 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency-guided semi-supervised outlier detection in heterogeneous data using fuzzy rough sets
Dec 22, 2025Outlier detection aims to find samples that behave differently from the majority of the data. Semi-supervised detection methods can utilize the supervision of partial labels, thus reducing false positive rates. However, most of the current semi-supervised methods focus on numerical data and neglect the heterogeneity of data information. In this paper, we propose a consistency-guided outlier detection algorithm (COD) for heterogeneous data with the fuzzy rough set theory in a semi-supervised manner. First, a few labeled outliers are leveraged to construct label-informed fuzzy similarity relations. Next, the consistency of the fuzzy decision system is introduced to evaluate attributes' contributions to knowledge classification. Subsequently, we define the outlier factor based on the fuzzy similarity class and predict outliers by integrating the classification consistency and the outlier factor. The proposed algorithm is extensively evaluated on 15 freshly proposed datasets. Experimental results demonstrate that COD is better than or comparable with the leading outlier detectors. This manuscript is the accepted author version of a paper published by Elsevier. The final published version is available at https://doi.org/10.1016/j.asoc.2024.112070
* Author's Accepted Manuscript
The Sound of Risk: A Multimodal Physics-Informed Acoustic Model for Forecasting Market Volatility and Enhancing Market Interpretability
Aug 26, 2025



Information asymmetry in financial markets, often amplified by strategically crafted corporate narratives, undermines the effectiveness of conventional textual analysis. We propose a novel multimodal framework for financial risk assessment that integrates textual sentiment with paralinguistic cues derived from executive vocal tract dynamics in earnings calls. Central to this framework is the Physics-Informed Acoustic Model (PIAM), which applies nonlinear acoustics to robustly extract emotional signatures from raw teleconference sound subject to distortions such as signal clipping. Both acoustic and textual emotional states are projected onto an interpretable three-dimensional Affective State Label (ASL) space-Tension, Stability, and Arousal. Using a dataset of 1,795 earnings calls (approximately 1,800 hours), we construct features capturing dynamic shifts in executive affect between scripted presentation and spontaneous Q&A exchanges. Our key finding reveals a pronounced divergence in predictive capacity: while multimodal features do not forecast directional stock returns, they explain up to 43.8% of the out-of-sample variance in 30-day realized volatility. Importantly, volatility predictions are strongly driven by emotional dynamics during executive transitions from scripted to spontaneous speech, particularly reduced textual stability and heightened acoustic instability from CFOs, and significant arousal variability from CEOs. An ablation study confirms that our multimodal approach substantially outperforms a financials-only baseline, underscoring the complementary contributions of acoustic and textual modalities. By decoding latent markers of uncertainty from verifiable biometric signals, our methodology provides investors and regulators a powerful tool for enhancing market interpretability and identifying hidden corporate uncertainty.
A Synergistic Framework of Nonlinear Acoustic Computing and Reinforcement Learning for Real-World Human-Robot Interaction
May 04, 2025This paper introduces a novel framework integrating nonlinear acoustic computing and reinforcement learning to enhance advanced human-robot interaction under complex noise and reverberation. Leveraging physically informed wave equations (e.g., Westervelt, KZK), the approach captures higher-order phenomena such as harmonic generation and shock formation. By embedding these models in a reinforcement learning-driven control loop, the system adaptively optimizes key parameters (e.g., absorption, beamforming) to mitigate multipath interference and non-stationary noise. Experimental evaluations-covering far-field localization, weak signal detection, and multilingual speech recognition-demonstrate that this hybrid strategy surpasses traditional linear methods and purely data-driven baselines, achieving superior noise suppression, minimal latency, and robust accuracy in demanding real-world scenarios. The proposed system demonstrates broad application prospects in AI hardware, robot, machine audition, artificial audition, and brain-machine interfaces.
Challenges and Contributing Factors in the Utilization of Large Language Models (LLMs)
Oct 20, 2023With the development of large language models (LLMs) like the GPT series, their widespread use across various application scenarios presents a myriad of challenges. This review initially explores the issue of domain specificity, where LLMs may struggle to provide precise answers to specialized questions within niche fields. The problem of knowledge forgetting arises as these LLMs might find it hard to balance old and new information. The knowledge repetition phenomenon reveals that sometimes LLMs might deliver overly mechanized responses, lacking depth and originality. Furthermore, knowledge illusion describes situations where LLMs might provide answers that seem insightful but are actually superficial, while knowledge toxicity focuses on harmful or biased information outputs. These challenges underscore problems in the training data and algorithmic design of LLMs. To address these issues, it's suggested to diversify training data, fine-tune models, enhance transparency and interpretability, and incorporate ethics and fairness training. Future technological trends might lean towards iterative methodologies, multimodal learning, model personalization and customization, and real-time learning and feedback mechanisms. In conclusion, future LLMs should prioritize fairness, transparency, and ethics, ensuring they uphold high moral and ethical standards when serving humanity.
