Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Normalization & Depth Based Decay For Deep Learning
Paper and Code
Feb 28, 2018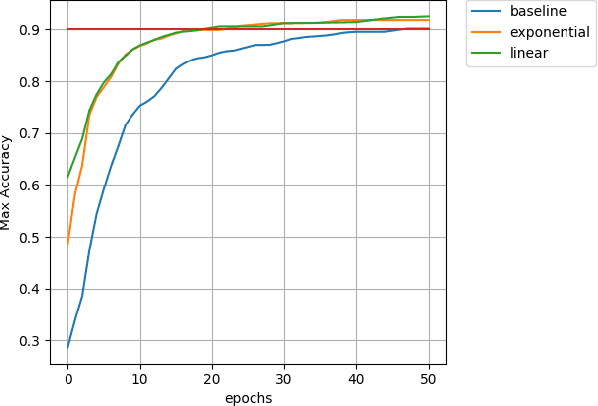
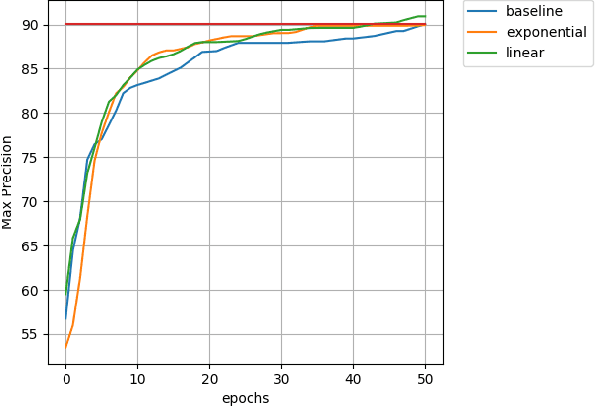
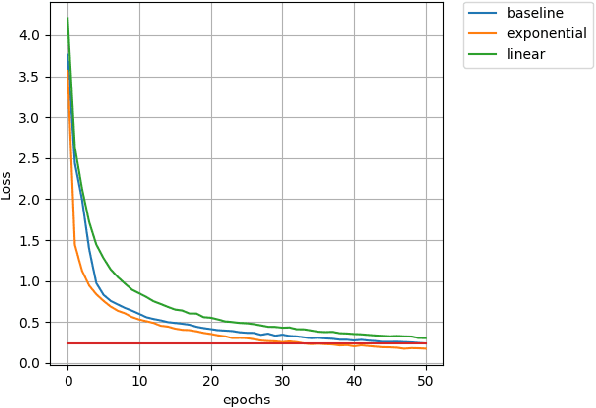
In this paper we introduce a novel method of gradient normalization and decay with respect to depth. Our method leverages the simple concept of normalizing all gradients in a deep neural network, and then decaying said gradients with respect to their depth in the network. Our proposed normalization and decay techniques can be used in conjunction with most current state of the art optimizers and are a very simple addition to any network. This method, although simple, showed improvements in convergence time on state of the art networks such as DenseNet and ResNet on image classification tasks, as well as on an LSTM for natural language processing tasks.
* Results seemed more promising at the time
View paper on