 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLSTransform: Energy-Efficient Llama 2 Inference on FPGAs Via High Level Synthesis
Apr 29, 2024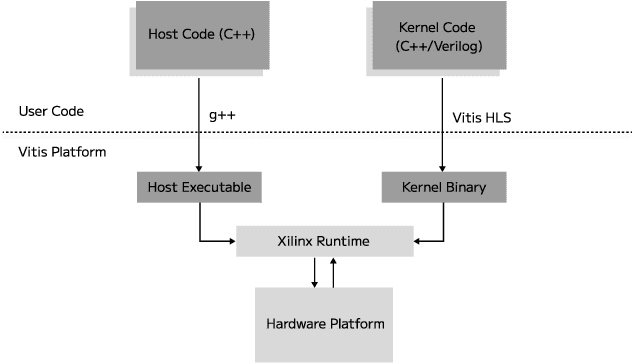

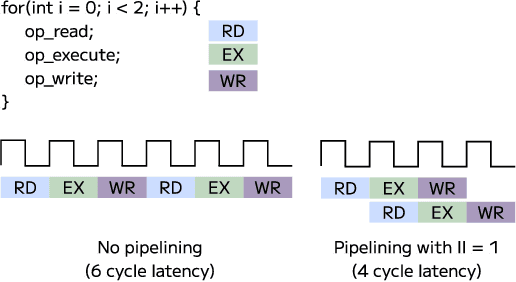

Graphics Processing Units (GPUs) have become the leading hardware accelerator for deep learning applications and are used widely in training and inference of transformers; transformers have achieved state-of-the-art performance in many areas of machine learning and are especially used in most modern Large Language Models (LLMs). However, GPUs require large amounts of energy, which poses environmental concerns, demands high operational costs, and causes GPUs to be unsuitable for edge computing. We develop an accelerator for transformers, namely, Llama 2, an open-source state-of-the-art LLM, using high level synthesis (HLS) on Field Programmable Gate Arrays (FPGAs). HLS allows us to rapidly prototype FPGA designs without writing code at the register-transfer level (RTL). We name our method HLSTransform, and the FPGA designs we synthesize with HLS achieve up to a 12.75x reduction and 8.25x reduction in energy used per token on the Xilinx Virtex UltraScale+ VU9P FPGA compared to an Intel Xeon Broadwell E5-2686 v4 CPU and NVIDIA RTX 3090 GPU respectively, while increasing inference speeds by up to 2.46x compared to CPU and maintaining 0.53x the speed of an RTX 3090 GPU despite the GPU's 4 times higher base clock rate. With the lack of existing open-source FPGA accelerators for transformers, we open-source our code and document our steps for synthesis. We hope this work will serve as a step in democratizing the use of FPGAs in transformer inference and inspire research into energy-efficient inference methods as a whole. The code can be found on https://github.com/HLSTransform/submission.
WorldCoder, a Model-Based LLM Agent: Building World Models by Writing Code and Interacting with the Environment
Feb 19, 2024We give a model-based agent that builds a Python program representing its knowledge of the world based on its interactions with the environment. The world model tries to explain its interactions, while also being optimistic about what reward it can achieve. We do this by extending work on program synthesis via LLMs. We study our agent on gridworlds, finding our approach is more sample-efficient compared to deep RL, and more compute-efficient compared to ReAct-style agents.
I Speak, You Verify: Toward Trustworthy Neural Program Synthesis
Sep 29, 2022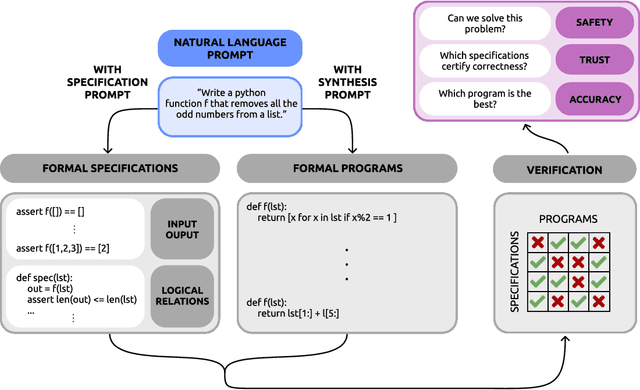
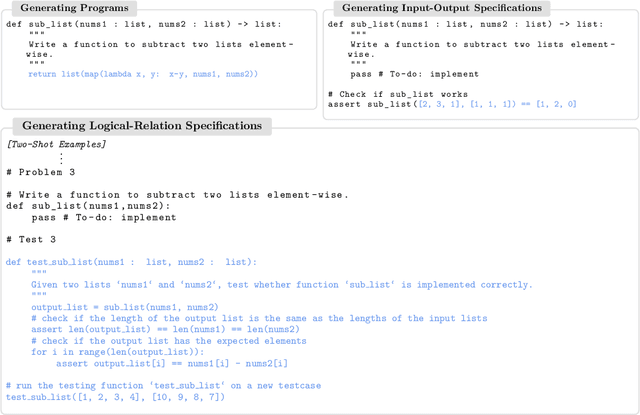
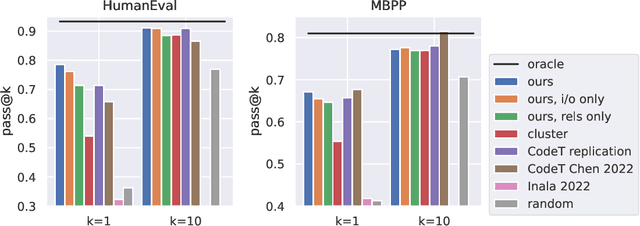
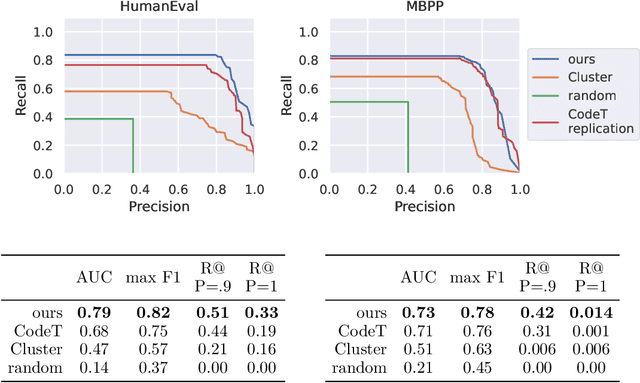
We develop an approach for improving the trustworthiness and overall accuracy of program synthesizers based on large language models for source code. Given a natural language description of a programming problem, our method samples both candidate programs as well as candidate predicates specifying how the program should behave. We learn to analyze the agreement between programs and predicates to judge both which program is most likely to be correct, and also judge whether the language model is able to solve the programming problem in the first place. This latter capacity allows favoring high precision over broad recall: fostering trust by only proposing a program when the system is certain that it is correct.