Memory-Efficient CNN Accelerator Based on Interlayer Feature Map Compression
Oct 12, 2021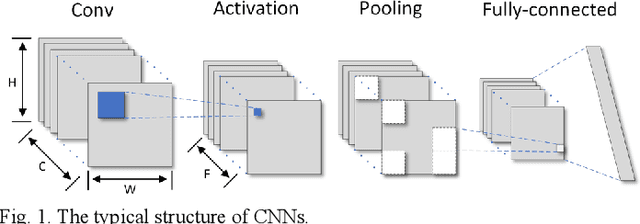
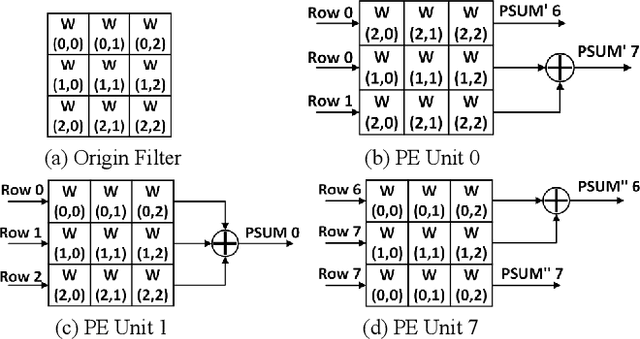
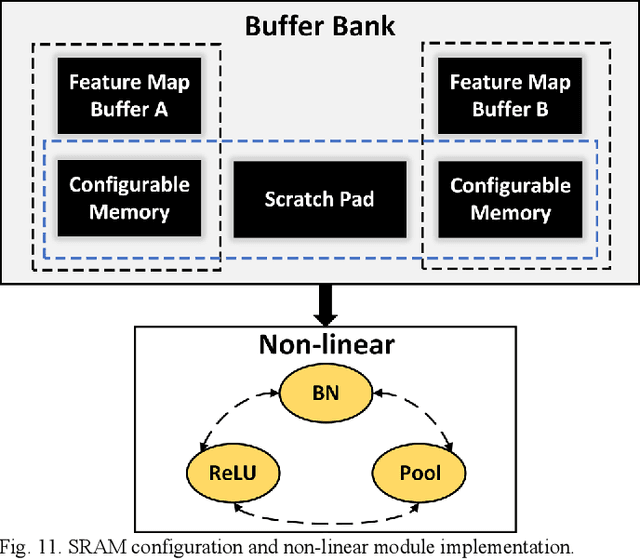
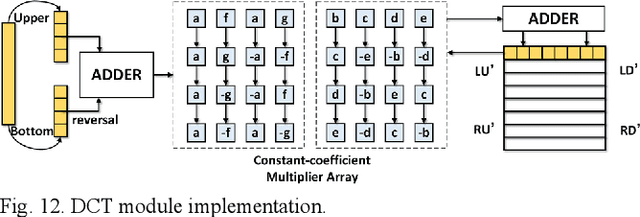
Existing deep convolutional neural networks (CNNs) generate massive interlayer feature data during network inference. To maintain real-time processing in embedded systems, large on-chip memory is required to buffer the interlayer feature maps. In this paper, we propose an efficient hardware accelerator with an interlayer feature compression technique to significantly reduce the required on-chip memory size and off-chip memory access bandwidth. The accelerator compresses interlayer feature maps through transforming the stored data into frequency domain using hardware-implemented 8x8 discrete cosine transform (DCT). The high-frequency components are removed after the DCT through quantization. Sparse matrix compression is utilized to further compress the interlayer feature maps. The on-chip memory allocation scheme is designed to support dynamic configuration of the feature map buffer size and scratch pad size according to different network-layer requirements. The hardware accelerator combines compression, decompression, and CNN acceleration into one computing stream, achieving minimal compressing and processing delay. A prototype accelerator is implemented on an FPGA platform and also synthesized in TSMC 28-nm COMS technology. It achieves 403GOPS peak throughput and 1.4x~3.3x interlayer feature map reduction by adding light hardware area overhead, making it a promising hardware accelerator for intelligent IoT devices.
