 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveCtrl: Conditioned Sim-to-Real Driving Video Generation
May 14, 2026Large-scale labelled driving video data is essential for training autonomous driving systems. Although simulation offers scalable and fully annotated data, the domain gap between synthetic and real-world driving videos significantly limits its utility for downstream deployment. Existing video generation methods are not well-suited for this task, as they fail to simultaneously preserve scene structure, object dynamics, temporal consistency, and visual realism, all of which are critical for maintaining annotation validity in generated data. In this paper, we present DriveCtrl, a depth-conditioned controllable sim-to-real video generation framework for realistic driving video synthesis. Built upon a pretrained video foundation model, DriveCtrl introduces a structure-aware adapter that enables depth-guided generation while preserving the scene layout and motion patterns of the source simulation, producing temporally coherent driving videos that remain aligned with the original simulated sequences. We further introduce a scalable data generation pipeline that transforms simulator videos into realistic driving footage matching the visual style of a target real-world dataset. The pipeline supports three conditioning signals: structural depth, reference-dataset style, and text prompts, while preserving frame-level annotations for downstream perception tasks. To better assess this task, we propose a driving-domain-specific knowledge-informed evaluation metric called Driving Video Realism Score (DVRS) that assesses the realism of generated videos. Experiments demonstrate that DriveCtrl consistently outperforms the base model and competing alternatives in realism, temporal quality, and perception task performance, substantially narrowing the sim-to-real gap for driving video generation.
Reflection Generation for Composite Image Using Diffusion Model
Apr 02, 2026Image composition involves inserting a foreground object into the background while synthesizing environment-consistent effects such as shadows and reflections. Although shadow generation has been extensively studied, reflection generation remains largely underexplored. In this work, we focus on reflection generation. We inject the prior information of reflection placement and reflection appearance into foundation diffusion model. We also divide reflections into two types and adopt type-aware model design. To support training, we construct the first large-scale object reflection dataset DEROBA. Experiments demonstrate that our method generates reflections that are physically coherent and visually realistic, establishing a new benchmark for reflection generation.
AURORA-KITTI: Any-Weather Depth Completion and Denoising in the Wild
Mar 16, 2026Robust depth completion is fundamental to real-world 3D scene understanding, yet existing RGB-LiDAR fusion methods degrade significantly under adverse weather, where both camera images and LiDAR measurements suffer from weather-induced corruption. In this paper, we introduce AURORA-KITTI, the first large-scale multi-modal, multi-weather benchmark for robust depth completion in the wild. We further formulate Depth Completion and Denoising (DCD) as a unified task that jointly reconstructs a dense depth map from corrupted sparse inputs while suppressing weather-induced noise. AURORA-KITTI contains over \textit{82K} weather-consistent RGBL pairs with metric depth ground truth, spanning diverse weather types, three severity levels, day and night scenes, paired clean references, lens occlusion conditions, and textual descriptions. Moreover, we introduce DDCD, an efficient distillation-based baseline that leverages depth foundation models to inject clean structural priors into in-the-wild DCD training. DDCD achieves state-of-the-art performance on AURORA-KITTI and the real-world DENSE dataset while maintaining efficiency. Notably, our results further show that weather-aware, physically consistent data contributes more to robustness than architectural modifications alone. Data and code will be released upon publication.
