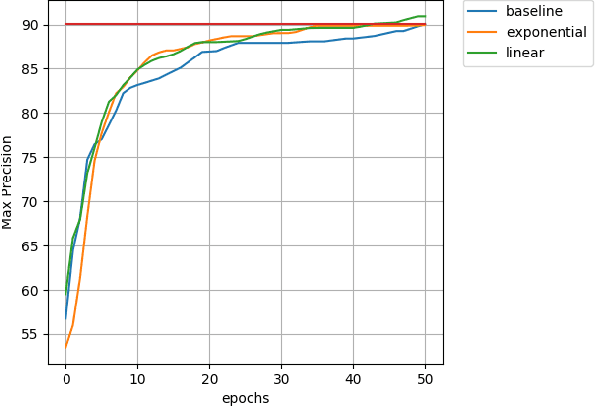
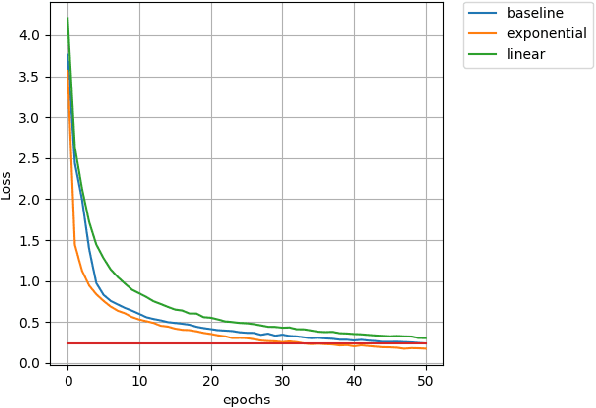
In this paper we introduce a novel method of gradient normalization and decay with respect to depth. Our method leverages the simple concept of normalizing all gradients in a deep neural network, and then decaying said gradients with respect to their depth in the network. Our proposed normalization and decay techniques can be used in conjunction with most current state of the art optimizers and are a very simple addition to any network. This method, although simple, showed improvements in convergence time on state of the art networks such as DenseNet and ResNet on image classification tasks, as well as on an LSTM for natural language processing tasks.