 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling of Underwater Vehicles using Physics-Informed Neural Networks with Control
Apr 28, 2025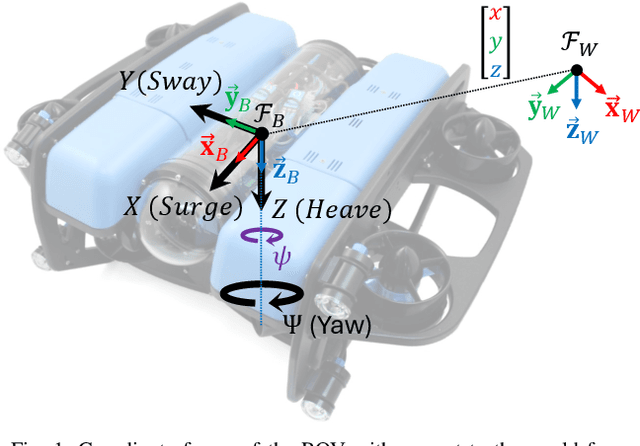
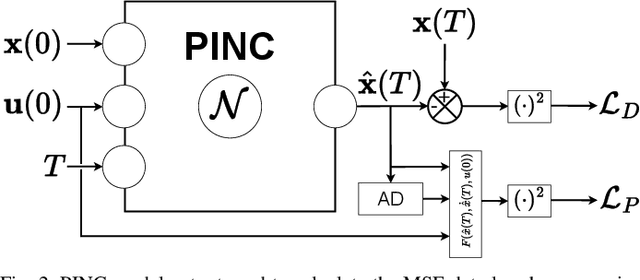
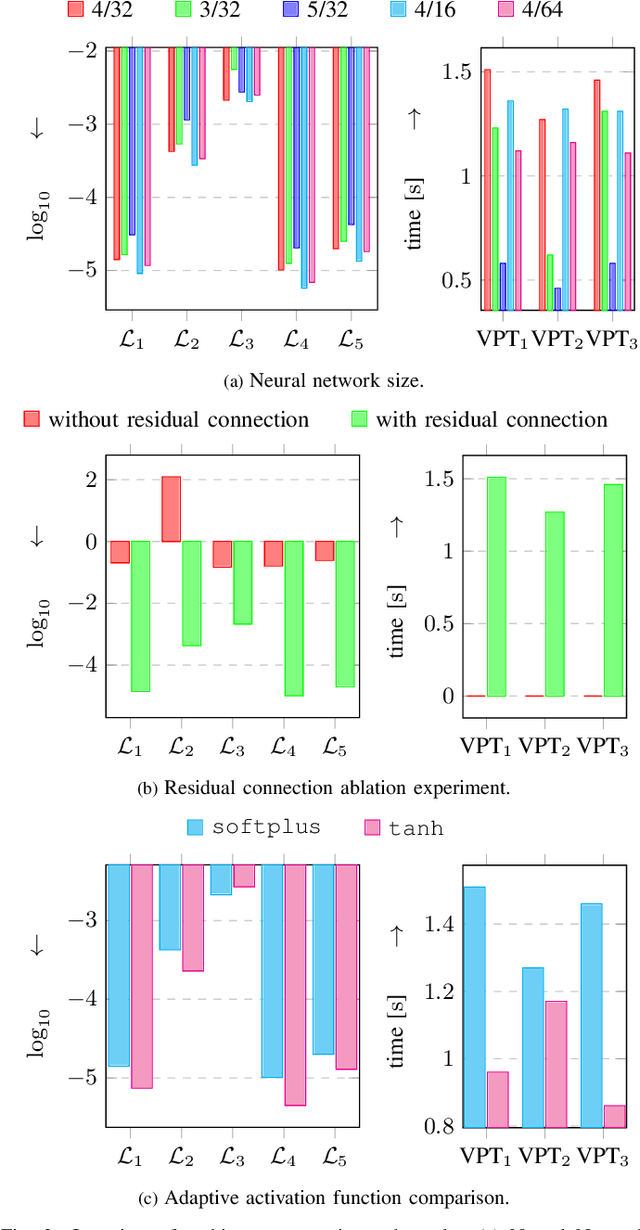
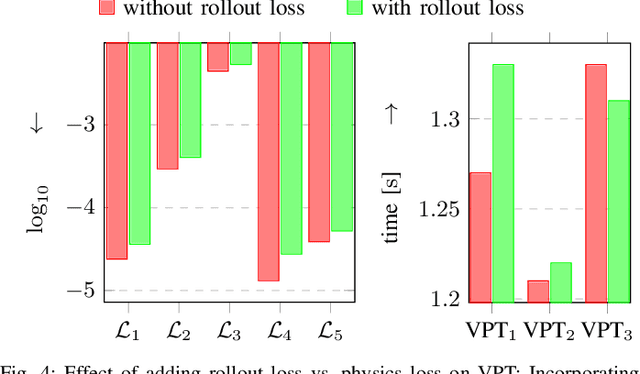
Physics-informed neural networks (PINNs) integrate physical laws with data-driven models to improve generalization and sample efficiency. This work introduces an open-source implementation of the Physics-Informed Neural Network with Control (PINC) framework, designed to model the dynamics of an underwater vehicle. Using initial states, control actions, and time inputs, PINC extends PINNs to enable physically consistent transitions beyond the training domain. Various PINC configurations are tested, including differing loss functions, gradient-weighting schemes, and hyperparameters. Validation on a simulated underwater vehicle demonstrates more accurate long-horizon predictions compared to a non-physics-informed baseline
Monocular visual simultaneous localization and mapping: (r)evolution from geometry to deep learning-based pipelines
Mar 04, 2025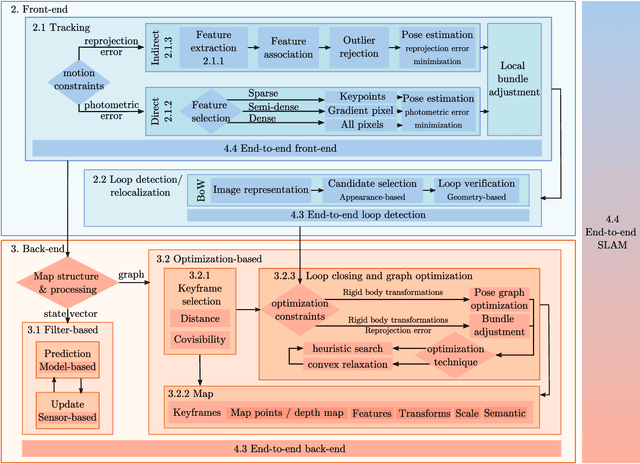
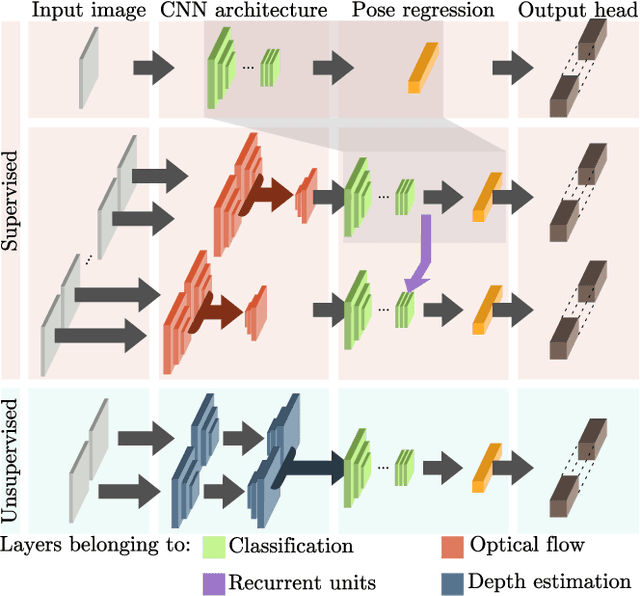
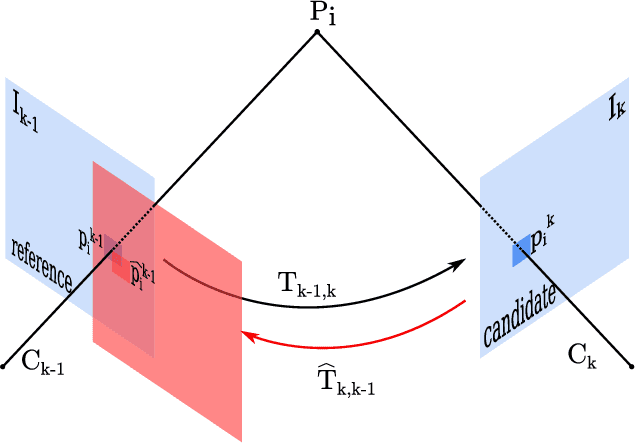
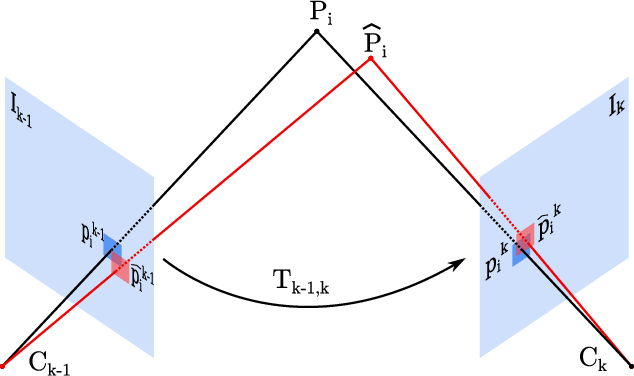
With the rise of deep learning, there is a fundamental change in visual SLAM algorithms toward developing different modules trained as end-to-end pipelines. However, regardless of the implementation domain, visual SLAM's performance is subject to diverse environmental challenges, such as dynamic elements in outdoor environments, harsh imaging conditions in underwater environments, or blurriness in high-speed setups. These environmental challenges need to be identified to study the real-world viability of SLAM implementations. Motivated by the aforementioned challenges, this paper surveys the current state of visual SLAM algorithms according to the two main frameworks: geometry-based and learning-based SLAM. First, we introduce a general formulation of the SLAM pipeline that includes most of the implementations in the literature. Second, those implementations are classified and surveyed for geometry and learning-based SLAM. After that, environment-specific challenges are formulated to enable experimental evaluation of the resilience of different visual SLAM classes to varying imaging conditions. We address two significant issues in surveying visual SLAM, providing (1) a consistent classification of visual SLAM pipelines and (2) a robust evaluation of their performance under different deployment conditions. Finally, we give our take on future opportunities for visual SLAM implementations.
