 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025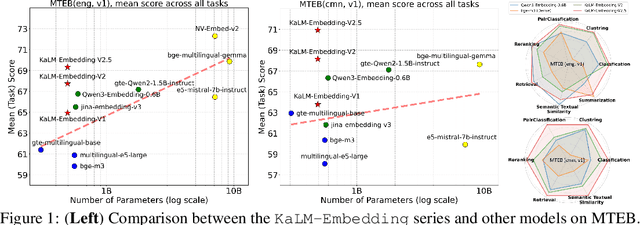


In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.
Take Off the Training Wheels Progressive In-Context Learning for Effective Alignment
Mar 13, 2025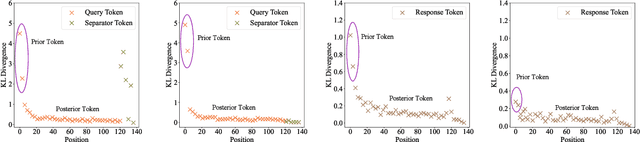
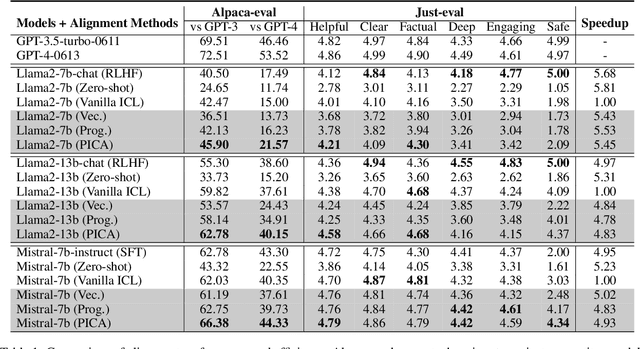
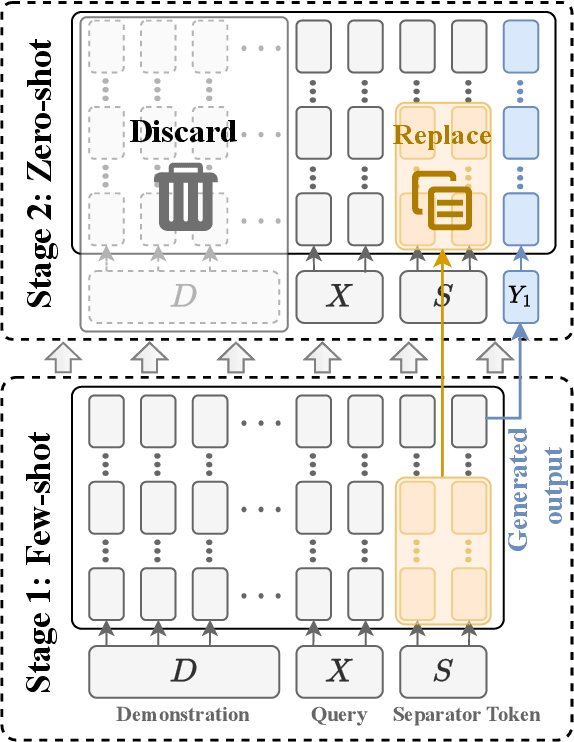
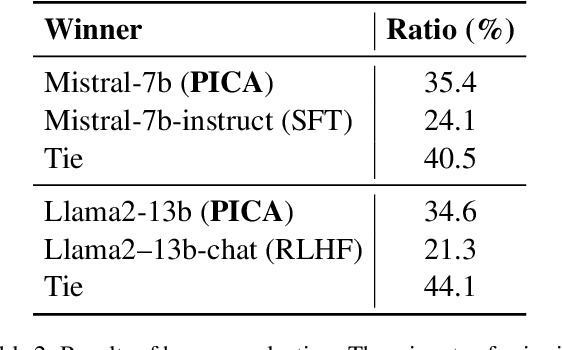
Recent studies have explored the working mechanisms of In-Context Learning (ICL). However, they mainly focus on classification and simple generation tasks, limiting their broader application to more complex generation tasks in practice. To address this gap, we investigate the impact of demonstrations on token representations within the practical alignment tasks. We find that the transformer embeds the task function learned from demonstrations into the separator token representation, which plays an important role in the generation of prior response tokens. Once the prior response tokens are determined, the demonstrations become redundant.Motivated by this finding, we propose an efficient Progressive In-Context Alignment (PICA) method consisting of two stages. In the first few-shot stage, the model generates several prior response tokens via standard ICL while concurrently extracting the ICL vector that stores the task function from the separator token representation. In the following zero-shot stage, this ICL vector guides the model to generate responses without further demonstrations.Extensive experiments demonstrate that our PICA not only surpasses vanilla ICL but also achieves comparable performance to other alignment tuning methods. The proposed training-free method reduces the time cost (e.g., 5.45+) with improved alignment performance (e.g., 6.57+). Consequently, our work highlights the application of ICL for alignment and calls for a deeper understanding of ICL for complex generations. The code will be available at https://github.com/HITsz-TMG/PICA.
