 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised HDR Imaging: What Can Be Learned from a Single 8-bit Video?
Feb 11, 2022



Recently, Deep Learning-based methods for inverse tone-mapping standard dynamic range (SDR) images to obtain high dynamic range (HDR) images have become very popular. These methods manage to fill over-exposed areas convincingly both in terms of details and dynamic range. Typically, these methods, to be effective, need to learn from large datasets and to transfer this knowledge to the network weights. In this work, we tackle this problem from a completely different perspective. What can we learn from a single SDR video? With the presented zero-shot approach, we show that, in many cases, a single SDR video is sufficient to be able to generate an HDR video of the same quality or better than other state-of-the-art methods.
Deep HDR Hallucination for Inverse Tone Mapping
Jun 17, 2021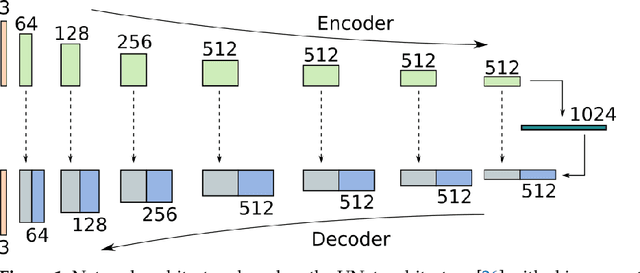

