 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Neighborhood Environments with Large Language Models
May 13, 2025Neighborhood environments include physical and environmental conditions such as housing quality, roads, and sidewalks, which significantly influence human health and well-being. Traditional methods for assessing these environments, including field surveys and geographic information systems (GIS), are resource-intensive and challenging to evaluate neighborhood environments at scale. Although machine learning offers potential for automated analysis, the laborious process of labeling training data and the lack of accessible models hinder scalability. This study explores the feasibility of large language models (LLMs) such as ChatGPT and Gemini as tools for decoding neighborhood environments (e.g., sidewalk and powerline) at scale. We train a robust YOLOv11-based model, which achieves an average accuracy of 99.13% in detecting six environmental indicators, including streetlight, sidewalk, powerline, apartment, single-lane road, and multilane road. We then evaluate four LLMs, including ChatGPT, Gemini, Claude, and Grok, to assess their feasibility, robustness, and limitations in identifying these indicators, with a focus on the impact of prompting strategies and fine-tuning. We apply majority voting with the top three LLMs to achieve over 88% accuracy, which demonstrates LLMs could be a useful tool to decode the neighborhood environment without any training effort.
LLMs for Explainable AI: A Comprehensive Survey
Mar 31, 2025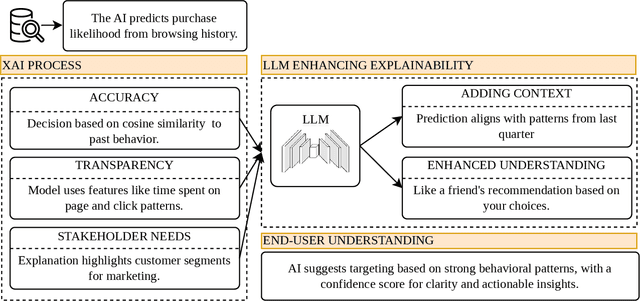



Large Language Models (LLMs) offer a promising approach to enhancing Explainable AI (XAI) by transforming complex machine learning outputs into easy-to-understand narratives, making model predictions more accessible to users, and helping bridge the gap between sophisticated model behavior and human interpretability. AI models, such as state-of-the-art neural networks and deep learning models, are often seen as "black boxes" due to a lack of transparency. As users cannot fully understand how the models reach conclusions, users have difficulty trusting decisions from AI models, which leads to less effective decision-making processes, reduced accountabilities, and unclear potential biases. A challenge arises in developing explainable AI (XAI) models to gain users' trust and provide insights into how models generate their outputs. With the development of Large Language Models, we want to explore the possibilities of using human language-based models, LLMs, for model explainabilities. This survey provides a comprehensive overview of existing approaches regarding LLMs for XAI, and evaluation techniques for LLM-generated explanation, discusses the corresponding challenges and limitations, and examines real-world applications. Finally, we discuss future directions by emphasizing the need for more interpretable, automated, user-centric, and multidisciplinary approaches for XAI via LLMs.
A Survey On Large Language Models For Code Generation
Mar 03, 2025Large Language Models (LLMs) have demonstrated their remarkable capabilities in numerous fields. This survey focuses on how LLMs empower users, regardless of their technical background, to use human languages to automatically generate executable code. We begin with understanding LLMs' limitations and challenges in automated code generation. Subsequently, we review various fine-tuning techniques designed to enhance both the performance and adaptability of LLMs in code generation tasks. We then review the existing metrics and benchmarks for evaluations to assess model performance based on fine-tuning techniques. Finally, we explore the applications of LLMs (e.g. CodeLlama, GitHub Copilot, ToolGen) in code generation tasks to illustrate their roles and functionalities. This survey provides a comprehensive overview of LLMs for code generation, helps researchers in diverse fields better understand the current state-of-the-art technologies, and offers the potential of effectively leveraging LLMs for code generation tasks.