KaLM-Embedding: Superior Training Data Brings A Stronger Embedding Model
Jan 03, 2025



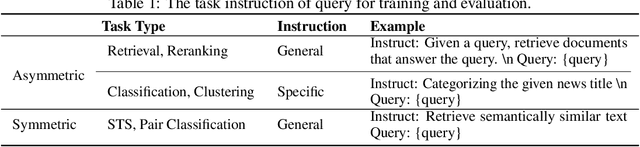
As retrieval-augmented generation prevails in large language models, embedding models are becoming increasingly crucial. Despite the growing number of general embedding models, prior work often overlooks the critical role of training data quality. In this work, we introduce KaLM-Embedding, a general multilingual embedding model that leverages a large quantity of cleaner, more diverse, and domain-specific training data. Our model has been trained with key techniques proven to enhance performance: (1) persona-based synthetic data to create diversified examples distilled from LLMs, (2) ranking consistency filtering to remove less informative samples, and (3) semi-homogeneous task batch sampling to improve training efficacy. Departing from traditional BERT-like architectures, we adopt Qwen2-0.5B as the pre-trained model, facilitating the adaptation of auto-regressive language models for general embedding tasks. Extensive evaluations of the MTEB benchmark across multiple languages show that our model outperforms others of comparable size, setting a new standard for multilingual embedding models with <1B parameters.
CMT: A Memory Compression Method for Continual Knowledge Learning of Large Language Models
Dec 10, 2024



Large Language Models (LLMs) need to adapt to the continuous changes in data, tasks, and user preferences. Due to their massive size and the high costs associated with training, LLMs are not suitable for frequent retraining. However, updates are necessary to keep them in sync with rapidly evolving human knowledge. To address these challenges, this paper proposes the Compression Memory Training (CMT) method, an efficient and effective online adaptation framework for LLMs that features robust knowledge retention capabilities. Inspired by human memory mechanisms, CMT compresses and extracts information from new documents to be stored in a memory bank. When answering to queries related to these new documents, the model aggregates these document memories from the memory bank to better answer user questions. The parameters of the LLM itself do not change during training and inference, reducing the risk of catastrophic forgetting. To enhance the encoding, retrieval, and aggregation of memory, we further propose three new general and flexible techniques, including memory-aware objective, self-matching and top-aggregation. Extensive experiments conducted on three continual learning datasets (i.e., StreamingQA, SQuAD and ArchivalQA) demonstrate that the proposed method improves model adaptability and robustness across multiple base LLMs (e.g., +4.07 EM & +4.19 F1 in StreamingQA with Llama-2-7b).