DeepRMSA: A Deep Reinforcement Learning Framework for Routing, Modulation and Spectrum Assignment in Elastic Optical Networks
May 15, 2019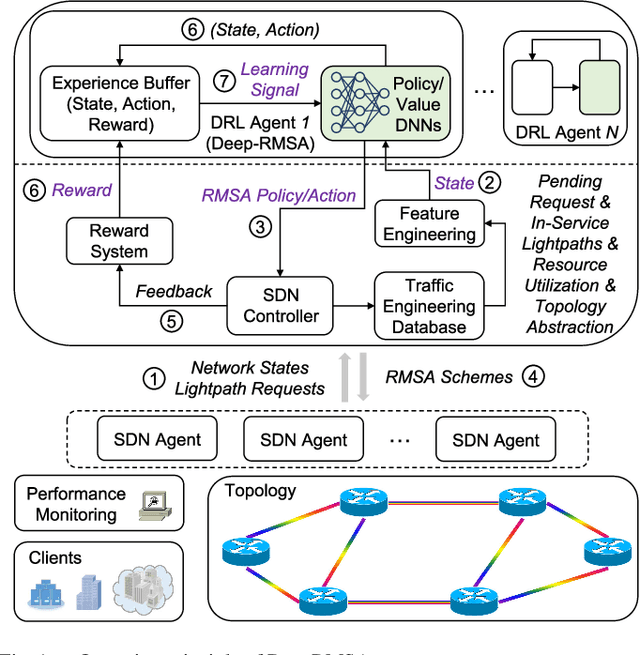
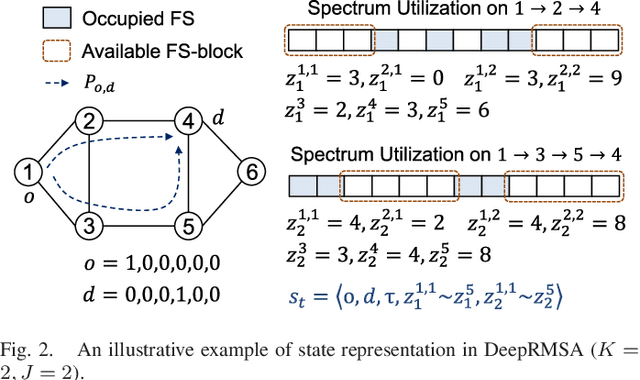
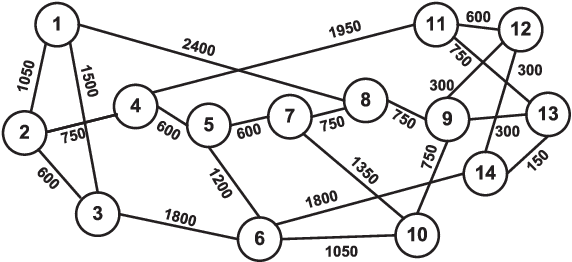
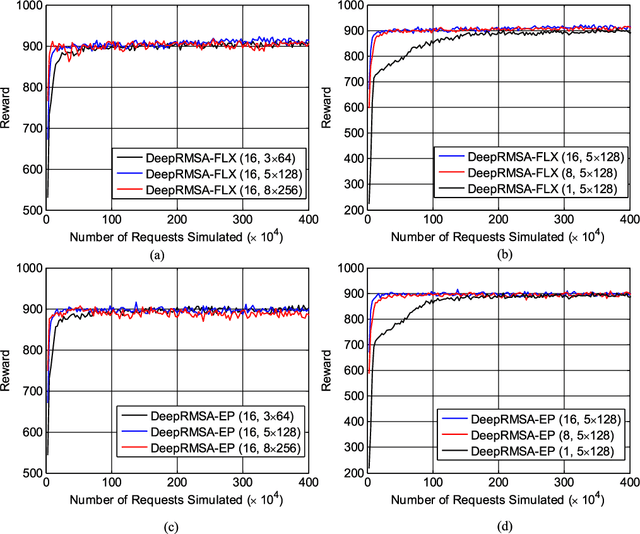
This paper proposes DeepRMSA, a deep reinforcement learning framework for routing, modulation and spectrum assignment (RMSA) in elastic optical networks (EONs). DeepRMSA learns the correct online RMSA policies by parameterizing the policies with deep neural networks (DNNs) that can sense complex EON states. The DNNs are trained with experiences of dynamic lightpath provisioning. We first modify the asynchronous advantage actor-critic algorithm and present an episode-based training mechanism for DeepRMSA, namely, DeepRMSA-EP. DeepRMSA-EP divides the dynamic provisioning process into multiple episodes (each containing the servicing of a fixed number of lightpath requests) and performs training by the end of each episode. The optimization target of DeepRMSA-EP at each step of servicing a request is to maximize the cumulative reward within the rest of the episode. Thus, we obviate the need for estimating the rewards related to unknown future states. To overcome the instability issue in the training of DeepRMSA-EP due to the oscillations of cumulative rewards, we further propose a window-based flexible training mechanism, i.e., DeepRMSA-FLX. DeepRMSA-FLX attempts to smooth out the oscillations by defining the optimization scope at each step as a sliding window, and ensuring that the cumulative rewards always include rewards from a fixed number of requests. Evaluations with the two sample topologies show that DeepRMSA-FLX can effectively stabilize the training while achieving blocking probability reductions of more than 20.3% and 14.3%, when compared with the baselines.
