Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Speak, You Verify: Toward Trustworthy Neural Program Synthesis
Paper and Code
Sep 29, 2022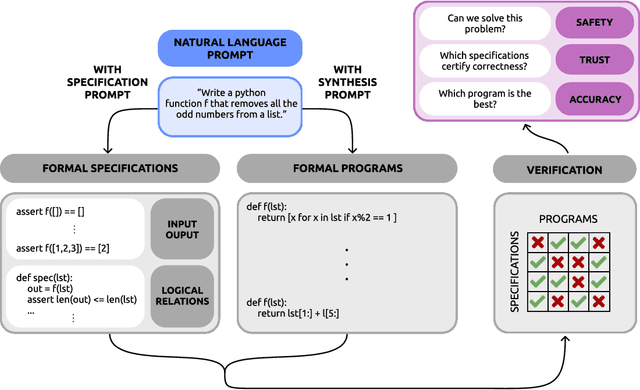
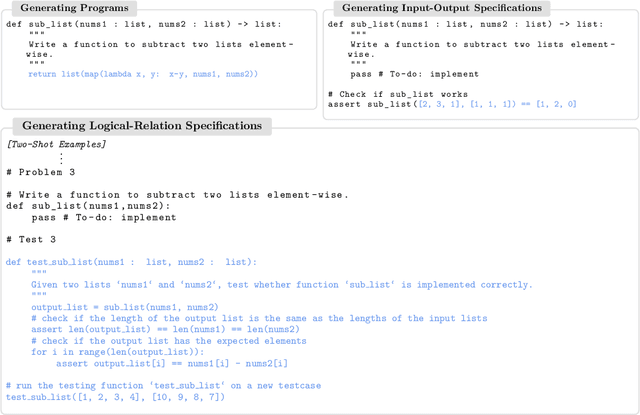
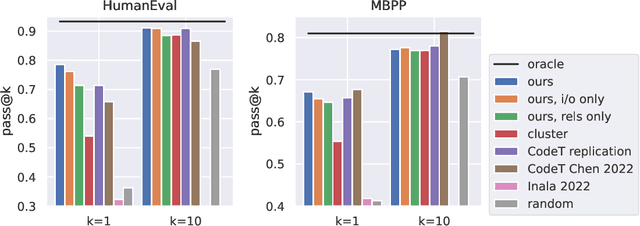
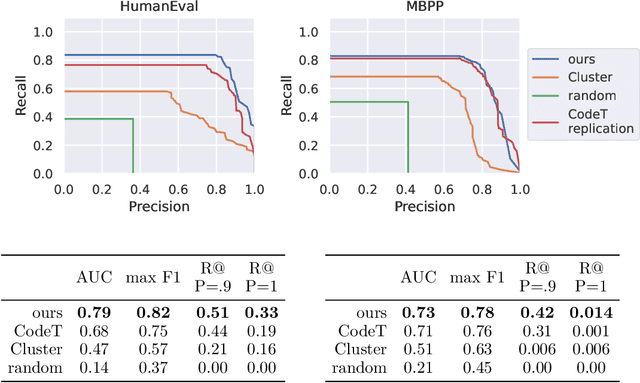
We develop an approach for improving the trustworthiness and overall accuracy of program synthesizers based on large language models for source code. Given a natural language description of a programming problem, our method samples both candidate programs as well as candidate predicates specifying how the program should behave. We learn to analyze the agreement between programs and predicates to judge both which program is most likely to be correct, and also judge whether the language model is able to solve the programming problem in the first place. This latter capacity allows favoring high precision over broad recall: fostering trust by only proposing a program when the system is certain that it is correct.
* 10 pages, 6 figures
View paper on
 OpenReview
OpenReview