 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAE: A Property-based Method for Knowledge Graph Alignment and Extension
Jul 07, 2024A common solution to the semantic heterogeneity problem is to perform knowledge graph (KG) extension exploiting the information encoded in one or more candidate KGs, where the alignment between the reference KG and candidate KGs is considered the critical procedure. However, existing KG alignment methods mainly rely on entity type (etype) label matching as a prerequisite, which is poorly performing in practice or not applicable in some cases. In this paper, we design a machine learning-based framework for KG extension, including an alternative novel property-based alignment approach that allows aligning etypes on the basis of the properties used to define them. The main intuition is that it is properties that intentionally define the etype, and this definition is independent of the specific label used to name an etype, and of the specific hierarchical schema of KGs. Compared with the state-of-the-art, the experimental results show the validity of the KG alignment approach and the superiority of the proposed KG extension framework, both quantitatively and qualitatively.
Run Time Bounds for Integer-Valued OneMax Functions
Jul 21, 2023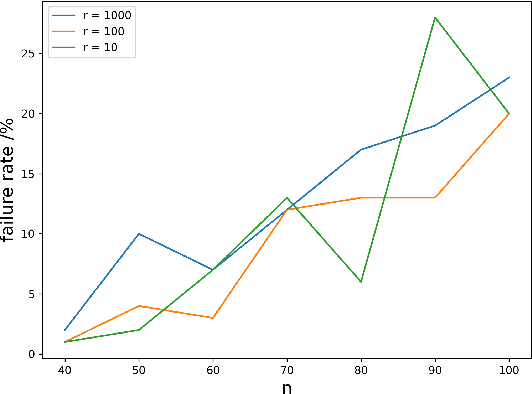
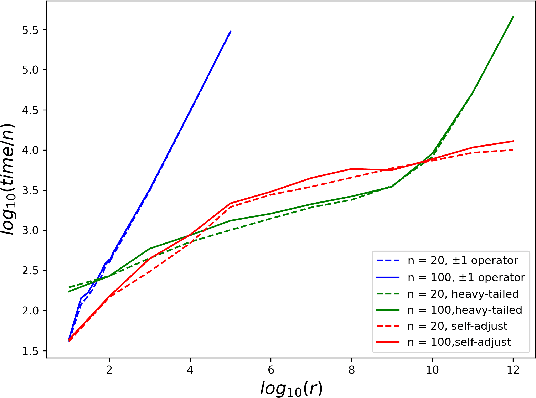
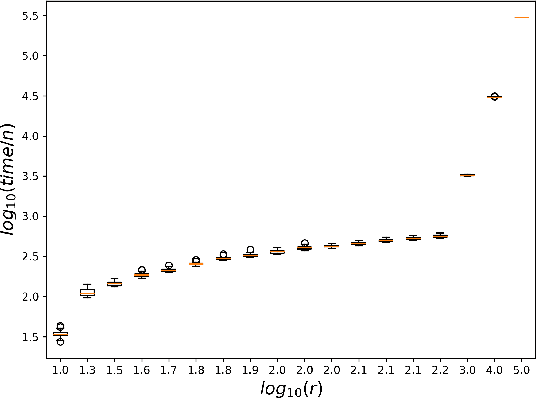
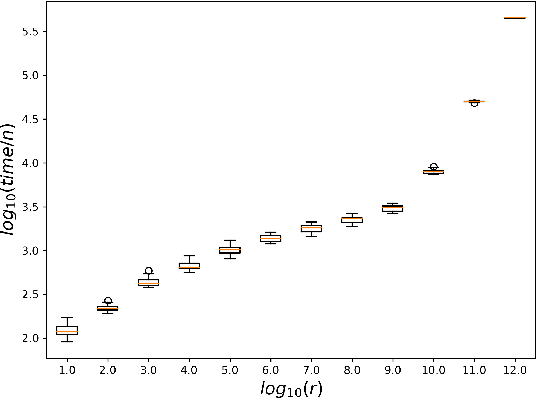
While most theoretical run time analyses of discrete randomized search heuristics focused on finite search spaces, we consider the search space $\mathbb{Z}^n$. This is a further generalization of the search space of multi-valued decision variables $\{0,\ldots,r-1\}^n$. We consider as fitness functions the distance to the (unique) non-zero optimum $a$ (based on the $L_1$-metric) and the \ooea which mutates by applying a step-operator on each component that is determined to be varied. For changing by $\pm 1$, we show that the expected optimization time is $\Theta(n \cdot (|a|_{\infty} + \log(|a|_H)))$. In particular, the time is linear in the maximum value of the optimum $a$. Employing a different step operator which chooses a step size from a distribution so heavy-tailed that the expectation is infinite, we get an optimization time of $O(n \cdot \log^2 (|a|_1) \cdot \left(\log (\log (|a|_1))\right)^{1 + \epsilon})$. Furthermore, we show that RLS with step size adaptation achieves an optimization time of $\Theta(n \cdot \log(|a|_1))$. We conclude with an empirical analysis, comparing the above algorithms also with a variant of CMA-ES for discrete search spaces.
