 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Seeing to Doing: Bridging Reasoning and Decision for Robotic Manipulation
May 13, 2025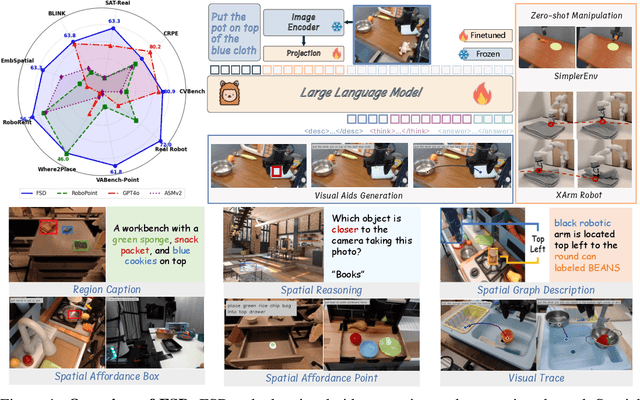

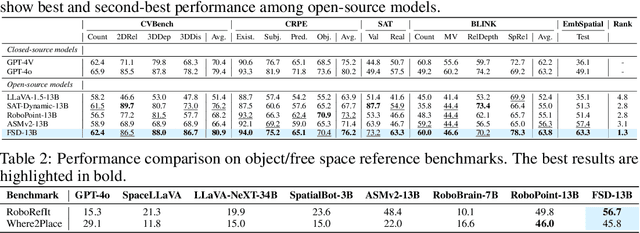
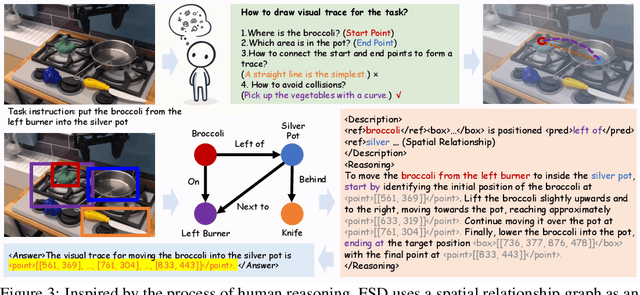
Achieving generalization in robotic manipulation remains a critical challenge, particularly for unseen scenarios and novel tasks. Current Vision-Language-Action (VLA) models, while building on top of general Vision-Language Models (VLMs), still fall short of achieving robust zero-shot performance due to the scarcity and heterogeneity prevalent in embodied datasets. To address these limitations, we propose FSD (From Seeing to Doing), a novel vision-language model that generates intermediate representations through spatial relationship reasoning, providing fine-grained guidance for robotic manipulation. Our approach combines a hierarchical data pipeline for training with a self-consistency mechanism that aligns spatial coordinates with visual signals. Through extensive experiments, we comprehensively validated FSD's capabilities in both "seeing" and "doing," achieving outstanding performance across 8 benchmarks for general spatial reasoning and embodied reference abilities, as well as on our proposed more challenging benchmark VABench. We also verified zero-shot capabilities in robot manipulation, demonstrating significant performance improvements over baseline methods in both SimplerEnv and real robot settings. Experimental results show that FSD achieves 54.1% success rate in SimplerEnv and 72% success rate across 8 real-world tasks, outperforming the strongest baseline by 30%.
