 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat If We Allocate Test-Time Compute Adaptively?
Feb 01, 2026Test-time compute scaling allocates inference computation uniformly, uses fixed sampling strategies, and applies verification only for reranking. In contrast, we propose a verifier-guided adaptive framework treating reasoning as iterative trajectory generation and selection. For each problem, the agent runs multiple inference iterations. In each iteration, it optionally produces a high-level plan, selects a set of reasoning tools and a compute strategy together with an exploration parameter, and then generates a candidate reasoning trajectory. A process reward model (PRM) serves as a unified control signal: within each iteration, step-level PRM scores are aggregated to guide pruning and expansion during generation, and across iterations, aggregated trajectory rewards are used to select the final response. Across datasets, our dynamic, PRM-guided approach consistently outperforms direct test-time scaling, yielding large gains on MATH-500 and several-fold improvements on harder benchmarks such as AIME24 and AMO-Bench. We characterize efficiency using theoretical FLOPs and a compute intensity metric penalizing wasted generation and tool overhead, demonstrating that verification-guided allocation concentrates computation on high-utility reasoning paths.
Continuous-Utility Direct Preference Optimization
Jan 31, 2026Large language model reasoning is often treated as a monolithic capability, relying on binary preference supervision that fails to capture partial progress or fine-grained reasoning quality. We introduce Continuous Utility Direct Preference Optimization (CU-DPO), a framework that aligns models to a portfolio of prompt-based cognitive strategies by replacing binary labels with continuous scores that capture fine-grained reasoning quality. We prove that learning with K strategies yields a Theta(K log K) improvement in sample complexity over binary preferences, and that DPO converges to the entropy-regularized utility-maximizing policy. To exploit this signal, we propose a two-stage training pipeline: (i) strategy selection, which optimizes the model to choose the best strategy for a given problem via best-vs-all comparisons, and (ii) execution refinement, which trains the model to correctly execute the selected strategy using margin-stratified pairs. On mathematical reasoning benchmarks, CU-DPO improves strategy selection accuracy from 35-46 percent to 68-78 percent across seven base models, yielding consistent downstream reasoning gains of up to 6.6 points on in-distribution datasets with effective transfer to out-of-distribution tasks.
On the Fundamental Limits of LLMs at Scale
Nov 17, 2025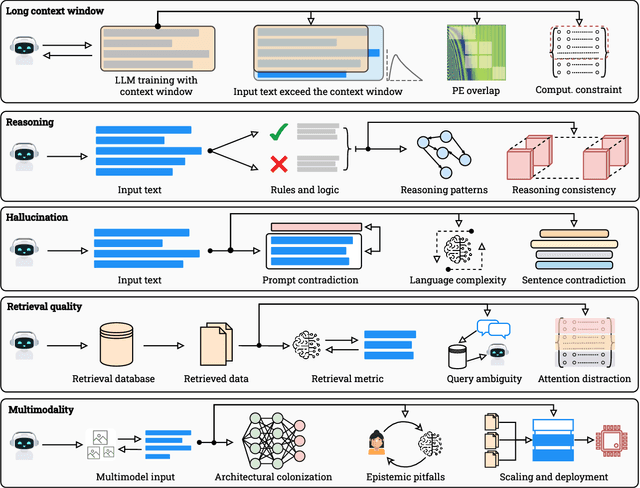
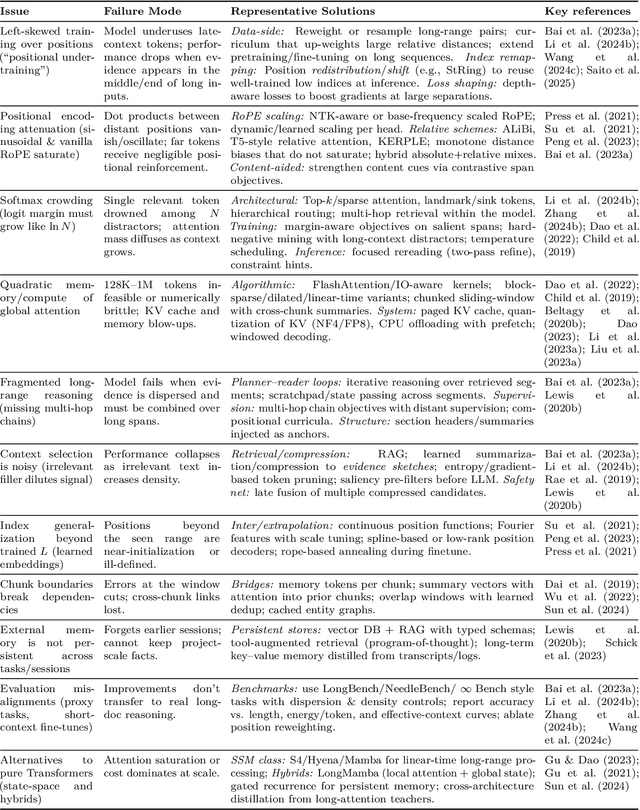
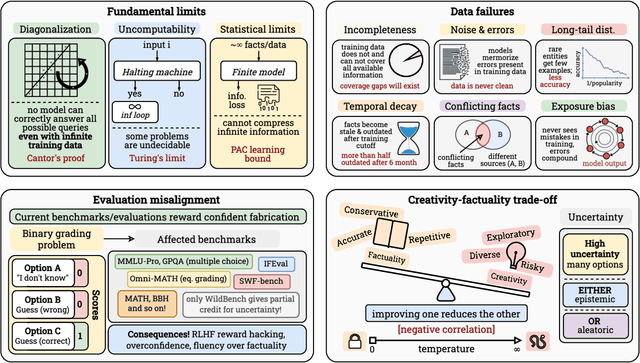
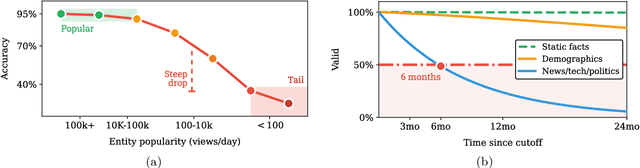