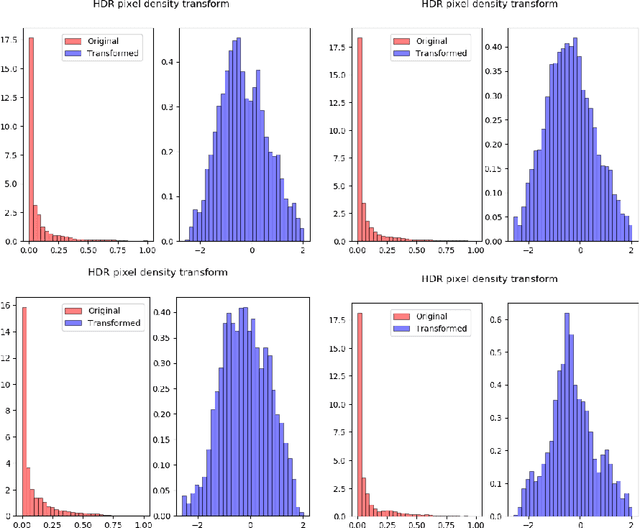

Inverse Tone Mapping (ITM) methods attempt to reconstruct High Dynamic Range (HDR) information from Low Dynamic Range (LDR) image content. The dynamic range of well-exposed areas must be expanded and any missing information due to over/under-exposure must be recovered (hallucinated). The majority of methods focus on the former and are relatively successful, while most attempts on the latter are not of sufficient quality, even ones based on Convolutional Neural Networks (CNNs). A major factor for the reduced inpainting quality in some works is the choice of loss function. Work based on Generative Adversarial Networks (GANs) shows promising results for image synthesis and LDR inpainting, suggesting that GAN losses can improve inverse tone mapping results. This work presents a GAN-based method that hallucinates missing information from badly exposed areas in LDR images and compares its efficacy with alternative variations. The proposed method is quantitatively competitive with state-of-the-art inverse tone mapping methods, providing good dynamic range expansion for well-exposed areas and plausible hallucinations for saturated and under-exposed areas. A density-based normalisation method, targeted for HDR content, is also proposed, as well as an HDR data augmentation method targeted for HDR hallucination.
Deep Controllable Backlight Dimming
Aug 19, 2020
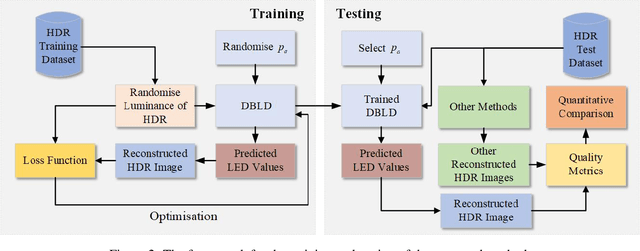
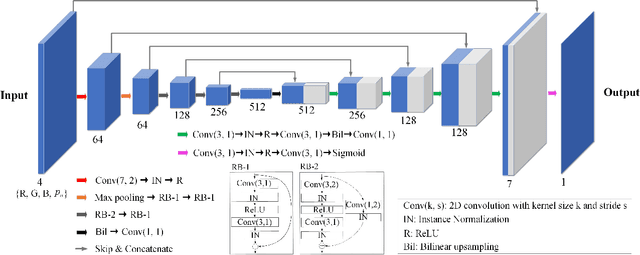
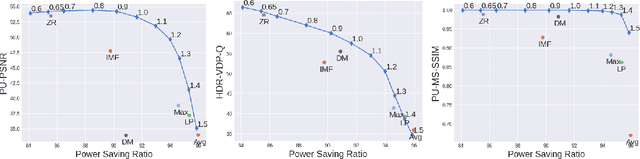
Dual-panel displays require local dimming algorithms in order to reproduce content with high fidelity and high dynamic range. In this work, a novel deep learning based local dimming method is proposed for rendering HDR images on dual-panel HDR displays. The method uses a Convolutional Neural Network to predict backlight values, using as input the HDR image that is to be displayed. The model is designed and trained via a controllable power parameter that allows a user to trade off between power and quality. The proposed method is evaluated against six other methods on a test set of 105 HDR images, using a variety of quantitative quality metrics. Results demonstrate improved display quality and better power consumption when using the proposed method compared to the best alternatives.
Spectrally Consistent UNet for High Fidelity Image Transformations
Apr 22, 2020