Decoupling Amplitude and Phase Attention in Frequency Domain for RGB-Event based Visual Object Tracking
Jan 03, 2026Existing RGB-Event visual object tracking approaches primarily rely on conventional feature-level fusion, failing to fully exploit the unique advantages of event cameras. In particular, the high dynamic range and motion-sensitive nature of event cameras are often overlooked, while low-information regions are processed uniformly, leading to unnecessary computational overhead for the backbone network. To address these issues, we propose a novel tracking framework that performs early fusion in the frequency domain, enabling effective aggregation of high-frequency information from the event modality. Specifically, RGB and event modalities are transformed from the spatial domain to the frequency domain via the Fast Fourier Transform, with their amplitude and phase components decoupled. High-frequency event information is selectively fused into RGB modality through amplitude and phase attention, enhancing feature representation while substantially reducing backbone computation. In addition, a motion-guided spatial sparsification module leverages the motion-sensitive nature of event cameras to capture the relationship between target motion cues and spatial probability distribution, filtering out low-information regions and enhancing target-relevant features. Finally, a sparse set of target-relevant features is fed into the backbone network for learning, and the tracking head predicts the final target position. Extensive experiments on three widely used RGB-Event tracking benchmark datasets, including FE108, FELT, and COESOT, demonstrate the high performance and efficiency of our method. The source code of this paper will be released on https://github.com/Event-AHU/OpenEvTracking
Exploring Generative AI for Sim2Real in Driving Data Synthesis
Apr 14, 2024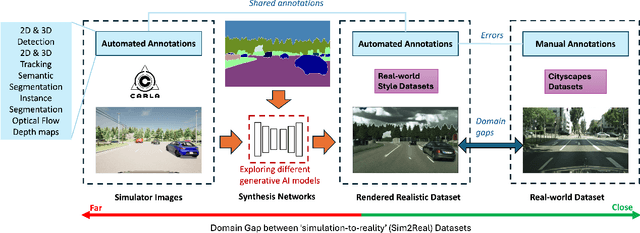



Datasets are essential for training and testing vehicle perception algorithms. However, the collection and annotation of real-world images is time-consuming and expensive. Driving simulators offer a solution by automatically generating various driving scenarios with corresponding annotations, but the simulation-to-reality (Sim2Real) domain gap remains a challenge. While most of the Generative Artificial Intelligence (AI) follows the de facto Generative Adversarial Nets (GANs)-based methods, the recent emerging diffusion probabilistic models have not been fully explored in mitigating Sim2Real challenges for driving data synthesis. To explore the performance, this paper applied three different generative AI methods to leverage semantic label maps from a driving simulator as a bridge for the creation of realistic datasets. A comparative analysis of these methods is presented from the perspective of image quality and perception. New synthetic datasets, which include driving images and auto-generated high-quality annotations, are produced with low costs and high scene variability. The experimental results show that although GAN-based methods are adept at generating high-quality images when provided with manually annotated labels, ControlNet produces synthetic datasets with fewer artefacts and more structural fidelity when using simulator-generated labels. This suggests that the diffusion-based approach may provide improved stability and an alternative method for addressing Sim2Real challenges.
Benchmarking the Robustness of Panoptic Segmentation for Automated Driving
Feb 23, 2024
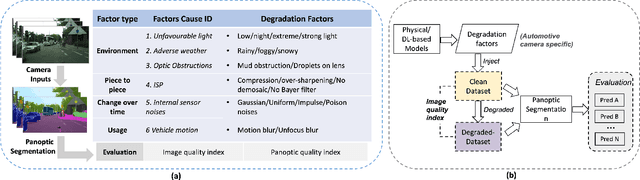


Precise situational awareness is required for the safe decision-making of assisted and automated driving (AAD) functions. Panoptic segmentation is a promising perception technique to identify and categorise objects, impending hazards, and driveable space at a pixel level. While segmentation quality is generally associated with the quality of the camera data, a comprehensive understanding and modelling of this relationship are paramount for AAD system designers. Motivated by such a need, this work proposes a unifying pipeline to assess the robustness of panoptic segmentation models for AAD, correlating it with traditional image quality. The first step of the proposed pipeline involves generating degraded camera data that reflects real-world noise factors. To this end, 19 noise factors have been identified and implemented with 3 severity levels. Of these factors, this work proposes novel models for unfavourable light and snow. After applying the degradation models, three state-of-the-art CNN- and vision transformers (ViT)-based panoptic segmentation networks are used to analyse their robustness. The variations of the segmentation performance are then correlated to 8 selected image quality metrics. This research reveals that: 1) certain specific noise factors produce the highest impact on panoptic segmentation, i.e. droplets on lens and Gaussian noise; 2) the ViT-based panoptic segmentation backbones show better robustness to the considered noise factors; 3) some image quality metrics (i.e. LPIPS and CW-SSIM) correlate strongly with panoptic segmentation performance and therefore they can be used as predictive metrics for network performance.
Factors Impacting the Quality of User Answers on Smartphones
Jun 12, 2023
So far, most research investigating the predictability of human behavior, such as mobility and social interactions, has focused mainly on the exploitation of sensor data. However, sensor data can be difficult to capture the subjective motivations behind the individuals' behavior. Understanding personal context (e.g., where one is and what they are doing) can greatly increase predictability. The main limitation is that human input is often missing or inaccurate. The goal of this paper is to identify factors that influence the quality of responses when users are asked about their current context. We find that two key factors influence the quality of responses: user reaction time and completion time. These factors correlate with various exogenous causes (e.g., situational context, time of day) and endogenous causes (e.g., procrastination attitude, mood). In turn, we study how these two factors impact the quality of responses.
