 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUNSET -- A Sensor-fUsioN based semantic SegmEnTation exemplar for ROS-based self-adaptation
Jan 20, 2026The fact that robots are getting deployed more often in dynamic environments, together with the increasing complexity of their software systems, raises the need for self-adaptive approaches. In these environments robotic software systems increasingly operate amid (1) uncertainties, where symptoms are easy to observe but root causes are ambiguous, or (2) multiple uncertainties appear concurrently. We present SUNSET, a ROS2-based exemplar that enables rigorous, repeatable evaluation of architecture-based self-adaptation in such conditions. It implements a sensor fusion semantic-segmentation pipeline driven by a trained Machine Learning (ML) model whose input preprocessing can be perturbed to induce realistic performance degradations. The exemplar exposes five observable symptoms, where each can be caused by different root causes and supports concurrent uncertainties spanning self-healing and self-optimisation. SUNSET includes the segmentation pipeline, a trained ML model, uncertainty-injection scripts, a baseline controller, and step-by-step integration and evaluation documentation to facilitate reproducible studies and fair comparison.
Relevant Irrelevance: Generating Alterfactual Explanations for Image Classifiers
May 08, 2024
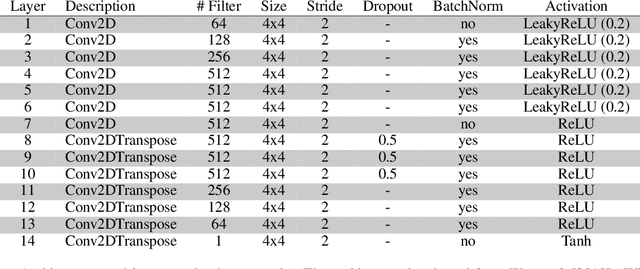

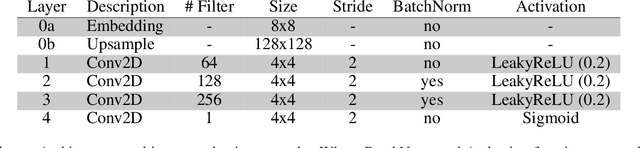
In this paper, we demonstrate the feasibility of alterfactual explanations for black box image classifiers. Traditional explanation mechanisms from the field of Counterfactual Thinking are a widely-used paradigm for Explainable Artificial Intelligence (XAI), as they follow a natural way of reasoning that humans are familiar with. However, most common approaches from this field are based on communicating information about features or characteristics that are especially important for an AI's decision. However, to fully understand a decision, not only knowledge about relevant features is needed, but the awareness of irrelevant information also highly contributes to the creation of a user's mental model of an AI system. To this end, a novel approach for explaining AI systems called alterfactual explanations was recently proposed on a conceptual level. It is based on showing an alternative reality where irrelevant features of an AI's input are altered. By doing so, the user directly sees which input data characteristics can change arbitrarily without influencing the AI's decision. In this paper, we show for the first time that it is possible to apply this idea to black box models based on neural networks. To this end, we present a GAN-based approach to generate these alterfactual explanations for binary image classifiers. Further, we present a user study that gives interesting insights on how alterfactual explanations can complement counterfactual explanations.
