 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALVIN: Active Learning Via INterpolation
Oct 11, 2024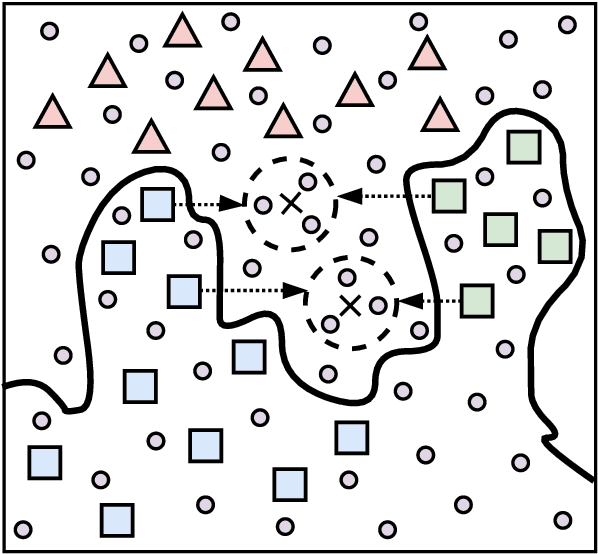
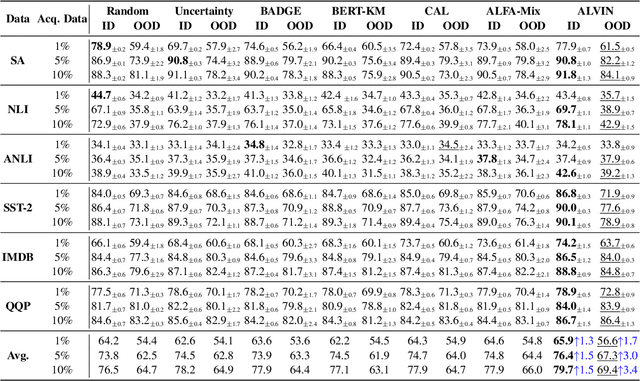
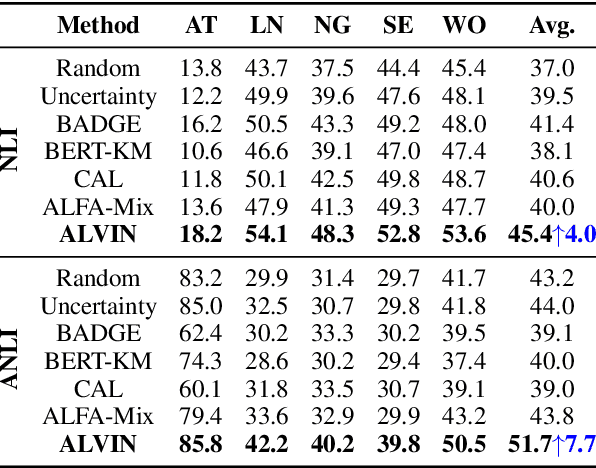
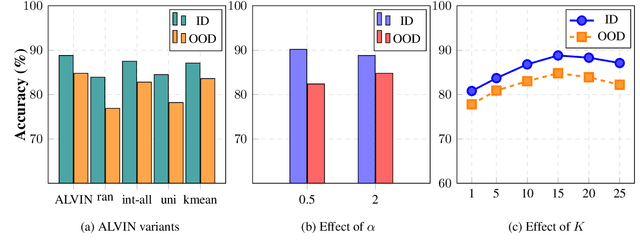
Active Learning aims to minimize annotation effort by selecting the most useful instances from a pool of unlabeled data. However, typical active learning methods overlook the presence of distinct example groups within a class, whose prevalence may vary, e.g., in occupation classification datasets certain demographics are disproportionately represented in specific classes. This oversight causes models to rely on shortcuts for predictions, i.e., spurious correlations between input attributes and labels occurring in well-represented groups. To address this issue, we propose Active Learning Via INterpolation (ALVIN), which conducts intra-class interpolations between examples from under-represented and well-represented groups to create anchors, i.e., artificial points situated between the example groups in the representation space. By selecting instances close to the anchors for annotation, ALVIN identifies informative examples exposing the model to regions of the representation space that counteract the influence of shortcuts. Crucially, since the model considers these examples to be of high certainty, they are likely to be ignored by typical active learning methods. Experimental results on six datasets encompassing sentiment analysis, natural language inference, and paraphrase detection demonstrate that ALVIN outperforms state-of-the-art active learning methods in both in-distribution and out-of-distribution generalization.
