 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoAlign: Beyond Semantics with State-Guided Spatial Alignment in VLA Models
Jun 02, 2026Current Vision--Language--Action (VLA) models often optimize for semantic grounding, whereas executable manipulation requires geometry-aware spatial alignment and dynamic affordance selection. We introduce GeoAlign, a state-guided spatial alignment architecture for VLA policy learning. GeoAlign post-trains an RGB geometry branch with robot-domain RGB-D supervision, yielding RGB-derived Geometry-Enhanced Post-Trained (GEP) features for policy rollout. The robot's proprioceptive state queries the GEP feature grid, producing compact, phase-dependent geometry tokens for action prediction. GeoAlign achieves 99.0% on LIBERO, 85.3% across three SimplerEnv-Fractal tasks, and 78.8% on eight geometry-critical real-world ALOHA tasks, with ablations confirming the value of geometry post-training and proprioceptive-state-guided querying.
Fine-Grained Visual Classification via Simultaneously Learning of Multi-regional Multi-grained Features
Jan 31, 2021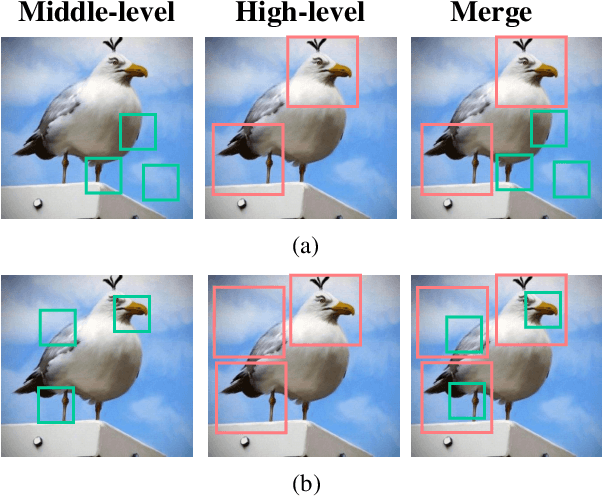
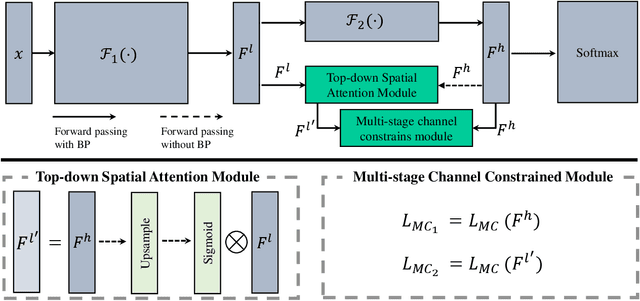
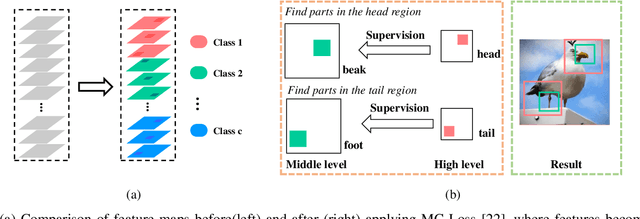

Fine-grained visual classification is a challenging task that recognizes the sub-classes belonging to the same meta-class. Large inter-class similarity and intra-class variance is the main challenge of this task. Most exiting methods try to solve this problem by designing complex model structures to explore more minute and discriminative regions. In this paper, we argue that mining multi-regional multi-grained features is precisely the key to this task. Specifically, we introduce a new loss function, termed top-down spatial attention loss (TDSA-Loss), which contains a multi-stage channel constrained module and a top-down spatial attention module. The multi-stage channel constrained module aims to make the feature channels in different stages category-aligned. Meanwhile, the top-down spatial attention module uses the attention map generated by high-level aligned feature channels to make middle-level aligned feature channels to focus on particular regions. Finally, we can obtain multiple discriminative regions on high-level feature channels and obtain multiple more minute regions within these discriminative regions on middle-level feature channels. In summary, we obtain multi-regional multi-grained features. Experimental results over four widely used fine-grained image classification datasets demonstrate the effectiveness of the proposed method. Ablative studies further show the superiority of two modules in the proposed method. Codes are available at: https://github.com/dongliangchang/Top-Down-Spatial-Attention-Loss.
Dilated-Scale-Aware Attention ConvNet For Multi-Class Object Counting
Dec 15, 2020
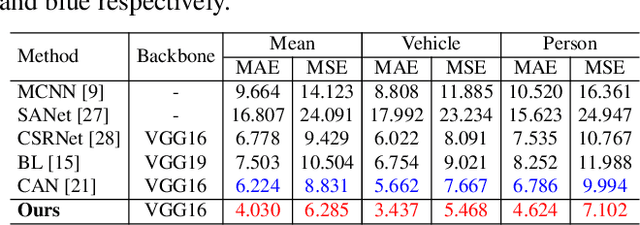
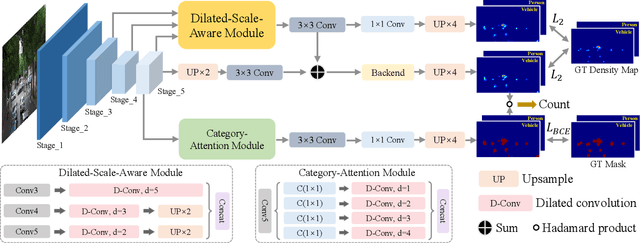