* 5 pages, 1 table
Lifelong Personal Context Recognition
May 10, 2022
We focus on the development of AIs which live in lifelong symbiosis with a human. The key prerequisite for this task is that the AI understands - at any moment in time - the personal situational context that the human is in. We outline the key challenges that this task brings forth, namely (i) handling the human-like and ego-centric nature of the the user's context, necessary for understanding and providing useful suggestions, (ii) performing lifelong context recognition using machine learning in a way that is robust to change, and (iii) maintaining alignment between the AI's and human's representations of the world through continual bidirectional interaction. In this short paper, we summarize our recent attempts at tackling these challenges, discuss the lessons learned, and highlight directions of future research. The main take-away message is that pursuing this project requires research which lies at the intersection of knowledge representation and machine learning. Neither technology can achieve this goal without the other.
The Unconstrained Ear Recognition Challenge 2019 - ArXiv Version With Appendix
Mar 14, 2019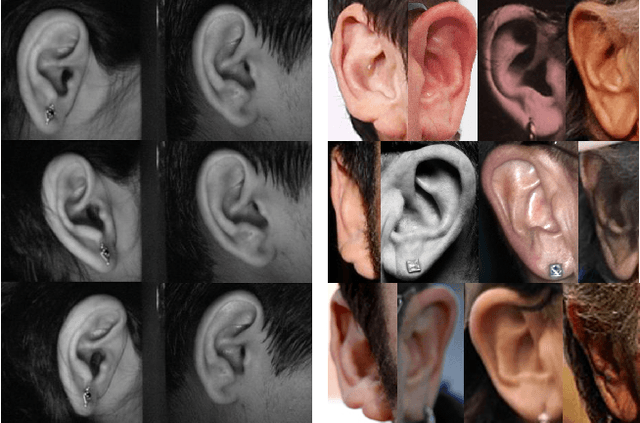

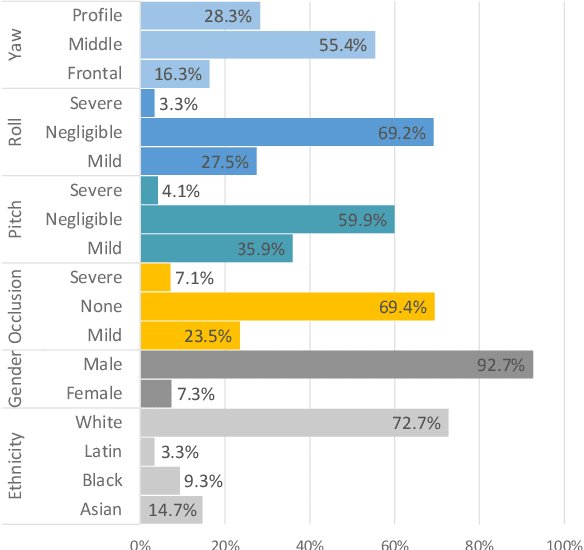
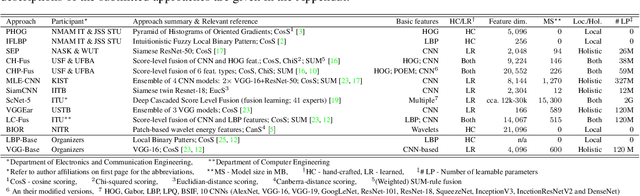
This paper presents a summary of the 2019 Unconstrained Ear Recognition Challenge (UERC), the second in a series of group benchmarking efforts centered around the problem of person recognition from ear images captured in uncontrolled settings. The goal of the challenge is to assess the performance of existing ear recognition techniques on a challenging large-scale ear dataset and to analyze performance of the technology from various viewpoints, such as generalization abilities to unseen data characteristics, sensitivity to rotations, occlusions and image resolution and performance bias on sub-groups of subjects, selected based on demographic criteria, i.e. gender and ethnicity. Research groups from 12 institutions entered the competition and submitted a total of 13 recognition approaches ranging from descriptor-based methods to deep-learning models. The majority of submissions focused on ensemble based methods combining either representations from multiple deep models or hand-crafted with learned image descriptors. Our analysis shows that methods incorporating deep learning models clearly outperform techniques relying solely on hand-crafted descriptors, even though both groups of techniques exhibit similar behaviour when it comes to robustness to various covariates, such presence of occlusions, changes in (head) pose, or variability in image resolution. The results of the challenge also show that there has been considerable progress since the first UERC in 2017, but that there is still ample room for further research in this area.