 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Driven Active Learning for Image Segmentation in Underwater Inspection
Mar 20, 2024Active learning aims to select the minimum amount of data to train a model that performs similarly to a model trained with the entire dataset. We study the potential of active learning for image segmentation in underwater infrastructure inspection tasks, where large amounts of data are typically collected. The pipeline inspection images are usually semantically repetitive but with great variations in quality. We use mutual information as the acquisition function, calculated using Monte Carlo dropout. To assess the effectiveness of the framework, DenseNet and HyperSeg are trained with the CamVid dataset using active learning. In addition, HyperSeg is trained with a pipeline inspection dataset of over 50,000 images. For the pipeline dataset, HyperSeg with active learning achieved 67.5% meanIoU using 12.5% of the data, and 61.4% with the same amount of randomly selected images. This shows that using active learning for segmentation models in underwater inspection tasks can lower the cost significantly.
Uncalibrated Non-Rigid Factorisation by Independent Subspace Analysis
Nov 22, 2018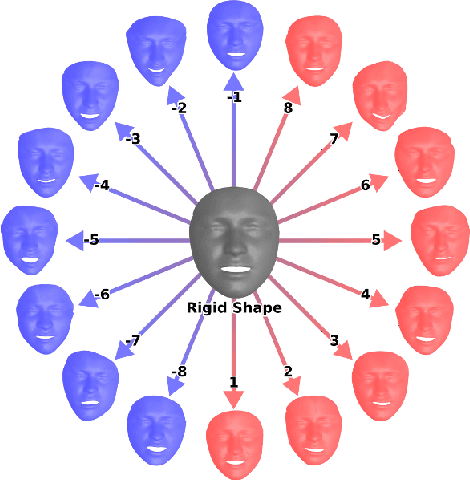

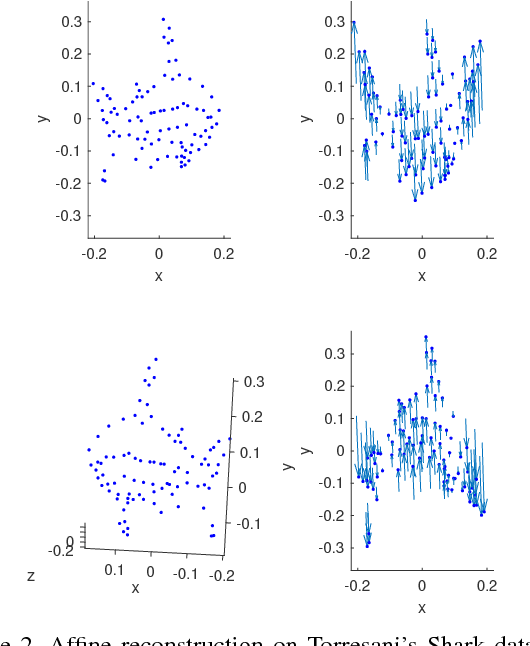
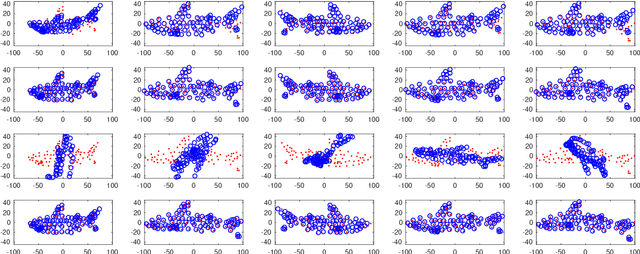
We propose a general, prior-free approach for the uncalibrated non-rigid structure-from-motion problem for modelling and analysis of non-rigid objects such as human faces. The word general refers to an approach that recovers the non-rigid affine structure and motion from 2D point correspondences by assuming that (1) the non-rigid shapes are generated by a linear combination of rigid 3D basis shapes, (2) that the non-rigid shapes are affine in nature, i.e., they can be modelled as deviations from the mean, rigid shape, (3) and that the basis shapes are statistically independent. In contrast to the majority of existing works, no prior information is assumed for the structure and motion apart from the assumption the that underlying basis shapes are statistically independent. The independent 3D shape bases are recovered by independent subspace analysis (ISA). Likewise, in contrast to the most previous approaches, no calibration information is assumed for affine cameras; the reconstruction is solved up to a global affine ambiguity that makes our approach simple but efficient. In the experiments, we evaluated the method with several standard data sets including a real face expression data set of 7200 faces with 2D point correspondences and unknown 3D structure and motion for which we obtained promising results.