Object counting aims to estimate the number of objects in images. The leading counting approaches focus on the single category counting task and achieve impressive performance. Note that there are multiple categories of objects in real scenes. Multi-class object counting expands the scope of application of object counting task. The multi-target detection task can achieve multi-class object counting in some scenarios. However, it requires the dataset annotated with bounding boxes. Compared with the point annotations in mainstream object counting issues, the coordinate box-level annotations are more difficult to obtain. In this paper, we propose a simple yet efficient counting network based on point-level annotations. Specifically, we first change the traditional output channel from one to the number of categories to achieve multiclass counting. Since all categories of objects use the same feature extractor in our proposed framework, their features will interfere mutually in the shared feature space. We further design a multi-mask structure to suppress harmful interaction among objects. Extensive experiments on the challenging benchmarks illustrate that the proposed method achieves state-of-the-art counting performance.
Your "Labrador" is My "Dog": Fine-Grained, or Not
Nov 18, 2020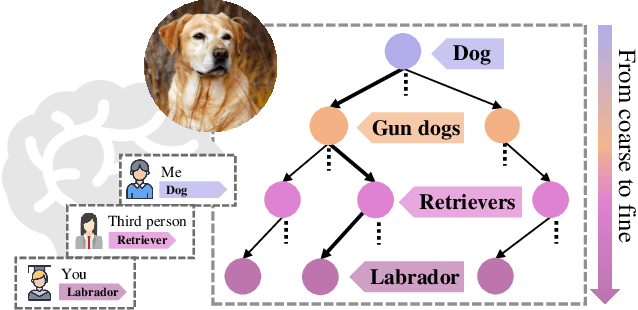

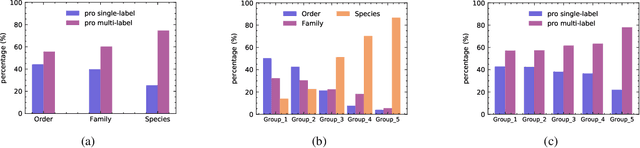
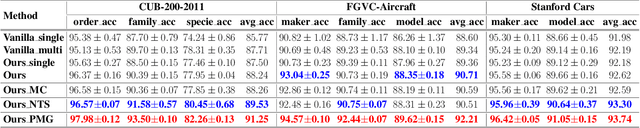
Whether what you see in Figure 1 is a "labrador" or a "dog", is the question we ask in this paper. While fine-grained visual classification (FGVC) strives to arrive at the former, for the majority of us non-experts just "dog" would probably suffice. The real question is therefore -- how can we tailor for different fine-grained definitions under divergent levels of expertise. For that, we re-envisage the traditional setting of FGVC, from single-label classification, to that of top-down traversal of a pre-defined coarse-to-fine label hierarchy -- so that our answer becomes "dog"-->"gun dog"-->"retriever"-->"labrador". To approach this new problem, we first conduct a comprehensive human study where we confirm that most participants prefer multi-granularity labels, regardless whether they consider themselves experts. We then discover the key intuition that: coarse-level label prediction exacerbates fine-grained feature learning, yet fine-level feature betters the learning of coarse-level classifier. This discovery enables us to design a very simple albeit surprisingly effective solution to our new problem, where we (i) leverage level-specific classification heads to disentangle coarse-level features with fine-grained ones, and (ii) allow finer-grained features to participate in coarser-grained label predictions, which in turn helps with better disentanglement. Experiments show that our method achieves superior performance in the new FGVC setting, and performs better than state-of-the-art on traditional single-label FGVC problem as well. Thanks to its simplicity, our method can be easily implemented on top of any existing FGVC frameworks and is parameter-free.