 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWords are all you need? Capturing human sensory similarity with textual descriptors
Paper and Code
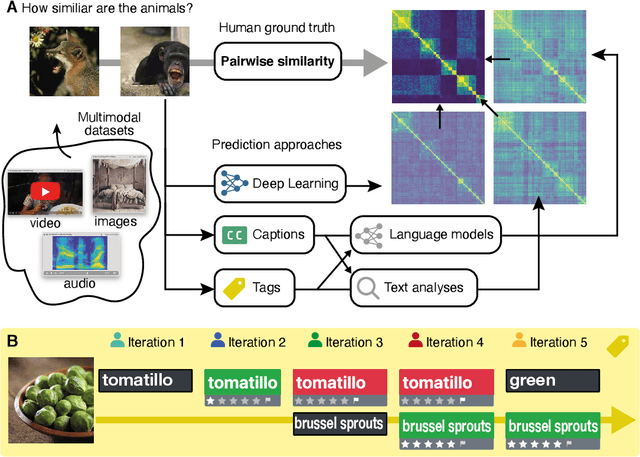
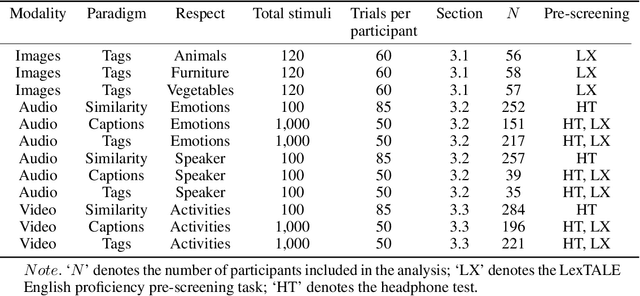

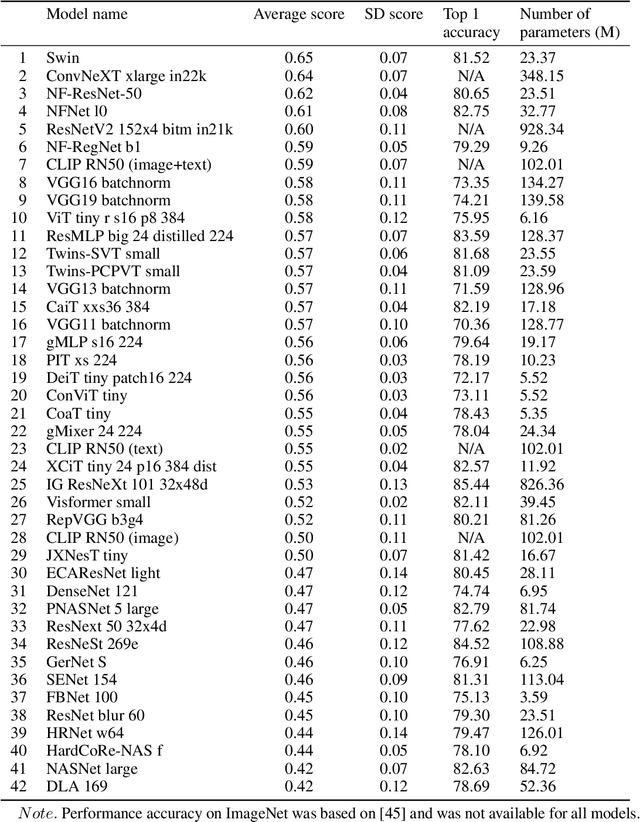
Recent advances in multimodal training use textual descriptions to significantly enhance machine understanding of images and videos. Yet, it remains unclear to what extent language can fully capture sensory experiences across different modalities. A well-established approach for characterizing sensory experiences relies on similarity judgments, namely, the degree to which people perceive two distinct stimuli as similar. We explore the relation between human similarity judgments and language in a series of large-scale behavioral studies ($N=1,823$ participants) across three modalities (images, audio, and video) and two types of text descriptors: simple word tags and free-text captions. In doing so, we introduce a novel adaptive pipeline for tag mining that is both efficient and domain-general. We show that our prediction pipeline based on text descriptors exhibits excellent performance, and we compare it against a comprehensive array of 611 baseline models based on vision-, audio-, and video-processing architectures. We further show that the degree to which textual descriptors and models predict human similarity varies across and within modalities. Taken together, these studies illustrate the value of integrating machine learning and cognitive science approaches to better understand the similarities and differences between human and machine representations. We present an interactive visualization at https://words-are-all-you-need.s3.amazonaws.com/index.html for exploring the similarity between stimuli as experienced by humans and different methods reported in the paper.