FunnelRAG: A Coarse-to-Fine Progressive Retrieval Paradigm for RAG
Oct 14, 2024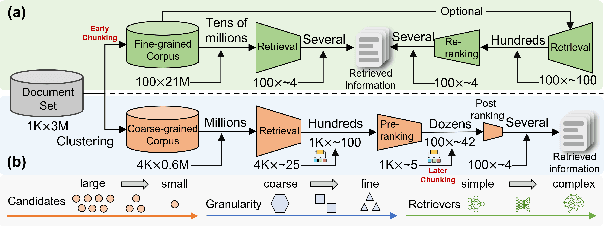

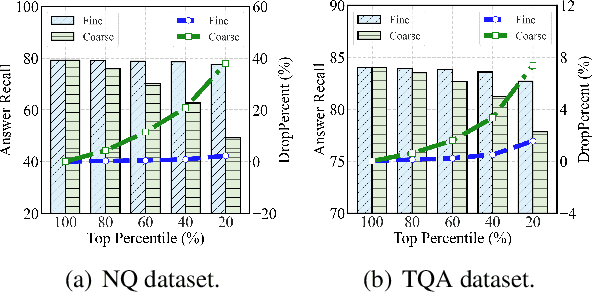
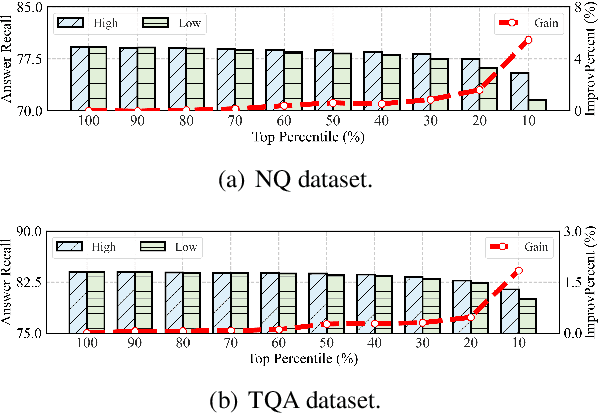
Retrieval-Augmented Generation (RAG) prevails in Large Language Models. It mainly consists of retrieval and generation. The retrieval modules (a.k.a. retrievers) aim to find useful information used to facilitate generation modules (a.k.a. generators). As such, generators' performance largely depends on the effectiveness and efficiency of retrievers. However, the retrieval paradigm that we design and use remains flat, which treats the retrieval procedures as a one-off deal with constant granularity. Despite effectiveness, we argue that they suffer from two limitations: (1) flat retrieval exerts a significant burden on one retriever; (2) constant granularity limits the ceiling of retrieval performance. In this work, we propose a progressive retrieval paradigm with coarse-to-fine granularity for RAG, termed FunnelRAG, so as to balance effectiveness and efficiency. Specifically, FunnelRAG establishes a progressive retrieval pipeline by collaborating coarse-to-fine granularity, large-to-small quantity, and low-to-high capacity, which can relieve the burden on one retriever and also promote the ceiling of retrieval performance. Extensive experiments manifest that FunnelRAG achieves comparable retrieval performance while the time overhead is reduced by nearly 40 percent.
In-Context Learning State Vector with Inner and Momentum Optimization
Apr 17, 2024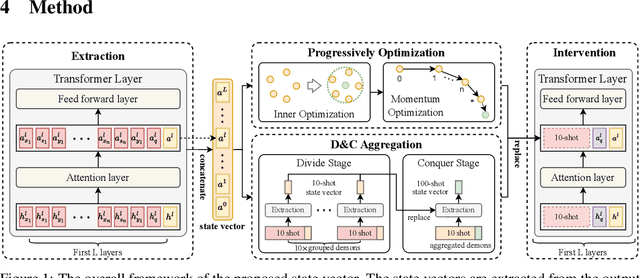
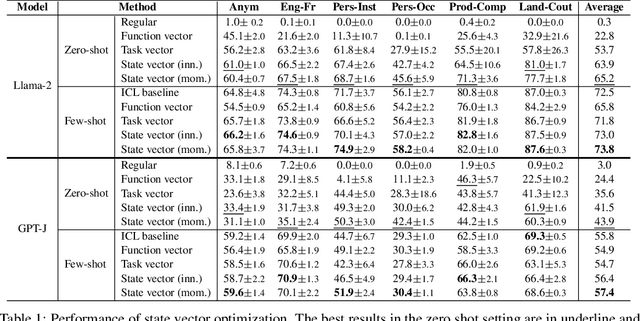
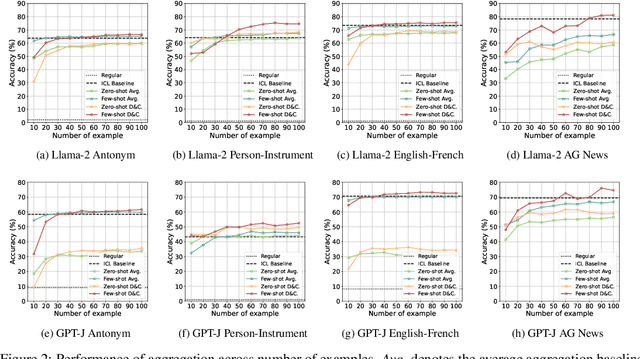
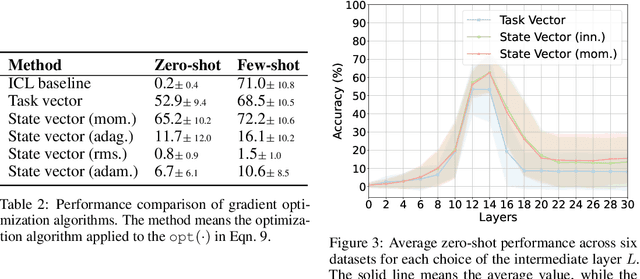
Large Language Models (LLMs) have exhibited an impressive ability to perform In-Context Learning (ICL) from only a few examples. Recent works have indicated that the functions learned by ICL can be represented through compressed vectors derived from the transformer. However, the working mechanisms and optimization of these vectors are yet to be thoroughly explored. In this paper, we address this gap by presenting a comprehensive analysis of these compressed vectors, drawing parallels to the parameters trained with gradient descent, and introduce the concept of state vector. Inspired by the works on model soup and momentum-based gradient descent, we propose inner and momentum optimization methods that are applied to refine the state vector progressively as test-time adaptation. Moreover, we simulate state vector aggregation in the multiple example setting, where demonstrations comprising numerous examples are usually too lengthy for regular ICL, and further propose a divide-and-conquer aggregation method to address this challenge. We conduct extensive experiments using Llama-2 and GPT-J in both zero-shot setting and few-shot setting. The experimental results show that our optimization method effectively enhances the state vector and achieves the state-of-the-art performance on diverse tasks. Code is available at https://github.com/HITsz-TMG/ICL-State-Vector