Take Off the Training Wheels Progressive In-Context Learning for Effective Alignment
Mar 13, 2025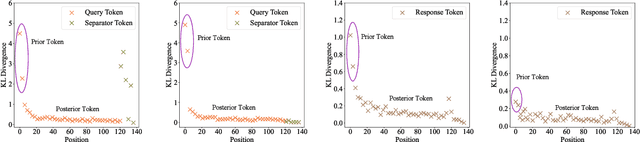
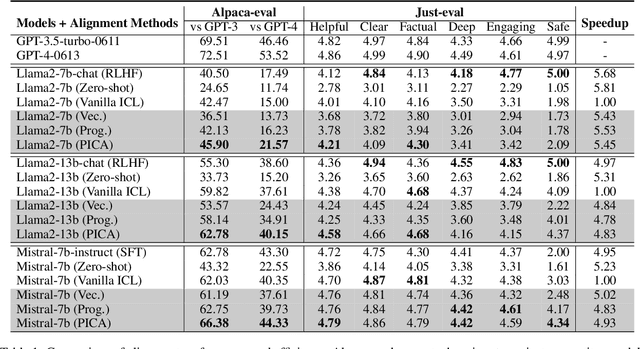
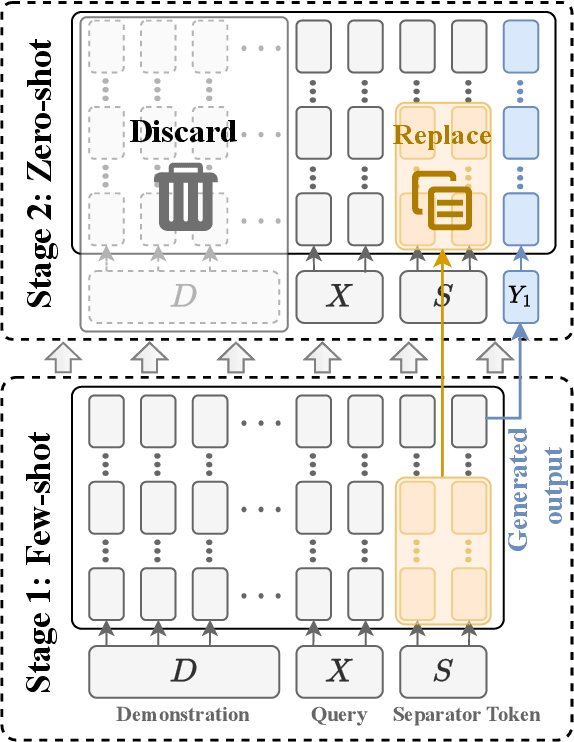
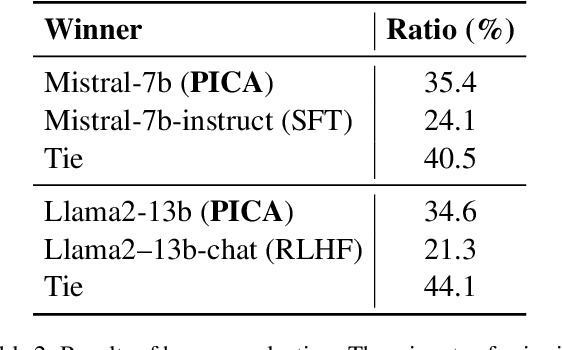
Recent studies have explored the working mechanisms of In-Context Learning (ICL). However, they mainly focus on classification and simple generation tasks, limiting their broader application to more complex generation tasks in practice. To address this gap, we investigate the impact of demonstrations on token representations within the practical alignment tasks. We find that the transformer embeds the task function learned from demonstrations into the separator token representation, which plays an important role in the generation of prior response tokens. Once the prior response tokens are determined, the demonstrations become redundant.Motivated by this finding, we propose an efficient Progressive In-Context Alignment (PICA) method consisting of two stages. In the first few-shot stage, the model generates several prior response tokens via standard ICL while concurrently extracting the ICL vector that stores the task function from the separator token representation. In the following zero-shot stage, this ICL vector guides the model to generate responses without further demonstrations.Extensive experiments demonstrate that our PICA not only surpasses vanilla ICL but also achieves comparable performance to other alignment tuning methods. The proposed training-free method reduces the time cost (e.g., 5.45+) with improved alignment performance (e.g., 6.57+). Consequently, our work highlights the application of ICL for alignment and calls for a deeper understanding of ICL for complex generations. The code will be available at https://github.com/HITsz-TMG/PICA.