Uncertainty Driven Active Learning for Image Segmentation in Underwater Inspection
Mar 20, 2024Active learning aims to select the minimum amount of data to train a model that performs similarly to a model trained with the entire dataset. We study the potential of active learning for image segmentation in underwater infrastructure inspection tasks, where large amounts of data are typically collected. The pipeline inspection images are usually semantically repetitive but with great variations in quality. We use mutual information as the acquisition function, calculated using Monte Carlo dropout. To assess the effectiveness of the framework, DenseNet and HyperSeg are trained with the CamVid dataset using active learning. In addition, HyperSeg is trained with a pipeline inspection dataset of over 50,000 images. For the pipeline dataset, HyperSeg with active learning achieved 67.5% meanIoU using 12.5% of the data, and 61.4% with the same amount of randomly selected images. This shows that using active learning for segmentation models in underwater inspection tasks can lower the cost significantly.
Mission Planning and Safety Assessment for Pipeline Inspection Using Autonomous Underwater Vehicles: A Framework based on Behavior Trees
Feb 06, 2024The recent advance in autonomous underwater robotics facilitates autonomous inspection tasks of offshore infrastructure. However, current inspection missions rely on predefined plans created offline, hampering the flexibility and autonomy of the inspection vehicle and the mission's success in case of unexpected events. In this work, we address these challenges by proposing a framework encompassing the modeling and verification of mission plans through Behavior Trees (BTs). This framework leverages the modularity of BTs to model onboard reactive behaviors, thus enabling autonomous plan executions, and uses BehaVerify to verify the mission's safety. Moreover, as a use case of this framework, we present a novel AI-enabled algorithm that aims for efficient, autonomous