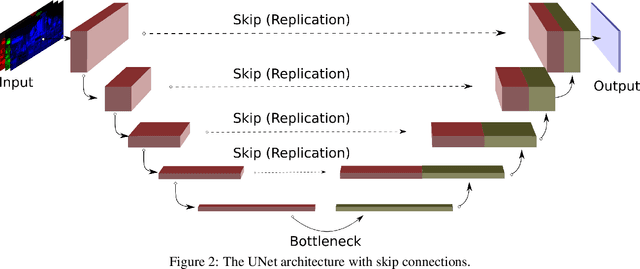

Convolutional Neural Networks (CNNs) are the current de-facto approach used for many imaging tasks due to their high learning capacity as well as their architectural qualities. The ubiquitous UNet architecture provides an efficient and multi-scale solution that combines local and global information. Despite the success of UNet architectures, the use of upsampling layers can cause checkerboard artefacts or blurring. In this work, a method for assessing the structural biases of UNets and the effects these have on the outputs is presented, characterising their impact in the Fourier domain. A new upsampling module is then proposed, based on a novel generalisation of the Guided Image Filter, that provides spectrally consistent outputs when used in a UNet architecture, forming the Guided UNet (GUNet). The GUNet architecture is evaluated quantitatively and qualitatively in an example application of dynamic range expansion for high dynamic range imaging. The proposed method provides higher fidelity results, while executing faster and consuming less memory than other dedicated architectures that avoid upsampling.
ExpandNet: A Deep Convolutional Neural Network for High Dynamic Range Expansion from Low Dynamic Range Content
Mar 06, 2018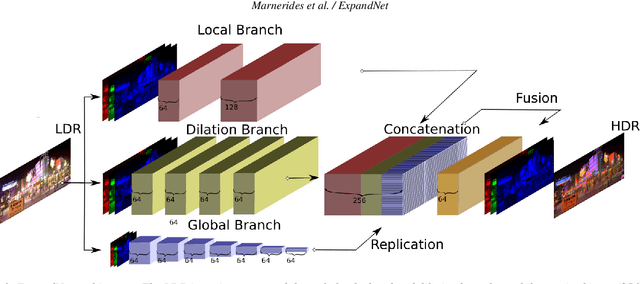
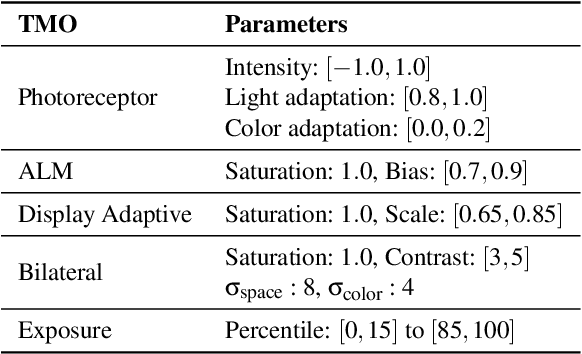
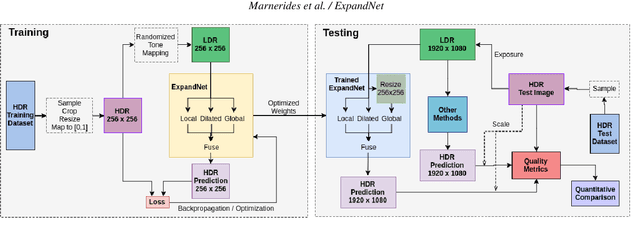
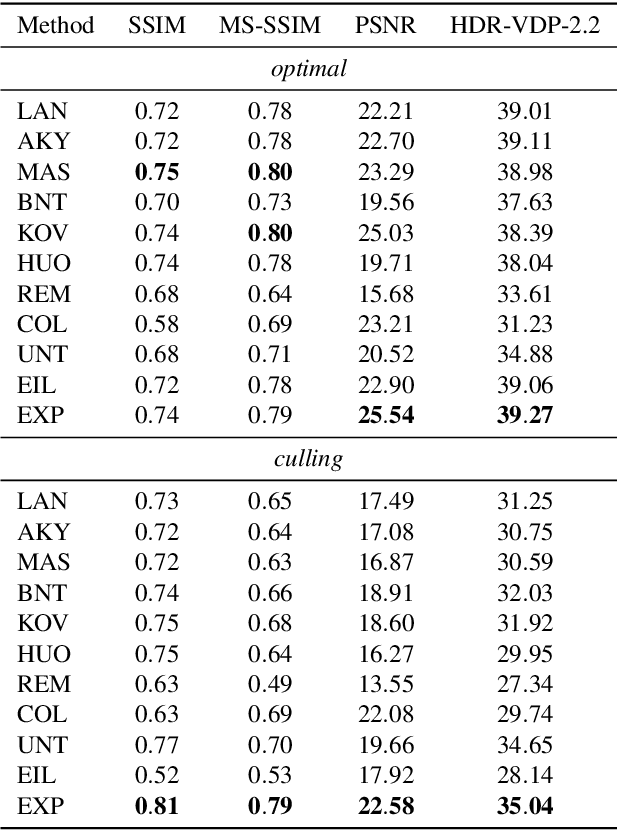
High dynamic range (HDR) imaging provides the capability of handling real world lighting as opposed to the traditional low dynamic range (LDR) which struggles to accurately represent images with higher dynamic range. However, most imaging content is still available only in LDR. This paper presents a method for generating HDR content from LDR content based on deep Convolutional Neural Networks (CNNs) termed ExpandNet. ExpandNet accepts LDR images as input and generates images with an expanded range in an end-to-end fashion. The model attempts to reconstruct missing information that was lost from the original signal due to quantization, clipping, tone mapping or gamma correction. The added information is reconstructed from learned features, as the network is trained in a supervised fashion using a dataset of HDR images. The approach is fully automatic and data driven; it does not require any heuristics or human expertise. ExpandNet uses a multiscale architecture which avoids the use of upsampling layers to improve image quality. The method performs well compared to expansion/inverse tone mapping operators quantitatively on multiple metrics, even for badly exposed inputs.