 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRun Time Bounds for Integer-Valued OneMax Functions
Jul 21, 2023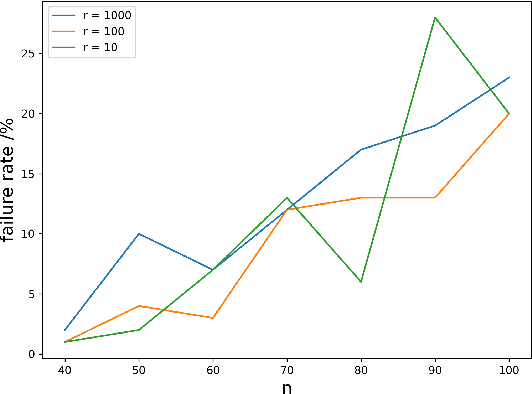
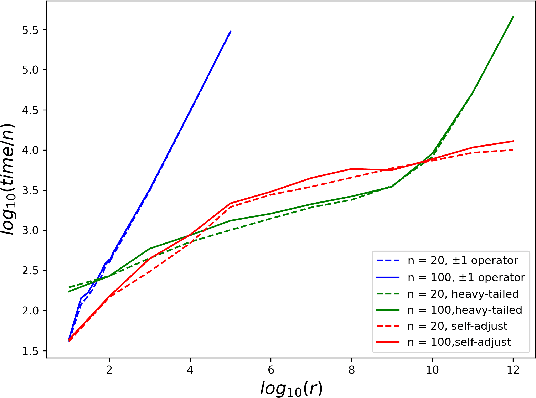
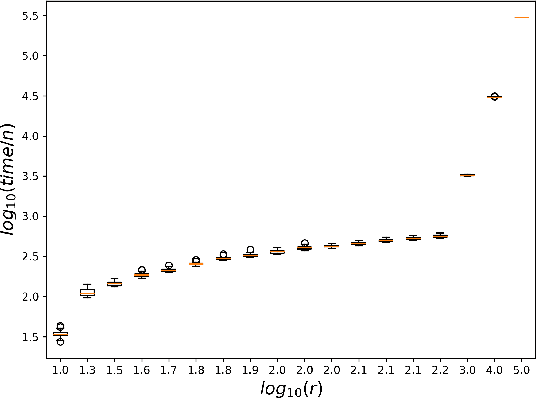
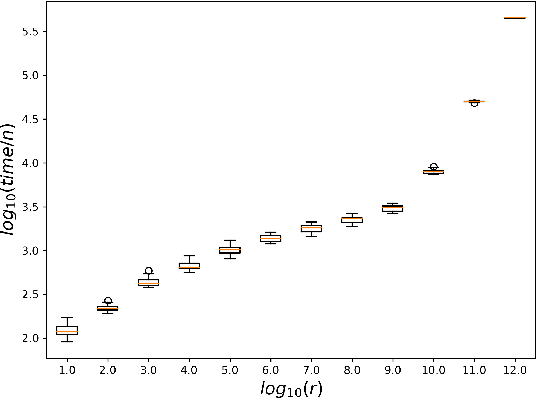
While most theoretical run time analyses of discrete randomized search heuristics focused on finite search spaces, we consider the search space $\mathbb{Z}^n$. This is a further generalization of the search space of multi-valued decision variables $\{0,\ldots,r-1\}^n$. We consider as fitness functions the distance to the (unique) non-zero optimum $a$ (based on the $L_1$-metric) and the \ooea which mutates by applying a step-operator on each component that is determined to be varied. For changing by $\pm 1$, we show that the expected optimization time is $\Theta(n \cdot (|a|_{\infty} + \log(|a|_H)))$. In particular, the time is linear in the maximum value of the optimum $a$. Employing a different step operator which chooses a step size from a distribution so heavy-tailed that the expectation is infinite, we get an optimization time of $O(n \cdot \log^2 (|a|_1) \cdot \left(\log (\log (|a|_1))\right)^{1 + \epsilon})$. Furthermore, we show that RLS with step size adaptation achieves an optimization time of $\Theta(n \cdot \log(|a|_1))$. We conclude with an empirical analysis, comparing the above algorithms also with a variant of CMA-ES for discrete search spaces.
Analysis of the EA on LeadingOnes with Constraints
May 29, 2023Understanding how evolutionary algorithms perform on constrained problems has gained increasing attention in recent years. In this paper, we study how evolutionary algorithms optimize constrained versions of the classical LeadingOnes problem. We first provide a run time analysis for the classical (1+1) EA on the LeadingOnes problem with a deterministic cardinality constraint, giving $\Theta(n (n-B)\log(B) + n^2)$ as the tight bound. Our results show that the behaviour of the algorithm is highly dependent on the constraint bound of the uniform constraint. Afterwards, we consider the problem in the context of stochastic constraints and provide insights using experimental studies on how the ($\mu$+1) EA is able to deal with these constraints in a sampling-based setting.
Theoretical Study of Optimizing Rugged Landscapes with the cGA
Nov 24, 2022Estimation of distribution algorithms (EDAs) provide a distribution - based approach for optimization which adapts its probability distribution during the run of the algorithm. We contribute to the theoretical understanding of EDAs and point out that their distribution approach makes them more suitable to deal with rugged fitness landscapes than classical local search algorithms. Concretely, we make the OneMax function rugged by adding noise to each fitness value. The cGA can nevertheless find solutions with n(1 - \epsilon) many 1s, even for high variance of noise. In contrast to this, RLS and the (1+1) EA, with high probability, only find solutions with n(1/2+o(1)) many 1s, even for noise with small variance.