 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapHDR2IR: Caption-Driven Transfer from Visible Light to Infrared Domain
Nov 25, 2024
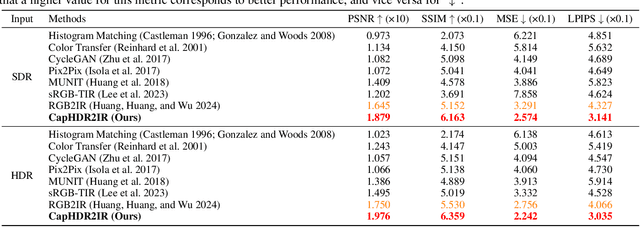

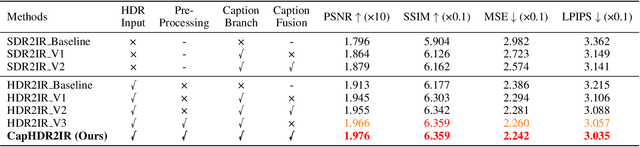
Infrared (IR) imaging offers advantages in several fields due to its unique ability of capturing content in extreme light conditions. However, the demanding hardware requirements of high-resolution IR sensors limit its widespread application. As an alternative, visible light can be used to synthesize IR images but this causes a loss of fidelity in image details and introduces inconsistencies due to lack of contextual awareness of the scene. This stems from a combination of using visible light with a standard dynamic range, especially under extreme lighting, and a lack of contextual awareness can result in pseudo-thermal-crossover artifacts. This occurs when multiple objects with similar temperatures appear indistinguishable in the training data, further exacerbating the loss of fidelity. To solve this challenge, this paper proposes CapHDR2IR, a novel framework incorporating vision-language models using high dynamic range (HDR) images as inputs to generate IR images. HDR images capture a wider range of luminance variations, ensuring reliable IR image generation in different light conditions. Additionally, a dense caption branch integrates semantic understanding, resulting in more meaningful and discernible IR outputs. Extensive experiments on the HDRT dataset show that the proposed CapHDR2IR achieves state-of-the-art performance compared with existing general domain transfer methods and those tailored for visible-to-infrared image translation.
Semantic Aware Diffusion Inverse Tone Mapping
May 24, 2024



The range of real-world scene luminance is larger than the capture capability of many digital camera sensors which leads to details being lost in captured images, most typically in bright regions. Inverse tone mapping attempts to boost these captured Standard Dynamic Range (SDR) images back to High Dynamic Range (HDR) by creating a mapping that linearizes the well exposed values from the SDR image, and provides a luminance boost to the clipped content. However, in most cases, the details in the clipped regions cannot be recovered or estimated. In this paper, we present a novel inverse tone mapping approach for mapping SDR images to HDR that generates lost details in clipped regions through a semantic-aware diffusion based inpainting approach. Our method proposes two major contributions - first, we propose to use a semantic graph to guide SDR diffusion based inpainting in masked regions in a saturated image. Second, drawing inspiration from traditional HDR imaging and bracketing methods, we propose a principled formulation to lift the SDR inpainted regions to HDR that is compatible with generative inpainting methods. Results show that our method demonstrates superior performance across different datasets on objective metrics, and subjective experiments show that the proposed method matches (and in most cases outperforms) state-of-art inverse tone mapping operators in terms of objective metrics and outperforms them for visual fidelity.