GANterfactual-RL: Understanding Reinforcement Learning Agents' Strategies through Visual Counterfactual Explanations
Feb 24, 2023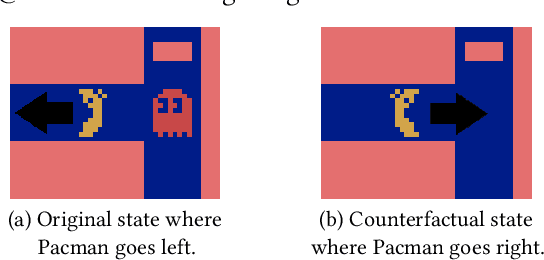

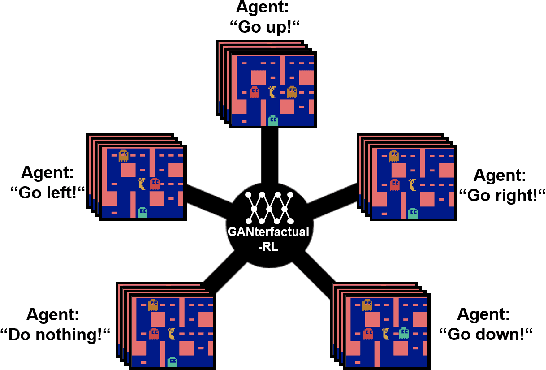

Counterfactual explanations are a common tool to explain artificial intelligence models. For Reinforcement Learning (RL) agents, they answer "Why not?" or "What if?" questions by illustrating what minimal change to a state is needed such that an agent chooses a different action. Generating counterfactual explanations for RL agents with visual input is especially challenging because of their large state spaces and because their decisions are part of an overarching policy, which includes long-term decision-making. However, research focusing on counterfactual explanations, specifically for RL agents with visual input, is scarce and does not go beyond identifying defective agents. It is unclear whether counterfactual explanations are still helpful for more complex tasks like analyzing the learned strategies of different agents or choosing a fitting agent for a specific task. We propose a novel but simple method to generate counterfactual explanations for RL agents by formulating the problem as a domain transfer problem which allows the use of adversarial learning techniques like StarGAN. Our method is fully model-agnostic and we demonstrate that it outperforms the only previous method in several computational metrics. Furthermore, we show in a user study that our method performs best when analyzing which strategies different agents pursue.
Alterfactual Explanations -- The Relevance of Irrelevance for Explaining AI Systems
Jul 19, 2022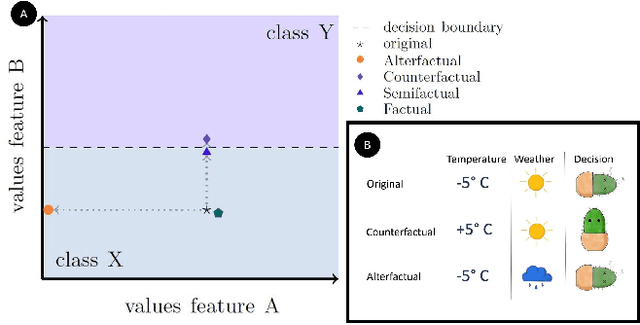
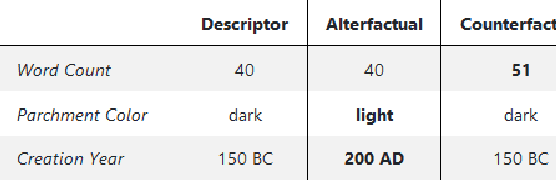
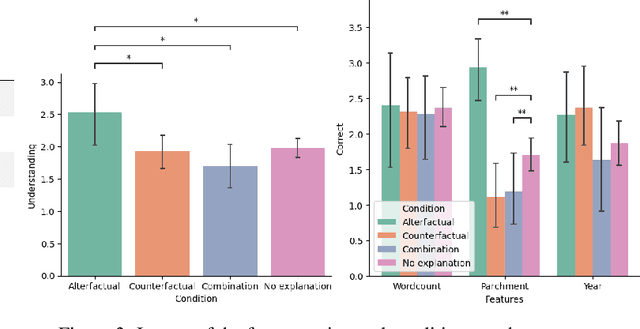
Explanation mechanisms from the field of Counterfactual Thinking are a widely-used paradigm for Explainable Artificial Intelligence (XAI), as they follow a natural way of reasoning that humans are familiar with. However, all common approaches from this field are based on communicating information about features or characteristics that are especially important for an AI's decision. We argue that in order to fully understand a decision, not only knowledge about relevant features is needed, but that the awareness of irrelevant information also highly contributes to the creation of a user's mental model of an AI system. Therefore, we introduce a new way of explaining AI systems. Our approach, which we call Alterfactual Explanations, is based on showing an alternative reality where irrelevant features of an AI's input are altered. By doing so, the user directly sees which characteristics of the input data can change arbitrarily without influencing the AI's decision. We evaluate our approach in an extensive user study, revealing that it is able to significantly contribute to the participants' understanding of an AI. We show that alterfactual explanations are suited to convey an understanding of different aspects of the AI's reasoning than established counterfactual explanation methods.