Graph-based Reinforcement Learning for Active Learning in Real Time: An Application in Modeling River Networks
Oct 27, 2020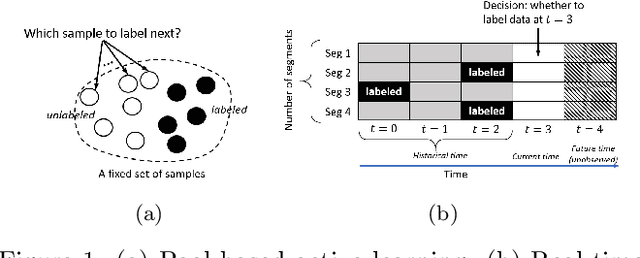
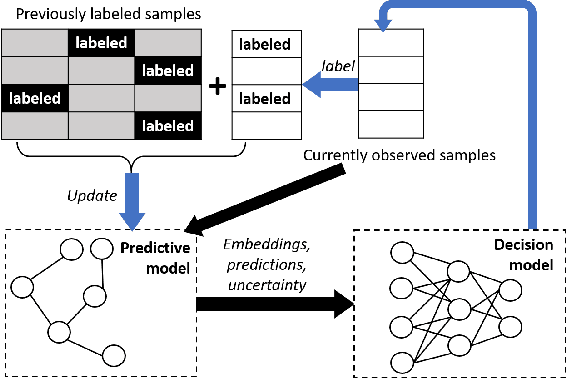
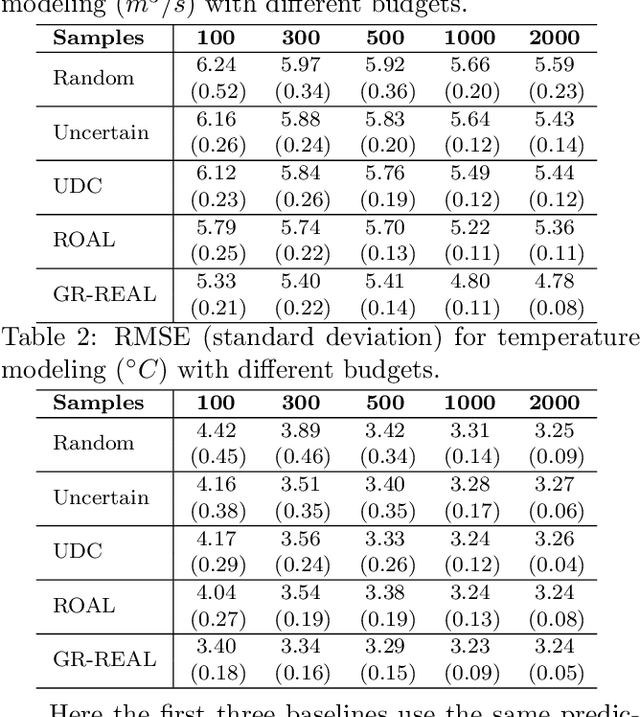
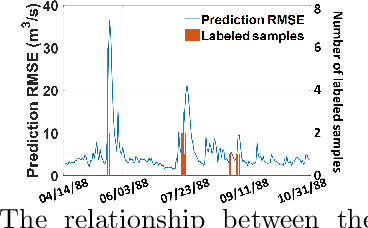
Effective training of advanced ML models requires large amounts of labeled data, which is often scarce in scientific problems given the substantial human labor and material cost to collect labeled data. This poses a challenge on determining when and where we should deploy measuring instruments (e.g., in-situ sensors) to collect labeled data efficiently. This problem differs from traditional pool-based active learning settings in that the labeling decisions have to be made immediately after we observe the input data that come in a time series. In this paper, we develop a real-time active learning method that uses the spatial and temporal contextual information to select representative query samples in a reinforcement learning framework. To reduce the need for large training data, we further propose to transfer the policy learned from simulation data which is generated by existing physics-based models. We demonstrate the effectiveness of the proposed method by predicting streamflow and water temperature in the Delaware River Basin given a limited budget for collecting labeled data. We further study the spatial and temporal distribution of selected samples to verify the ability of this method in selecting informative samples over space and time.