DDMM-Synth: A Denoising Diffusion Model for Cross-modal Medical Image Synthesis with Sparse-view Measurement Embedding
Mar 28, 2023



Reducing the radiation dose in computed tomography (CT) is important to mitigate radiation-induced risks. One option is to employ a well-trained model to compensate for incomplete information and map sparse-view measurements to the CT reconstruction. However, reconstruction from sparsely sampled measurements is insufficient to uniquely characterize an object in CT, and a learned prior model may be inadequate for unencountered cases. Medical modal translation from magnetic resonance imaging (MRI) to CT is an alternative but may introduce incorrect information into the synthesized CT images in addition to the fact that there exists no explicit transformation describing their relationship. To address these issues, we propose a novel framework called the denoising diffusion model for medical image synthesis (DDMM-Synth) to close the performance gaps described above. This framework combines an MRI-guided diffusion model with a new CT measurement embedding reverse sampling scheme. Specifically, the null-space content of the one-step denoising result is refined by the MRI-guided data distribution prior, and its range-space component derived from an explicit operator matrix and the sparse-view CT measurements is directly integrated into the inference stage. DDMM-Synth can adjust the projection number of CT a posteriori for a particular clinical application and its modified version can even improve the results significantly for noisy cases. Our results show that DDMM-Synth outperforms other state-of-the-art supervised-learning-based baselines under fair experimental conditions.
Lifelong Personal Context Recognition
May 10, 2022
We focus on the development of AIs which live in lifelong symbiosis with a human. The key prerequisite for this task is that the AI understands - at any moment in time - the personal situational context that the human is in. We outline the key challenges that this task brings forth, namely (i) handling the human-like and ego-centric nature of the the user's context, necessary for understanding and providing useful suggestions, (ii) performing lifelong context recognition using machine learning in a way that is robust to change, and (iii) maintaining alignment between the AI's and human's representations of the world through continual bidirectional interaction. In this short paper, we summarize our recent attempts at tackling these challenges, discuss the lessons learned, and highlight directions of future research. The main take-away message is that pursuing this project requires research which lies at the intersection of knowledge representation and machine learning. Neither technology can achieve this goal without the other.
Streaming and Learning the Personal Context
Aug 18, 2021

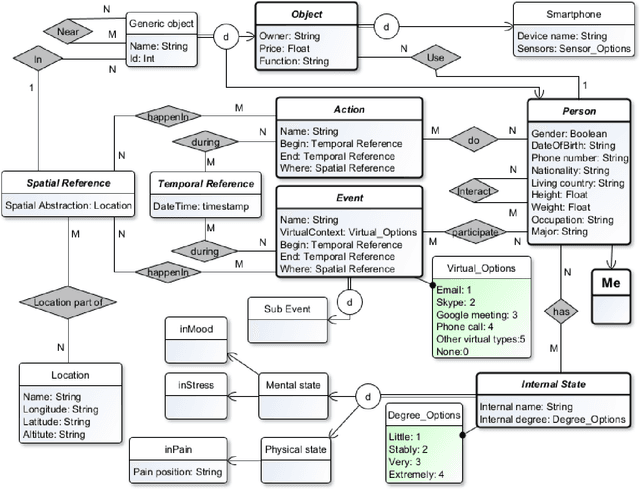
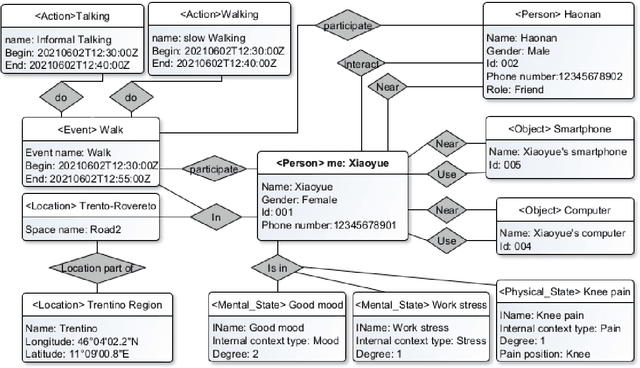
The representation of the personal context is complex and essential to improve the help machines can give to humans for making sense of the world, and the help humans can give to machines to improve their efficiency. We aim to design a novel model representation of the personal context and design a learning process for better integration with machine learning. We aim to implement these elements into a modern system architecture focus in real-life environments. Also, we show how our proposal can improve in specifically related work papers. Finally, we are moving forward with a better personal context representation with an improved model, the implementation of the learning process, and the architectural design of these components.