Improving Attributed Text Generation of Large Language Models via Preference Learning
Mar 27, 2024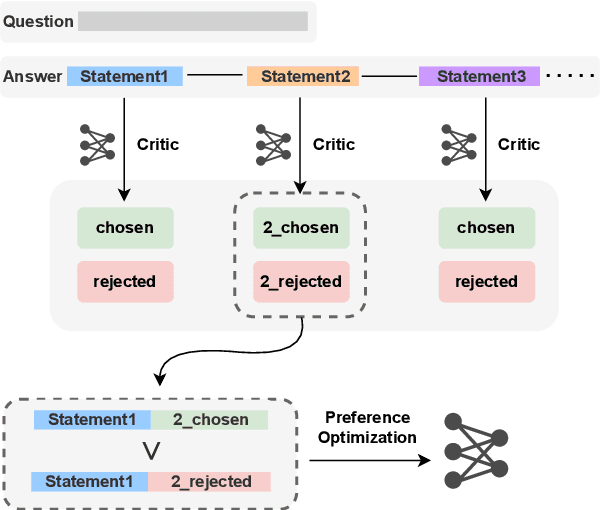
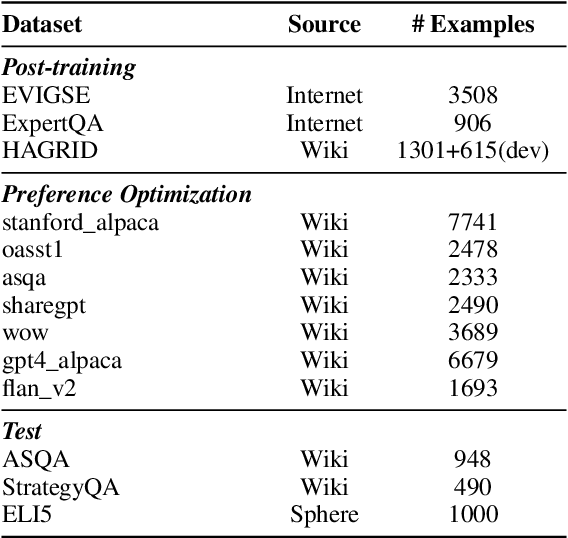
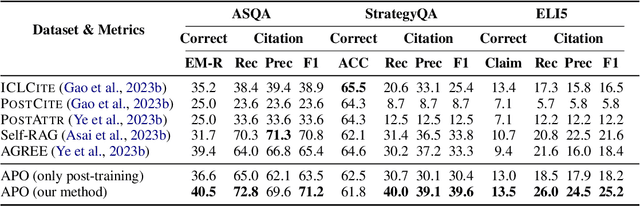
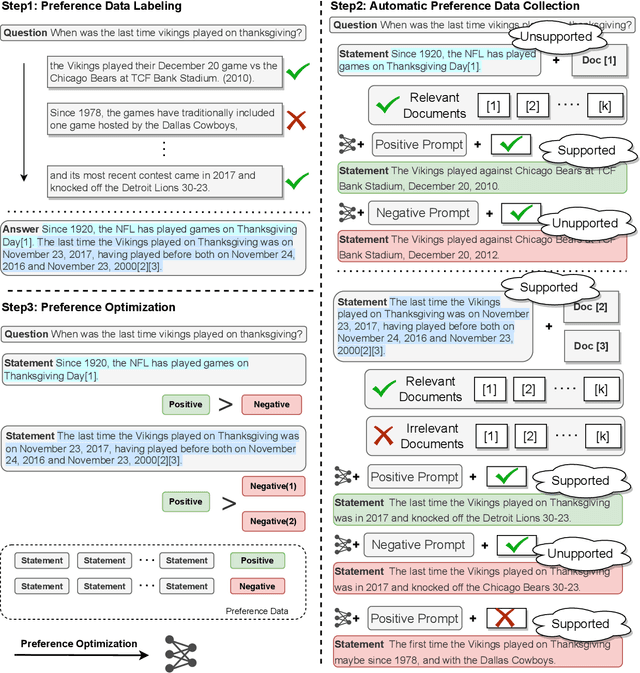
Large language models have been widely adopted in natural language processing, yet they face the challenge of generating unreliable content. Recent works aim to reduce misinformation and hallucinations by resorting to attribution as a means to provide evidence (i.e., citations). However, current attribution methods usually focus on the retrieval stage and automatic evaluation that neglect mirroring the citation mechanisms in human scholarly writing to bolster credibility. In this paper, we address these challenges by modelling the attribution task as preference learning and introducing an Automatic Preference Optimization (APO) framework. First, we create a curated collection for post-training with 6,330 examples by collecting and filtering from existing datasets. Second, considering the high cost of labelling preference data, we further propose an automatic method to synthesize attribution preference data resulting in 95,263 pairs. Moreover, inspired by the human citation process, we further propose a progressive preference optimization method by leveraging fine-grained information. Extensive experiments on three datasets (i.e., ASQA, StrategyQA, and ELI5) demonstrate that APO achieves state-of-the-art citation F1 with higher answer quality.
Does the Generator Mind its Contexts? An Analysis of Generative Model Faithfulness under Context Transfer
Feb 22, 2024



The present study introduces the knowledge-augmented generator, which is specifically designed to produce information that remains grounded in contextual knowledge, regardless of alterations in the context. Previous research has predominantly focused on examining hallucinations stemming from static input, such as in the domains of summarization or machine translation. However, our investigation delves into the faithfulness of generative question answering in the presence of dynamic knowledge. Our objective is to explore the existence of hallucinations arising from parametric memory when contextual knowledge undergoes changes, while also analyzing the underlying causes for their occurrence. In order to efficiently address this issue, we propose a straightforward yet effective measure for detecting such hallucinations. Intriguingly, our investigation uncovers that all models exhibit a tendency to generate previous answers as hallucinations. To gain deeper insights into the underlying causes of this phenomenon, we conduct a series of experiments that verify the critical role played by context in hallucination, both during training and testing, from various perspectives.