An Analog Neural Network Computing Engine using CMOS-Compatible Charge-Trap-Transistor (CTT)
Aug 09, 2018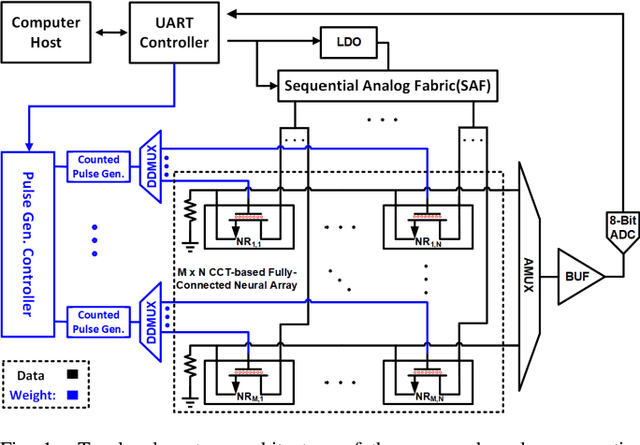
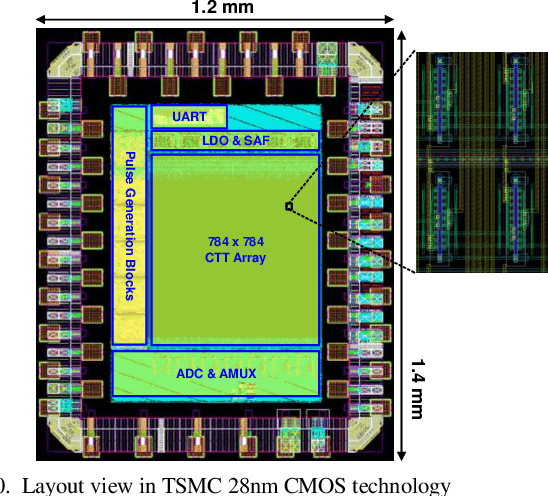
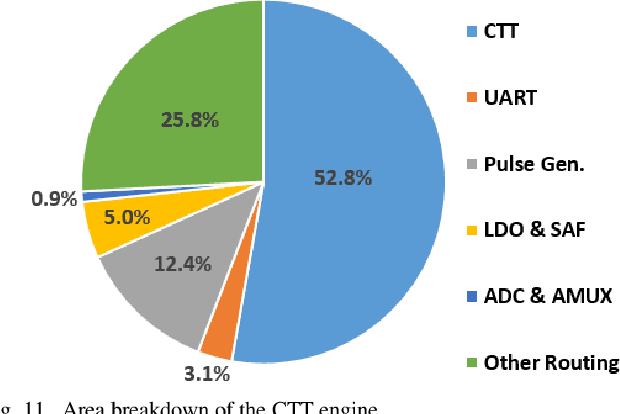
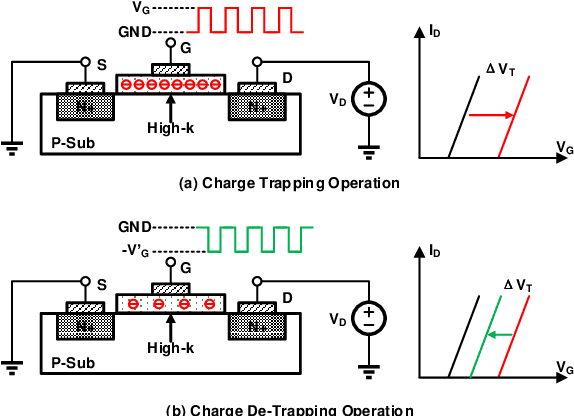
An analog neural network computing engine based on CMOS-compatible charge-trap transistor (CTT) is proposed in this paper. CTT devices are used as analog multipliers. Compared to digital multipliers, CTT-based analog multiplier shows significant area and power reduction. The proposed computing engine is composed of a scalable CTT multiplier array and energy efficient analog-digital interfaces. Through implementing the sequential analog fabric (SAF), the engine mixed-signal interfaces are simplified and hardware overhead remains constant regardless of the size of the array. A proof-of-concept 784 by 784 CTT computing engine is implemented using TSMC 28nm CMOS technology and occupied 0.68mm2. The simulated performance achieves 76.8 TOPS (8-bit) with 500 MHz clock frequency and consumes 14.8 mW. As an example, we utilize this computing engine to address a classic pattern recognition problem -- classifying handwritten digits on MNIST database and obtained a performance comparable to state-of-the-art fully connected neural networks using 8-bit fixed-point resolution.