Representational Alignment Supports Effective Machine Teaching
Jun 06, 2024A good teacher should not only be knowledgeable; but should be able to communicate in a way that the student understands -- to share the student's representation of the world. In this work, we integrate insights from machine teaching and pragmatic communication with the burgeoning literature on representational alignment to characterize a utility curve defining a relationship between representational alignment and teacher capability for promoting student learning. To explore the characteristics of this utility curve, we design a supervised learning environment that disentangles representational alignment from teacher accuracy. We conduct extensive computational experiments with machines teaching machines, complemented by a series of experiments in which machines teach humans. Drawing on our findings that improved representational alignment with a student improves student learning outcomes (i.e., task accuracy), we design a classroom matching procedure that assigns students to teachers based on the utility curve. If we are to design effective machine teachers, it is not enough to build teachers that are accurate -- we want teachers that can align, representationally, to their students too.
Mitigating Catastrophic Forgetting in Scheduled Sampling with Elastic Weight Consolidation in Neural Machine Translation
Sep 13, 2021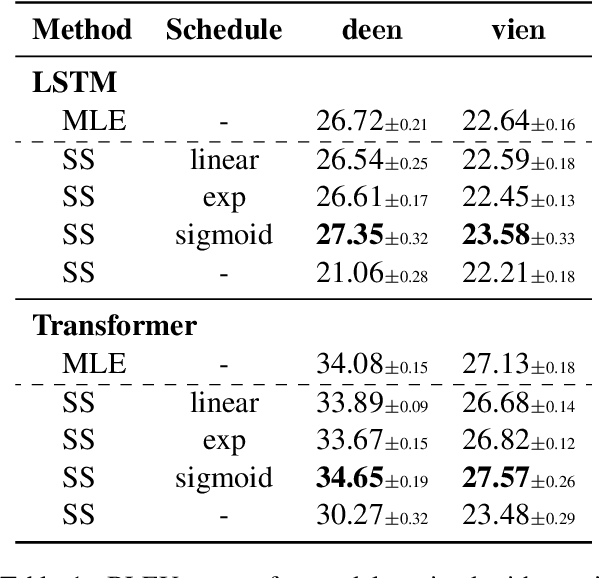
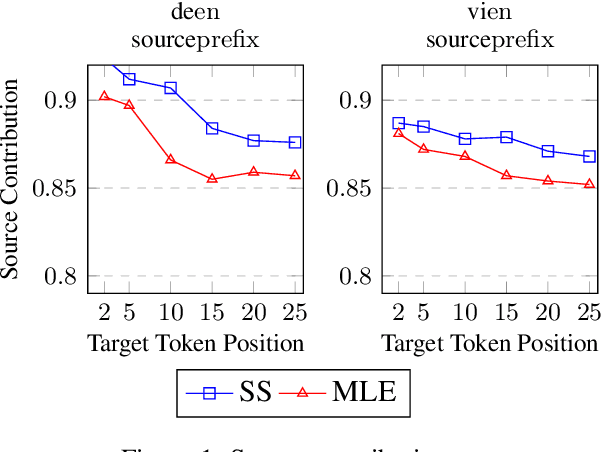
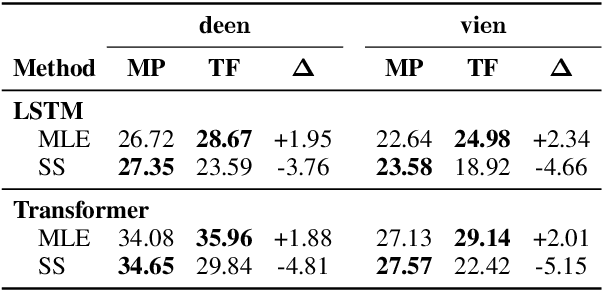
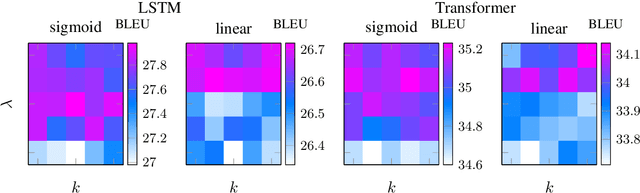
Despite strong performance in many sequence-to-sequence tasks, autoregressive models trained with maximum likelihood estimation suffer from exposure bias, i.e. a discrepancy between the ground-truth prefixes used during training and the model-generated prefixes used at inference time. Scheduled sampling is a simple and often empirically successful approach which addresses this issue by incorporating model-generated prefixes into the training process. However, it has been argued that it is an inconsistent training objective leading to models ignoring the prefixes altogether. In this paper, we conduct systematic experiments and find that it ameliorates exposure bias by increasing model reliance on the input sequence. We also observe that as a side-effect, it worsens performance when the model-generated prefix is correct, a form of catastrophic forgetting. We propose using Elastic Weight Consolidation as trade-off between mitigating exposure bias and retaining output quality. Experiments on two IWSLT'14 translation tasks demonstrate that our approach alleviates catastrophic forgetting and significantly improves BLEU compared to standard scheduled sampling.