 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Perspective Taking for Opponent Behavior Modeling
Paper and Code
May 11, 2021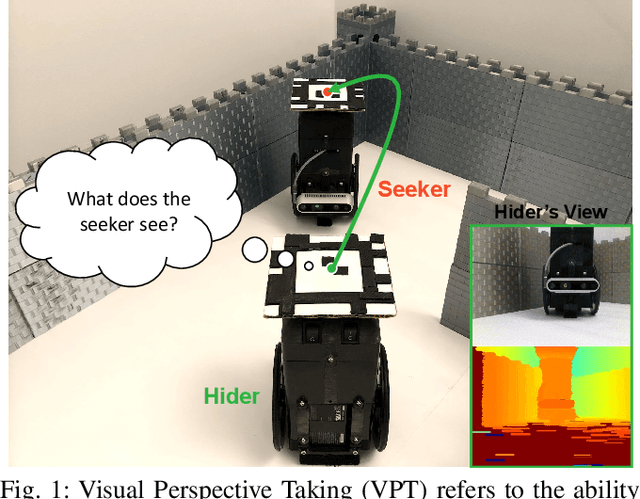
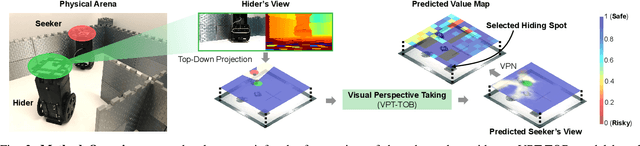
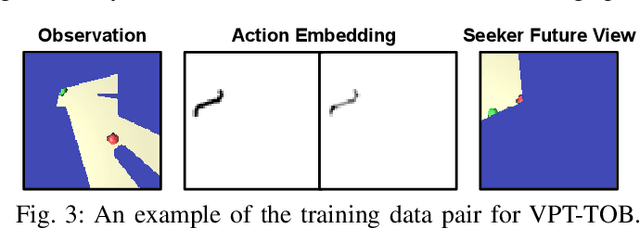
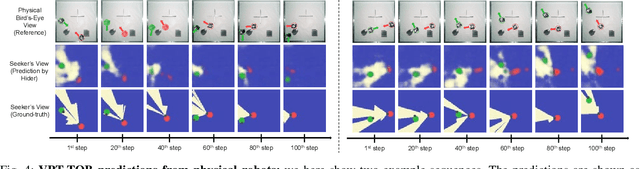
In order to engage in complex social interaction, humans learn at a young age to infer what others see and cannot see from a different point-of-view, and learn to predict others' plans and behaviors. These abilities have been mostly lacking in robots, sometimes making them appear awkward and socially inept. Here we propose an end-to-end long-term visual prediction framework for robots to begin to acquire both these critical cognitive skills, known as Visual Perspective Taking (VPT) and Theory of Behavior (TOB). We demonstrate our approach in the context of visual hide-and-seek - a game that represents a cognitive milestone in human development. Unlike traditional visual predictive model that generates new frames from immediate past frames, our agent can directly predict to multiple future timestamps (25s), extrapolating by 175% beyond the training horizon. We suggest that visual behavior modeling and perspective taking skills will play a critical role in the ability of physical robots to fully integrate into real-world multi-agent activities. Our website is at http://www.cs.columbia.edu/~bchen/vpttob/.