pipeline camera data collection. In a simulated environment, we demonstrate the framework's application to our proposed pipeline inspection algorithm. Our framework marks a significant step forward in the field of autonomous underwater robotics, promising to enhance the safety and success of underwater missions in practical, real-world applications. https://github.com/remaro-network/pipe_inspection_mission
SubPipe: A Submarine Pipeline Inspection Dataset for Segmentation and Visual-inertial Localization
Feb 06, 2024This paper presents SubPipe, an underwater dataset for SLAM, object detection, and image segmentation. SubPipe has been recorded using a \gls{LAUV}, operated by OceanScan MST, and carrying a sensor suite including two cameras, a side-scan sonar, and an inertial navigation system, among other sensors. The AUV has been deployed in a pipeline inspection environment with a submarine pipe partially covered by sand. The AUV's pose ground truth is estimated from the navigation sensors. The side-scan sonar and RGB images include object detection and segmentation annotations, respectively. State-of-the-art segmentation, object detection, and SLAM methods are benchmarked on SubPipe to demonstrate the dataset's challenges and opportunities for leveraging computer vision algorithms. To the authors' knowledge, this is the first annotated underwater dataset providing a real pipeline inspection scenario. The dataset and experiments are publicly available online at https://github.com/remaro-network/SubPipe-dataset
UNav-Sim: A Visually Realistic Underwater Robotics Simulator and Synthetic Data-generation Framework
Oct 18, 2023



Underwater robotic surveys can be costly due to the complex working environment and the need for various sensor modalities. While underwater simulators are essential, many existing simulators lack sufficient rendering quality, restricting their ability to transfer algorithms from simulation to real-world applications. To address this limitation, we introduce UNav-Sim, which, to the best of our knowledge, is the first simulator to incorporate the efficient, high-detail rendering of Unreal Engine 5 (UE5). UNav-Sim is open-source and includes an autonomous vision-based navigation stack. By supporting standard robotics tools like ROS, UNav-Sim enables researchers to develop and test algorithms for underwater environments efficiently.