Large Language Models (LLMs) have benefited enormously from scaling, yet these gains are bounded by five fundamental limitations: (1) hallucination, (2) context compression, (3) reasoning degradation, (4) retrieval fragility, and (5) multimodal misalignment. While existing surveys describe these phenomena empirically, they lack a rigorous theoretical synthesis connecting them to the foundational limits of computation, information, and learning. This work closes that gap by presenting a unified, proof-informed framework that formalizes the innate theoretical ceilings of LLM scaling. First, computability and uncomputability imply an irreducible residue of error: for any computably enumerable model family, diagonalization guarantees inputs on which some model must fail, and undecidable queries (e.g., halting-style tasks) induce infinite failure sets for all computable predictors. Second, information-theoretic and statistical constraints bound attainable accuracy even on decidable tasks, finite description length enforces compression error, and long-tail factual knowledge requires prohibitive sample complexity. Third, geometric and computational effects compress long contexts far below their nominal size due to positional under-training, encoding attenuation, and softmax crowding. We further show how likelihood-based training favors pattern completion over inference, how retrieval under token limits suffers from semantic drift and coupling noise, and how multimodal scaling inherits shallow cross-modal alignment. Across sections, we pair theorems and empirical evidence to outline where scaling helps, where it saturates, and where it cannot progress, providing both theoretical foundations and practical mitigation paths like bounded-oracle retrieval, positional curricula, and sparse or hierarchical attention.
ItDPDM: Information-Theoretic Discrete Poisson Diffusion Model
May 08, 2025
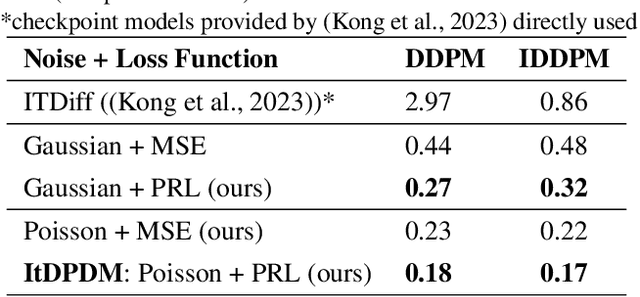


Existing methods for generative modeling of discrete data, such as symbolic music tokens, face two primary challenges: (1) they either embed discrete inputs into continuous state-spaces or (2) rely on variational losses that only approximate the true negative log-likelihood. Previous efforts have individually targeted these limitations. While information-theoretic Gaussian diffusion models alleviate the suboptimality of variational losses, they still perform modeling in continuous domains. In this work, we introduce the Information-Theoretic Discrete Poisson Diffusion Model (ItDPDM), which simultaneously addresses both limitations by directly operating in a discrete state-space via a Poisson diffusion process inspired by photon arrival processes in camera sensors. We introduce a novel Poisson Reconstruction Loss (PRL) and derive an exact relationship between PRL and the true negative log-likelihood, thereby eliminating the need for approximate evidence lower bounds. Experiments conducted on the Lakh MIDI symbolic music dataset and the CIFAR-10 image benchmark demonstrate that ItDPDM delivers significant improvements, reducing test NLL by up to 80% compared to prior baselines, while also achieving faster convergence.
