 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based stereo-aware 3D object detection from binocular images
Apr 24, 2023

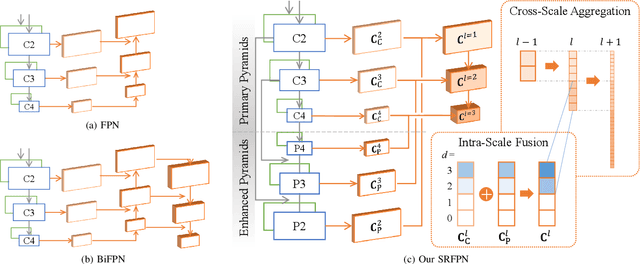

Vision Transformers have shown promising progress in various object detection tasks, including monocular 2D/3D detection and surround-view 3D detection. However, when used in essential and classic stereo 3D object detection, directly adopting those surround-view Transformers leads to slow convergence and significant precision drops. We argue that one of the causes of this defect is that the surround-view Transformers do not consider the stereo-specific image correspondence information. In a surround-view system, the overlapping areas are small, and thus correspondence is not a primary issue. In this paper, we explore the model design of vision Transformers in stereo 3D object detection, focusing particularly on extracting and encoding the task-specific image correspondence information. To achieve this goal, we present TS3D, a Transformer-based Stereo-aware 3D object detector. In the TS3D, a Disparity-Aware Positional Encoding (DAPE) model is proposed to embed the image correspondence information into stereo features. The correspondence is encoded as normalized disparity and is used in conjunction with sinusoidal 2D positional encoding to provide the location information of the 3D scene. To extract enriched multi-scale stereo features, we propose a Stereo Reserving Feature Pyramid Network (SRFPN). The SRFPN is designed to reserve the correspondence information while fusing intra-scale and aggregating cross-scale stereo features. Our proposed TS3D achieves a 41.29% Moderate Car detection average precision on the KITTI test set and takes 88 ms to detect objects from each binocular image pair. It is competitive with advanced counterparts in terms of both precision and inference speed.
Deep Intra-Image Contrastive Learning for Weakly Supervised One-Step Person Search
Feb 09, 2023Weakly supervised person search aims to perform joint pedestrian detection and re-identification (re-id) with only person bounding-box annotations. Recently, the idea of contrastive learning is initially applied to weakly supervised person search, where two common contrast strategies are memory-based contrast and intra-image contrast. We argue that current intra-image contrast is shallow, which suffers from spatial-level and occlusion-level variance. In this paper, we present a novel deep intra-image contrastive learning using a Siamese network. Two key modules are spatial-invariant contrast (SIC) and occlusion-invariant contrast (OIC). SIC performs many-to-one contrasts between two branches of Siamese network and dense prediction contrasts in one branch of Siamese network. With these many-to-one and dense contrasts, SIC tends to learn discriminative scale-invariant and location-invariant features to solve spatial-level variance. OIC enhances feature consistency with the masking strategy to learn occlusion-invariant features. Extensive experiments are performed on two person search datasets CUHK-SYSU and PRW, respectively. Our method achieves a state-of-the-art performance among weakly supervised one-step person search approaches. We hope that our simple intra-image contrastive learning can provide more paradigms on weakly supervised person search. The source code is available at \url{https://github.com/jiabeiwangTJU/DICL}.
TJU-DHD: A Diverse High-Resolution Dataset for Object Detection
Nov 18, 2020
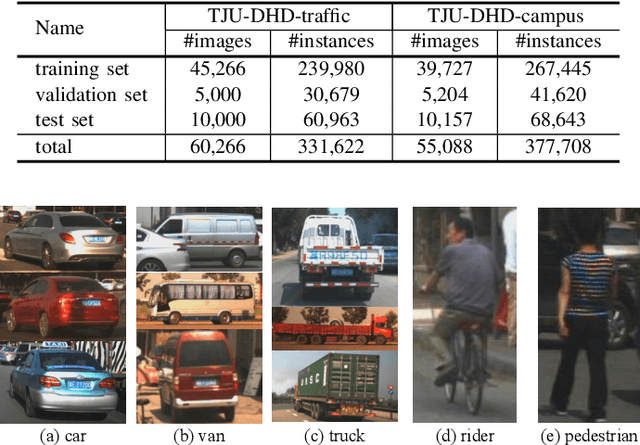
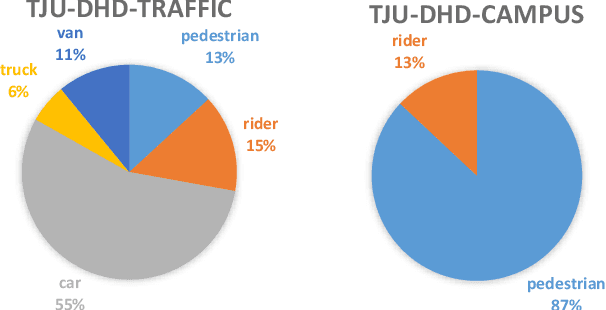
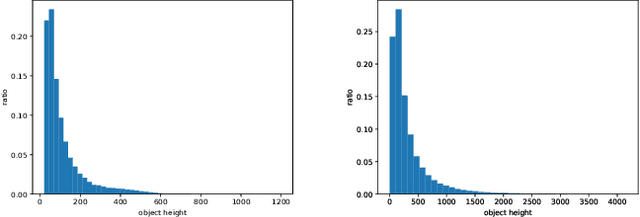
Vehicles, pedestrians, and riders are the most important and interesting objects for the perception modules of self-driving vehicles and video surveillance. However, the state-of-the-art performance of detecting such important objects (esp. small objects) is far from satisfying the demand of practical systems. Large-scale, rich-diversity, and high-resolution datasets play an important role in developing better object detection methods to satisfy the demand. Existing public large-scale datasets such as MS COCO collected from websites do not focus on the specific scenarios. Moreover, the popular datasets (e.g., KITTI and Citypersons) collected from the specific scenarios are limited in the number of images and instances, the resolution, and the diversity. To attempt to solve the problem, we build a diverse high-resolution dataset (called TJU-DHD). The dataset contains 115,354 high-resolution images (52% images have a resolution of 1624$\times$1200 pixels and 48% images have a resolution of at least 2,560$\times$1,440 pixels) and 709,330 labeled objects in total with a large variance in scale and appearance. Meanwhile, the dataset has a rich diversity in season variance, illumination variance, and weather variance. In addition, a new diverse pedestrian dataset is further built. With the four different detectors (i.e., the one-stage RetinaNet, anchor-free FCOS, two-stage FPN, and Cascade R-CNN), experiments about object detection and pedestrian detection are conducted. We hope that the newly built dataset can help promote the research on object detection and pedestrian detection in these two scenes. The dataset is available at https://github.com/tjubiit/TJU-DHD.
* object detection and pedestrian detection. website: https://github.com/tjubiit/TJU-DHD