 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025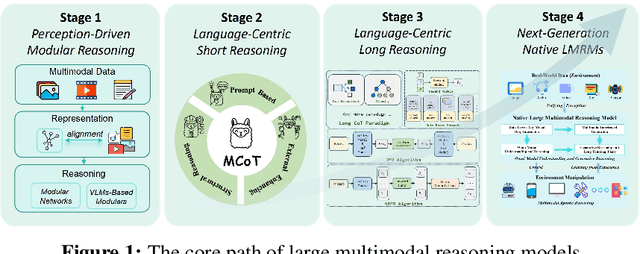
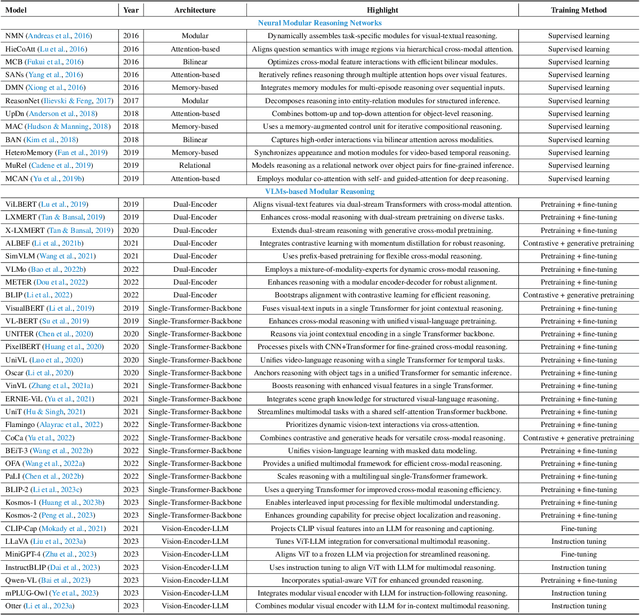
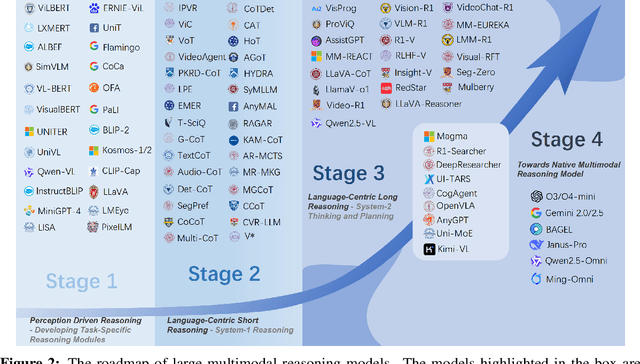
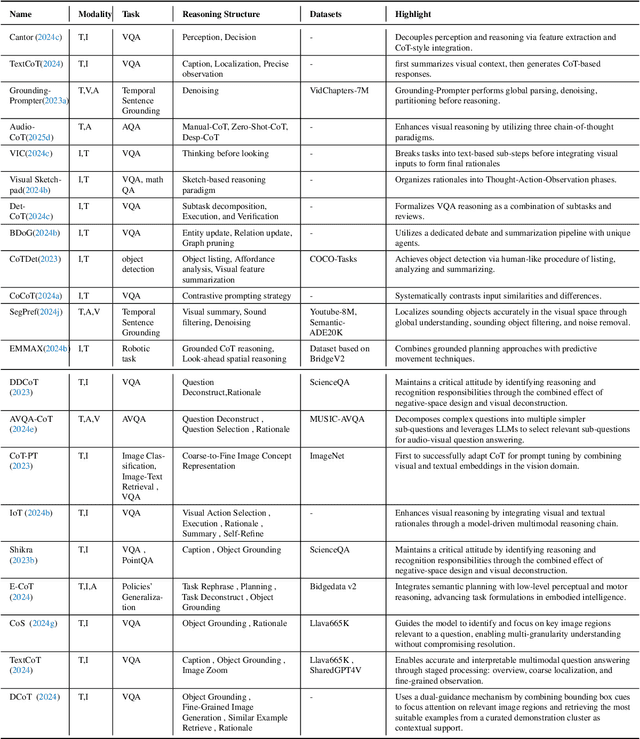
Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
A Unified Agentic Framework for Evaluating Conditional Image Generation
Apr 09, 2025Conditional image generation has gained significant attention for its ability to personalize content. However, the field faces challenges in developing task-agnostic, reliable, and explainable evaluation metrics. This paper introduces CIGEval, a unified agentic framework for comprehensive evaluation of conditional image generation tasks. CIGEval utilizes large multimodal models (LMMs) as its core, integrating a multi-functional toolbox and establishing a fine-grained evaluation framework. Additionally, we synthesize evaluation trajectories for fine-tuning, empowering smaller LMMs to autonomously select appropriate tools and conduct nuanced analyses based on tool outputs. Experiments across seven prominent conditional image generation tasks demonstrate that CIGEval (GPT-4o version) achieves a high correlation of 0.4625 with human assessments, closely matching the inter-annotator correlation of 0.47. Moreover, when implemented with 7B open-source LMMs using only 2.3K training trajectories, CIGEval surpasses the previous GPT-4o-based state-of-the-art method. Case studies on GPT-4o image generation highlight CIGEval's capability in identifying subtle issues related to subject consistency and adherence to control guidance, indicating its great potential for automating evaluation of image generation tasks with human-level reliability.
Medico: Towards Hallucination Detection and Correction with Multi-source Evidence Fusion
Oct 14, 2024



As we all know, hallucinations prevail in Large Language Models (LLMs), where the generated content is coherent but factually incorrect, which inflicts a heavy blow on the widespread application of LLMs. Previous studies have shown that LLMs could confidently state non-existent facts rather than answering ``I don't know''. Therefore, it is necessary to resort to external knowledge to detect and correct the hallucinated content. Since manual detection and correction of factual errors is labor-intensive, developing an automatic end-to-end hallucination-checking approach is indeed a needful thing. To this end, we present Medico, a Multi-source evidence fusion enhanced hallucination detection and correction framework. It fuses diverse evidence from multiple sources, detects whether the generated content contains factual errors, provides the rationale behind the judgment, and iteratively revises the hallucinated content. Experimental results on evidence retrieval (0.964 HR@5, 0.908 MRR@5), hallucination detection (0.927-0.951 F1), and hallucination correction (0.973-0.979 approval rate) manifest the great potential of Medico. A video demo of Medico can be found at https://youtu.be/RtsO6CSesBI.