A Survey of Large Language Models Attribution
Nov 07, 2023Open-domain generative systems have gained significant attention in the field of conversational AI (e.g., generative search engines). This paper presents a comprehensive review of the attribution mechanisms employed by these systems, particularly large language models. Though attribution or citation improve the factuality and verifiability, issues like ambiguous knowledge reservoirs, inherent biases, and the drawbacks of excessive attribution can hinder the effectiveness of these systems. The aim of this survey is to provide valuable insights for researchers, aiding in the refinement of attribution methodologies to enhance the reliability and veracity of responses generated by open-domain generative systems. We believe that this field is still in its early stages; hence, we maintain a repository to keep track of ongoing studies at https://github.com/HITsz-TMG/awesome-llm-attributions.
Separate the Wheat from the Chaff: Model Deficiency Unlearning via Parameter-Efficient Module Operation
Aug 16, 2023Large language models (LLMs) have been widely used in various applications but are known to suffer from issues related to untruthfulness and toxicity. While parameter-efficient modules (PEMs) have demonstrated their effectiveness in equipping models with new skills, leveraging PEMs for deficiency unlearning remains underexplored. In this work, we propose a PEMs operation approach, namely Extraction-before-Subtraction (Ext-Sub), to enhance the truthfulness and detoxification of LLMs through the integration of ``expert'' PEM and ``anti-expert'' PEM. Remarkably, even anti-expert PEM possess valuable capabilities due to their proficiency in generating fabricated content, which necessitates language modeling and logical narrative competence. Rather than merely negating the parameters, our approach involves extracting and eliminating solely the deficiency capability within anti-expert PEM while preserving the general capabilities. To evaluate the effectiveness of our approach in terms of truthfulness and detoxification, we conduct extensive experiments on LLMs, encompassing additional abilities such as language modeling and mathematical reasoning. Our empirical results demonstrate that our approach effectively improves truthfulness and detoxification, while largely preserving the fundamental abilities of LLMs.