Dynamic Difficulty Adjustment in Virtual Reality Exergames through Experience-driven Procedural Content Generation
Aug 19, 2021



Virtual Reality (VR) games that feature physical activities have been shown to increase players' motivation to do physical exercise. However, for such exercises to have a positive healthcare effect, they have to be repeated several times a week. To maintain player motivation over longer periods of time, games often employ Dynamic Difficulty Adjustment (DDA) to adapt the game's challenge according to the player's capabilities. For exercise games, this is mostly done by tuning specific in-game parameters like the speed of objects. In this work, we propose to use experience-driven Procedural Content Generation for DDA in VR exercise games by procedurally generating levels that match the player's current capabilities. Not only finetuning specific parameters but creating completely new levels has the potential to decrease repetition over longer time periods and allows for the simultaneous adaptation of the cognitive and physical challenge of the exergame. As a proof-of-concept, we implement an initial prototype in which the player must traverse a maze that includes several exercise rooms, whereby the generation of the maze is realized by a neural network. Passing those exercise rooms requires the player to perform physical activities. To match the player's capabilities, we use Deep Reinforcement Learning to adjust the structure of the maze and to decide which exercise rooms to include in the maze. We evaluate our prototype in an exploratory user study utilizing both biodata and subjective questionnaires.
Do Deep Neural Networks Forget Facial Action Units? -- Exploring the Effects of Transfer Learning in Health Related Facial Expression Recognition
Apr 15, 2021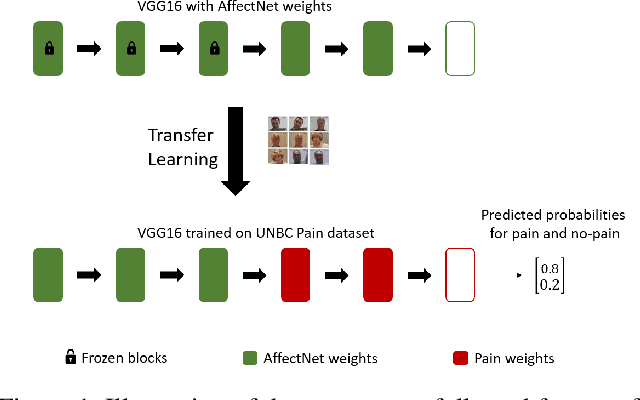

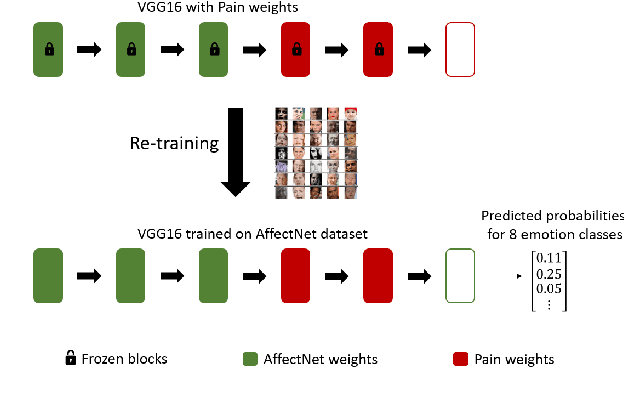

In this paper, we present a process to investigate the effects of transfer learning for automatic facial expression recognition from emotions to pain. To this end, we first train a VGG16 convolutional neural network to automatically discern between eight categorical emotions. We then fine-tune successively larger parts of this network to learn suitable representations for the task of automatic pain recognition. Subsequently, we apply those fine-tuned representations again to the original task of emotion recognition to further investigate the differences in performance between the models. In the second step, we use Layer-wise Relevance Propagation to analyze predictions of the model that have been predicted correctly previously but are now wrongly classified. Based on this analysis, we rely on the visual inspection of a human observer to generate hypotheses about what has been forgotten by the model. Finally, we test those hypotheses quantitatively utilizing concept embedding analysis methods. Our results show that the network, which was fully fine-tuned for pain recognition, indeed payed less attention to two action units that are relevant for expression recognition but not for pain recognition.