UnsuperPoint: End-to-end Unsupervised Interest Point Detector and Descriptor
Jul 09, 2019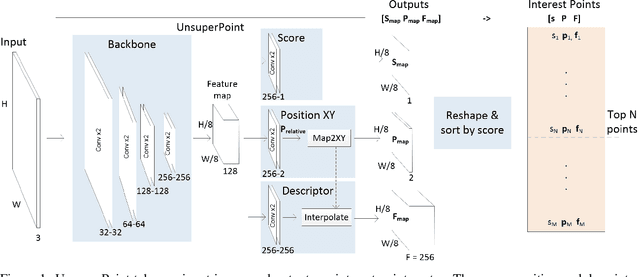
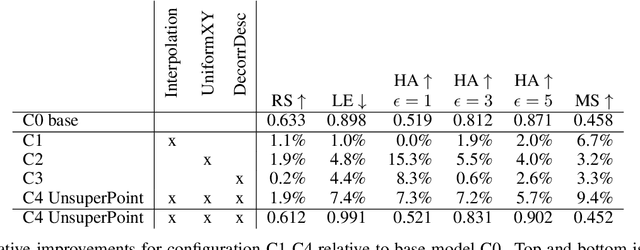
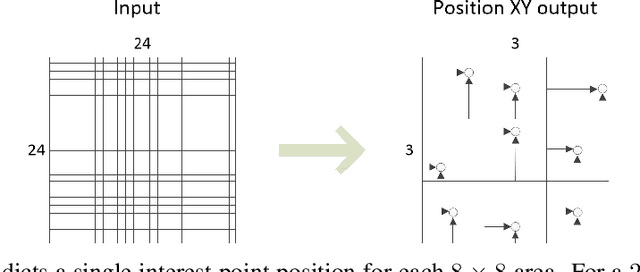
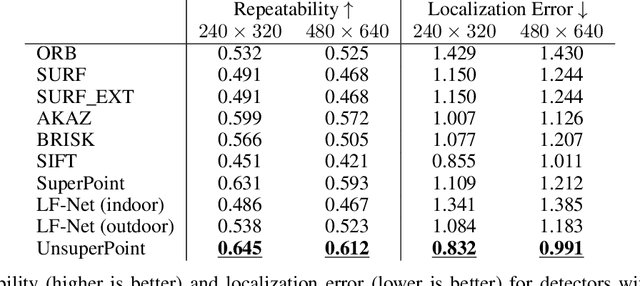
It is hard to create consistent ground truth data for interest points in natural images, since interest points are hard to define clearly and consistently for a human annotator. This makes interest point detectors non-trivial to build. In this work, we introduce an unsupervised deep learning-based interest point detector and descriptor. Using a self-supervised approach, we utilize a siamese network and a novel loss function that enables interest point scores and positions to be learned automatically. The resulting interest point detector and descriptor is UnsuperPoint. We use regression of point positions to 1) make UnsuperPoint end-to-end trainable and 2) to incorporate non-maximum suppression in the model. Unlike most trainable detectors, it requires no generation of pseudo ground truth points, no structure-from-motion-generated representations and the model is learned from only one round of training. Furthermore, we introduce a novel loss function to regularize network predictions to be uniformly distributed. UnsuperPoint runs in real-time with 323 frames per second (fps) at a resolution of $224\times320$ and 90 fps at $480\times640$. It is comparable or better than state-of-the-art performance when measured for speed, repeatability, localization, matching score and homography estimation on the HPatch dataset.