 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDR-Empowered Environment Sensing Design and Experimental Validation Using OTFS-ISAC Signals
Jul 02, 2025This paper investigates the system design and experimental validation of integrated sensing and communication (ISAC) for environmental sensing, which is expected to be a critical enabler for next-generation wireless networks. We advocate exploiting orthogonal time frequency space (OTFS) modulation for its inherent sparsity and stability in delay-Doppler (DD) domain channels, facilitating a low-overhead environment sensing design. Moreover, a comprehensive environmental sensing framework is developed, encompassing DD domain channel estimation, target localization, and experimental validation. In particular, we first explore the OTFS channel estimation in the presence of fractional delay and Doppler shifts. Given the estimated parameters, we propose a three-ellipse positioning algorithm to localize the target's position, followed by determining the mobile transmitter's velocity. Additionally, to evaluate the performance of our proposed design, we conduct extensive simulations and experiments using a software-defined radio (SDR)-based platform with universal software radio peripheral (USRP). The experimental validations demonstrate that our proposed approach outperforms the benchmarks in terms of localization accuracy and velocity estimation, confirming its effectiveness in practical environmental sensing applications.
KaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025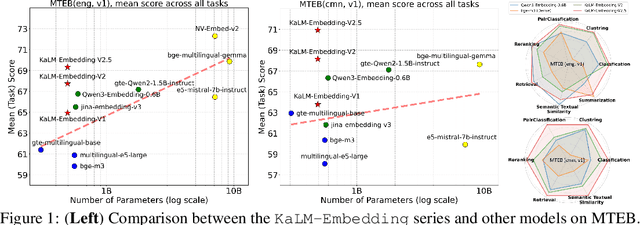
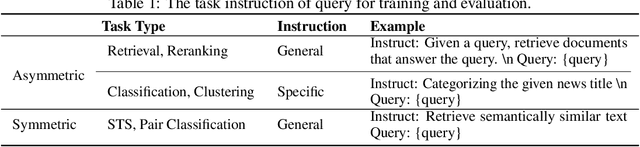


In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.
KaLM-Embedding: Superior Training Data Brings A Stronger Embedding Model
Jan 03, 2025



As retrieval-augmented generation prevails in large language models, embedding models are becoming increasingly crucial. Despite the growing number of general embedding models, prior work often overlooks the critical role of training data quality. In this work, we introduce KaLM-Embedding, a general multilingual embedding model that leverages a large quantity of cleaner, more diverse, and domain-specific training data. Our model has been trained with key techniques proven to enhance performance: (1) persona-based synthetic data to create diversified examples distilled from LLMs, (2) ranking consistency filtering to remove less informative samples, and (3) semi-homogeneous task batch sampling to improve training efficacy. Departing from traditional BERT-like architectures, we adopt Qwen2-0.5B as the pre-trained model, facilitating the adaptation of auto-regressive language models for general embedding tasks. Extensive evaluations of the MTEB benchmark across multiple languages show that our model outperforms others of comparable size, setting a new standard for multilingual embedding models with <1B parameters.
Using Large Language Model to Solve and Explain Physics Word Problems Approaching Human Level
Sep 20, 2023



Our work demonstrates that large language model (LLM) pre-trained on texts can not only solve pure math word problems, but also physics word problems, whose solution requires calculation and inference based on prior physical knowledge. We collect and annotate the first physics word problem dataset-PhysQA, which contains over 1000 junior high school physics word problems (covering Kinematics, Mass&Density, Mechanics, Heat, Electricity). Then we use OpenAI' s GPT3.5 to generate the answer of these problems and found that GPT3.5 could automatically solve 49.3% of the problems through zero-shot learning and 73.2% through few-shot learning. This result demonstrates that by using similar problems and their answers as prompt, LLM could solve elementary physics word problems approaching human level performance. In addition to solving problems, GPT3.5 can also summarize the knowledge or topics covered by the problems, provide relevant explanations, and generate new physics word problems based on the input. Our work is the first research to focus on the automatic solving, explanation, and generation of physics word problems across various types and scenarios, and we achieve an acceptable and state-of-the-art accuracy. This underscores the potential of LLMs for further applications in secondary education.