Benchmarking Perturbation-based Saliency Maps for Explaining Deep Reinforcement Learning Agents
Jan 18, 2021


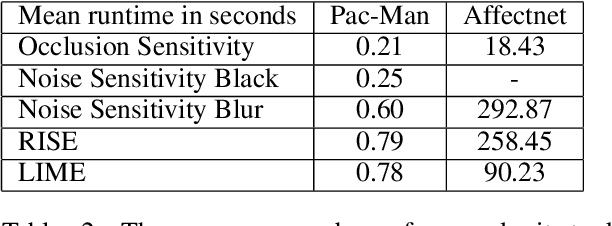
Recent years saw a plethora of work on explaining complex intelligent agents. One example is the development of several algorithms that generate saliency maps which show how much each pixel attributed to the agents' decision. However, most evaluations of such saliency maps focus on image classification tasks. As far as we know, there is no work which thoroughly compares different saliency maps for Deep Reinforcement Learning agents. This paper compares four perturbation-based approaches to create saliency maps for Deep Reinforcement Learning agents trained on four different Atari 2600 games. All four approaches work by perturbing parts of the input and measuring how much this affects the agent's output. The approaches are compared using three computational metrics: dependence on the learned parameters of the agent (sanity checks), faithfulness to the agent's reasoning (input degradation), and run-time.
This is not the Texture you are looking for! Introducing Novel Counterfactual Explanations for Non-Experts using Generative Adversarial Learning
Dec 22, 2020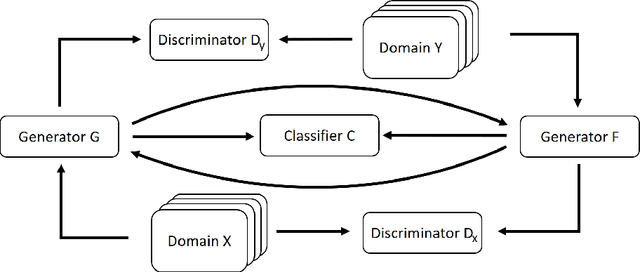
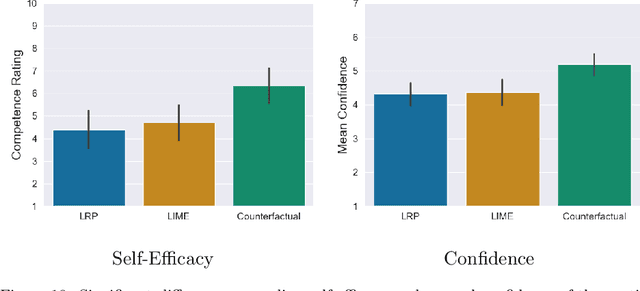
With the ongoing rise of machine learning, the need for methods for explaining decisions made by artificial intelligence systems is becoming a more and more important topic. Especially for image classification tasks, many state-of-the-art tools to explain such classifiers rely on visual highlighting of important areas of the input data. Contrary, counterfactual explanation systems try to enable a counterfactual reasoning by modifying the input image in a way such that the classifier would have made a different prediction. By doing so, the users of counterfactual explanation systems are equipped with a completely different kind of explanatory information. However, methods for generating realistic counterfactual explanations for image classifiers are still rare. In this work, we present a novel approach to generate such counterfactual image explanations based on adversarial image-to-image translation techniques. Additionally, we conduct a user study to evaluate our approach in a use case which was inspired by a healthcare scenario. Our results show that our approach leads to significantly better results regarding mental models, explanation satisfaction, trust, emotions, and self-efficacy than two state-of-the art systems that work with saliency maps, namely LIME and LRP.
