 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Emotions -- A Data Driven Approach to Learn Transferable Feature Representations from Raw Speech Input for Emotion Recognition
Paper and Code
Sep 30, 2020
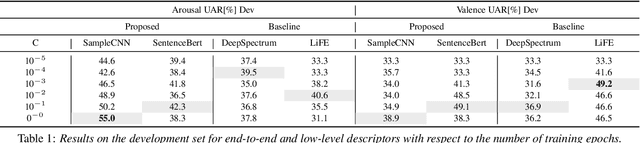


Traditional approaches to automatic emotion recognition are relying on the application of handcrafted features. More recently however the advent of deep learning enabled algorithms to learn meaningful representations of input data automatically. In this paper, we investigate the applicability of transferring knowledge learned from large text and audio corpora to the task of automatic emotion recognition. To evaluate the practicability of our approach, we are taking part in this year's Interspeech ComParE Elderly Emotion Sub-Challenge, where the goal is to classify spoken narratives of elderly people with respect to the emotion of the speaker. Our results show that the learned feature representations can be effectively applied for classifying emotions from spoken language. We found the performance of the features extracted from the audio signal to be not as consistent as those that have been extracted from the transcripts. While the acoustic features achieved best in class results on the development set, when compared to the baseline systems, their performance dropped considerably on the test set of the challenge. The features extracted from the text form, however, are showing promising results on both sets and are outperforming the official baseline by 5.7 percentage points unweighted average recall.