SEER: Self-Aligned Evidence Extraction for Retrieval-Augmented Generation
Oct 15, 2024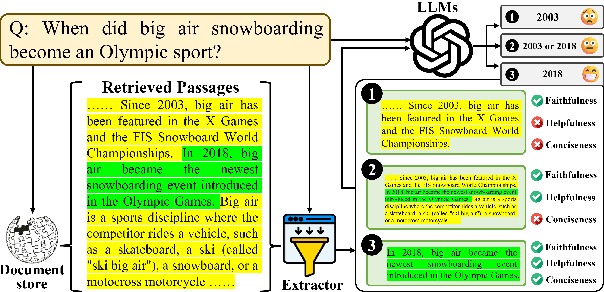
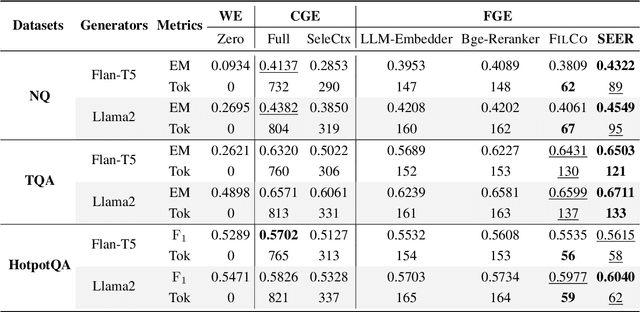
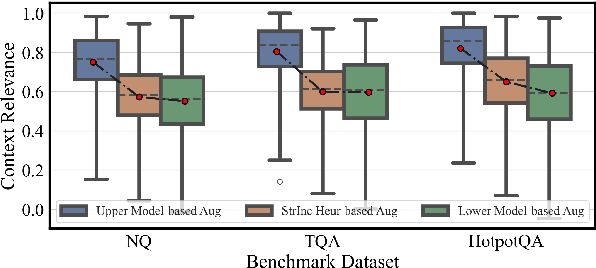
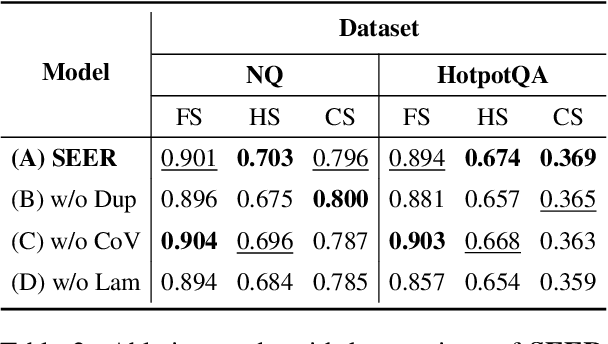
Recent studies in Retrieval-Augmented Generation (RAG) have investigated extracting evidence from retrieved passages to reduce computational costs and enhance the final RAG performance, yet it remains challenging. Existing methods heavily rely on heuristic-based augmentation, encountering several issues: (1) Poor generalization due to hand-crafted context filtering; (2) Semantics deficiency due to rule-based context chunking; (3) Skewed length due to sentence-wise filter learning. To address these issues, we propose a model-based evidence extraction learning framework, SEER, optimizing a vanilla model as an evidence extractor with desired properties through self-aligned learning. Extensive experiments show that our method largely improves the final RAG performance, enhances the faithfulness, helpfulness, and conciseness of the extracted evidence, and reduces the evidence length by 9.25 times. The code will be available at https://github.com/HITsz-TMG/SEER.
Medico: Towards Hallucination Detection and Correction with Multi-source Evidence Fusion
Oct 14, 2024



As we all know, hallucinations prevail in Large Language Models (LLMs), where the generated content is coherent but factually incorrect, which inflicts a heavy blow on the widespread application of LLMs. Previous studies have shown that LLMs could confidently state non-existent facts rather than answering ``I don't know''. Therefore, it is necessary to resort to external knowledge to detect and correct the hallucinated content. Since manual detection and correction of factual errors is labor-intensive, developing an automatic end-to-end hallucination-checking approach is indeed a needful thing. To this end, we present Medico, a Multi-source evidence fusion enhanced hallucination detection and correction framework. It fuses diverse evidence from multiple sources, detects whether the generated content contains factual errors, provides the rationale behind the judgment, and iteratively revises the hallucinated content. Experimental results on evidence retrieval (0.964 HR@5, 0.908 MRR@5), hallucination detection (0.927-0.951 F1), and hallucination correction (0.973-0.979 approval rate) manifest the great potential of Medico. A video demo of Medico can be found at https://youtu.be/RtsO6CSesBI.
