 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Perception for 3D Object Detection in Driving Scenarios using Infrastructure Sensors
Paper and Code
Dec 18, 2019
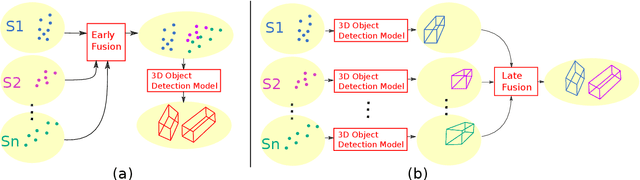


The perception system of an autonomous vehicle is responsible for mapping sensor observations into a semantic description of the vehicle's environment. 3D object detection is a common function within this system and outputs a list of 3D bounding boxes around objects of interest. Various 3D object detection methods have relied on fusion of different sensor modalities to overcome limitations of individual sensors. However, occlusion, limited field-of-view and low-point density of the sensor data cannot be reliably and cost-effectively addressed by multi-modal sensing from a single point of view. Alternatively, cooperative perception incorporates information from spatially diverse sensors distributed around the environment as a way to mitigate these limitations. This paper proposes two schemes for cooperative 3D object detection. The early fusion scheme combines point clouds from multiple spatially diverse sensing points of view before detection. In contrast, the late fusion scheme fuses the independently estimated bounding boxes from multiple spatially diverse sensors. We evaluate the performance of both schemes using a synthetic cooperative dataset created in two complex driving scenarios, a T-junction and a roundabout. The evaluation show that the early fusion approach outperforms late fusion by a significant margin at the cost of higher communication bandwidth. The results demonstrate that cooperative perception can recall more than 95% of the objects as opposed to 30% for single-point sensing in the most challenging scenario. To provide practical insights into the deployment of such system, we report how the number of sensors and their configuration impact the detection performance of the system.