Meta-Thinking in LLMs via Multi-Agent Reinforcement Learning: A Survey
Apr 20, 2025



This survey explores the development of meta-thinking capabilities in Large Language Models (LLMs) from a Multi-Agent Reinforcement Learning (MARL) perspective. Meta-thinking self-reflection, assessment, and control of thinking processes is an important next step in enhancing LLM reliability, flexibility, and performance, particularly for complex or high-stakes tasks. The survey begins by analyzing current LLM limitations, such as hallucinations and the lack of internal self-assessment mechanisms. It then talks about newer methods, including RL from human feedback (RLHF), self-distillation, and chain-of-thought prompting, and each of their limitations. The crux of the survey is to talk about how multi-agent architectures, namely supervisor-agent hierarchies, agent debates, and theory of mind frameworks, can emulate human-like introspective behavior and enhance LLM robustness. By exploring reward mechanisms, self-play, and continuous learning methods in MARL, this survey gives a comprehensive roadmap to building introspective, adaptive, and trustworthy LLMs. Evaluation metrics, datasets, and future research avenues, including neuroscience-inspired architectures and hybrid symbolic reasoning, are also discussed.
LLMs for Explainable AI: A Comprehensive Survey
Mar 31, 2025



Large Language Models (LLMs) offer a promising approach to enhancing Explainable AI (XAI) by transforming complex machine learning outputs into easy-to-understand narratives, making model predictions more accessible to users, and helping bridge the gap between sophisticated model behavior and human interpretability. AI models, such as state-of-the-art neural networks and deep learning models, are often seen as "black boxes" due to a lack of transparency. As users cannot fully understand how the models reach conclusions, users have difficulty trusting decisions from AI models, which leads to less effective decision-making processes, reduced accountabilities, and unclear potential biases. A challenge arises in developing explainable AI (XAI) models to gain users' trust and provide insights into how models generate their outputs. With the development of Large Language Models, we want to explore the possibilities of using human language-based models, LLMs, for model explainabilities. This survey provides a comprehensive overview of existing approaches regarding LLMs for XAI, and evaluation techniques for LLM-generated explanation, discusses the corresponding challenges and limitations, and examines real-world applications. Finally, we discuss future directions by emphasizing the need for more interpretable, automated, user-centric, and multidisciplinary approaches for XAI via LLMs.
Retrieval Augmented Generation with Multi-Modal LLM Framework for Wireless Environments
Mar 09, 2025Future wireless networks aim to deliver high data rates and lower power consumption while ensuring seamless connectivity, necessitating robust optimization. Large language models (LLMs) have been deployed for generalized optimization scenarios. To take advantage of generative AI (GAI) models, we propose retrieval augmented generation (RAG) for multi-sensor wireless environment perception. Utilizing domain-specific prompt engineering, we apply RAG to efficiently harness multimodal data inputs from sensors in a wireless environment. Key pre-processing pipelines including image-to-text conversion, object detection, and distance calculations for multimodal RAG input from multi-sensor data are proposed to obtain a unified vector database crucial for optimizing LLMs in global wireless tasks. Our evaluation, conducted with OpenAI's GPT and Google's Gemini models, demonstrates an 8%, 8%, 10%, 7%, and 12% improvement in relevancy, faithfulness, completeness, similarity, and accuracy, respectively, compared to conventional LLM-based designs. Furthermore, our RAG-based LLM framework with vectorized databases is computationally efficient, providing real-time convergence under latency constraints.
Hierarchical Deep Reinforcement Learning for Adaptive Resource Management in Integrated Terrestrial and Non-Terrestrial Networks
Jan 16, 2025Efficient spectrum allocation has become crucial as the surge in wireless-connected devices demands seamless support for more users and applications, a trend expected to grow with 6G. Innovations in satellite technologies such as SpaceX's Starlink have enabled non-terrestrial networks (NTNs) to work alongside terrestrial networks (TNs) and allocate spectrum based on regional demands. Existing spectrum sharing approaches in TNs use machine learning for interference minimization through power allocation and spectrum sensing, but the unique characteristics of NTNs like varying orbital dynamics and coverage patterns require more sophisticated coordination mechanisms. The proposed work uses a hierarchical deep reinforcement learning (HDRL) approach for efficient spectrum allocation across TN-NTN networks. DRL agents are present at each TN-NTN hierarchy that dynamically learn and allocate spectrum based on regional trends. This framework is 50x faster than the exhaustive search algorithm while achieving 95\% of optimum spectral efficiency. Moreover, it is 3.75x faster than multi-agent DRL, which is commonly used for spectrum sharing, and has a 12\% higher overall average throughput.