 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Recurrent Layers with Dual-Path Strategy in a Variant of Convolutional Network for Speaker-Independent Speech Separation
Paper and Code
Mar 25, 2022
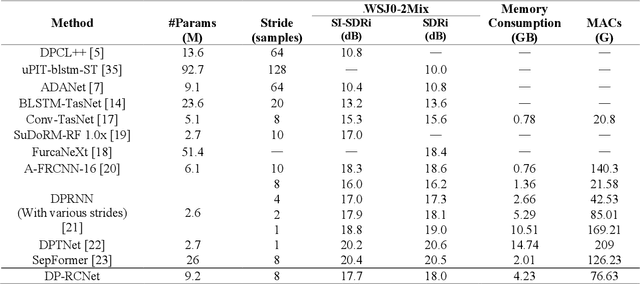
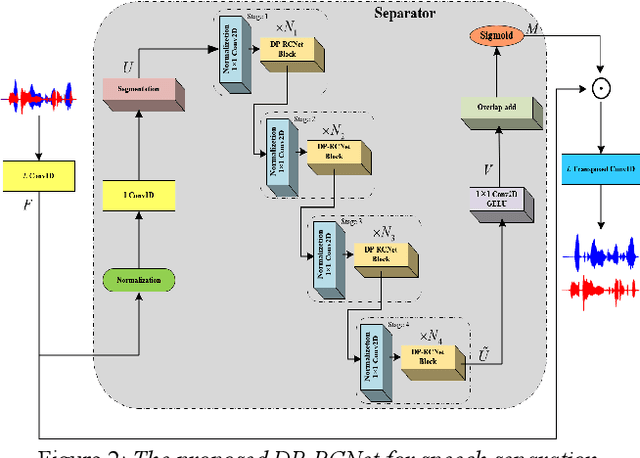
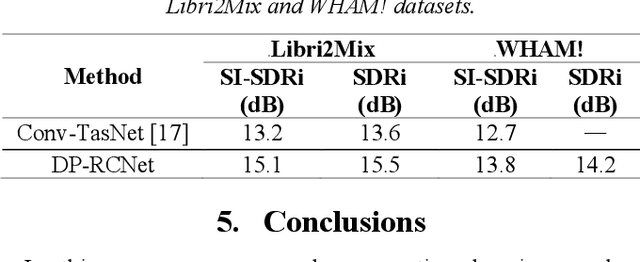
Speaker-independent speech separation has achieved remarkable performance in recent years with the development of deep neural network (DNN). Various network architectures, from traditional convolutional neural network (CNN) and recurrent neural network (RNN) to advanced transformer, have been designed sophistically to improve separation performance. However, the state-of-the-art models usually suffer from several flaws related to the computation, such as large model size, huge memory consumption and computational complexity. To find the balance between the performance and computational efficiency and to further explore the modeling ability of traditional network structure, we combine RNN and a newly proposed variant of convolutional network to cope with speech separation problem. By embedding two RNNs into basic block of this variant with the help of dual-path strategy, the proposed network can effectively learn the local information and global dependency. Besides, a four-staged structure enables the separation procedure to be performed gradually at finer and finer scales as the feature dimension increases. The experimental results on various datasets have proven the effectiveness of the proposed method and shown that a trade-off between the separation performance and computational efficiency is well achieved.