SheetAgent: A Generalist Agent for Spreadsheet Reasoning and Manipulation via Large Language Models
Mar 06, 2024Spreadsheet manipulation is widely existing in most daily works and significantly improves working efficiency. Large language model (LLM) has been recently attempted for automatic spreadsheet manipulation but has not yet been investigated in complicated and realistic tasks where reasoning challenges exist (e.g., long horizon manipulation with multi-step reasoning and ambiguous requirements). To bridge the gap with the real-world requirements, we introduce $\textbf{SheetRM}$, a benchmark featuring long-horizon and multi-category tasks with reasoning-dependent manipulation caused by real-life challenges. To mitigate the above challenges, we further propose $\textbf{SheetAgent}$, a novel autonomous agent that utilizes the power of LLMs. SheetAgent consists of three collaborative modules: $\textit{Planner}$, $\textit{Informer}$, and $\textit{Retriever}$, achieving both advanced reasoning and accurate manipulation over spreadsheets without human interaction through iterative task reasoning and reflection. Extensive experiments demonstrate that SheetAgent delivers 20-30% pass rate improvements on multiple benchmarks over baselines, achieving enhanced precision in spreadsheet manipulation and demonstrating superior table reasoning abilities. More details and visualizations are available at https://sheetagent.github.io.
Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models
Feb 22, 2024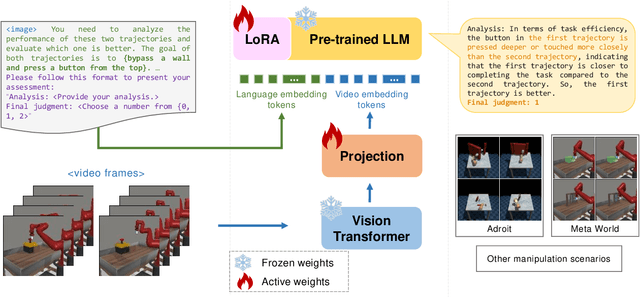
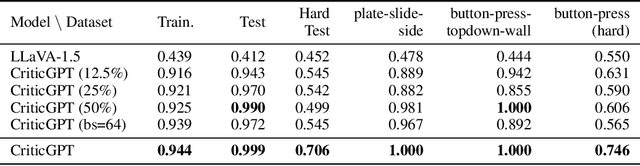
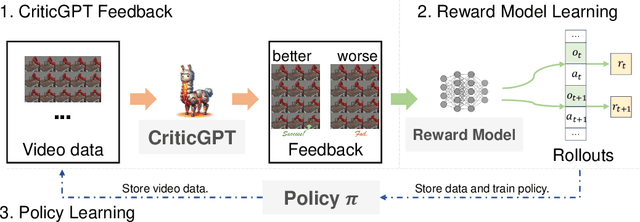
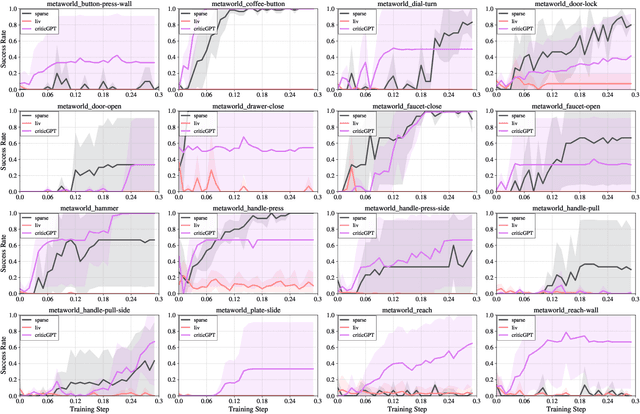
Recently, there has been considerable attention towards leveraging large language models (LLMs) to enhance decision-making processes. However, aligning the natural language text instructions generated by LLMs with the vectorized operations required for execution presents a significant challenge, often necessitating task-specific details. To circumvent the need for such task-specific granularity, inspired by preference-based policy learning approaches, we investigate the utilization of multimodal LLMs to provide automated preference feedback solely from image inputs to guide decision-making. In this study, we train a multimodal LLM, termed CriticGPT, capable of understanding trajectory videos in robot manipulation tasks, serving as a critic to offer analysis and preference feedback. Subsequently, we validate the effectiveness of preference labels generated by CriticGPT from a reward modeling perspective. Experimental evaluation of the algorithm's preference accuracy demonstrates its effective generalization ability to new tasks. Furthermore, performance on Meta-World tasks reveals that CriticGPT's reward model efficiently guides policy learning, surpassing rewards based on state-of-the-art pre-trained representation models.