Local and Global Explanations of Agent Behavior: Integrating Strategy Summaries with Saliency Maps
May 29, 2020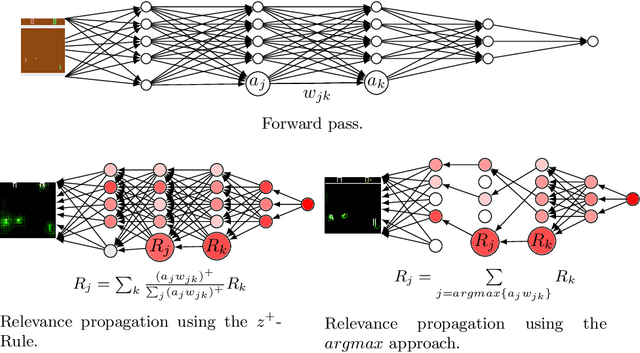

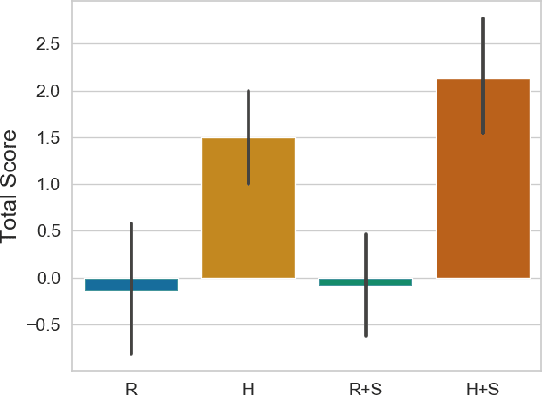
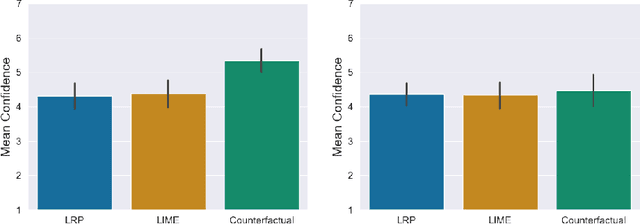
With advances in reinforcement learning (RL), agents are now being developed in high-stakes application domains such as healthcare and transportation. Explaining the behavior of these agents is challenging, as the environments in which they act have large state spaces, and their decision-making can be affected by delayed rewards, making it difficult to analyze their behavior. To address this problem, several approaches have been developed. Some approaches attempt to convey the $\textit{global}$ behavior of the agent, describing the actions it takes in different states. Other approaches devised $\textit{local}$ explanations which provide information regarding the agent's decision-making in a particular state. In this paper, we combine global and local explanation methods, and evaluate their joint and separate contributions, providing (to the best of our knowledge) the first user study of combined local and global explanations for RL agents. Specifically, we augment strategy summaries that extract important trajectories of states from simulations of the agent with saliency maps which show what information the agent attends to. Our results show that the choice of what states to include in the summary (global information) strongly affects people's understanding of agents: participants shown summaries that included important states significantly outperformed participants who were presented with agent behavior in a randomly set of chosen world-states. We find mixed results with respect to augmenting demonstrations with saliency maps (local information), as the addition of saliency maps did not significantly improve performance in most cases. However, we do find some evidence that saliency maps can help users better understand what information the agent relies on in its decision making, suggesting avenues for future work that can further improve explanations of RL agents.