 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Catastrophic Forgetting in Scheduled Sampling with Elastic Weight Consolidation in Neural Machine Translation
Paper and Code
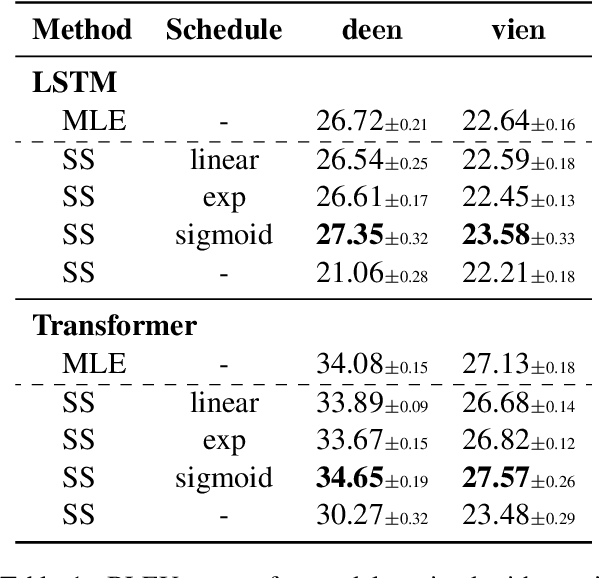
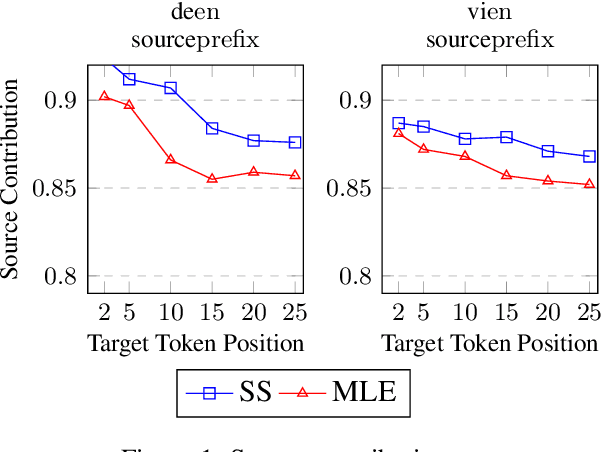
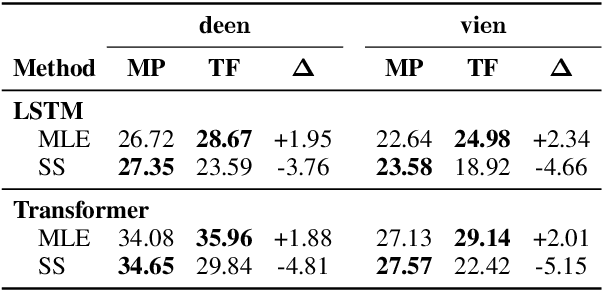
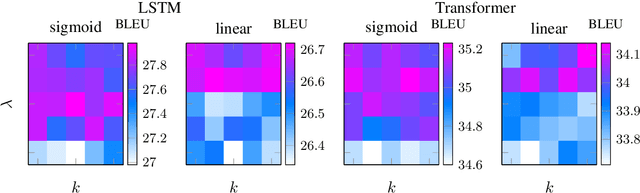
Despite strong performance in many sequence-to-sequence tasks, autoregressive models trained with maximum likelihood estimation suffer from exposure bias, i.e. a discrepancy between the ground-truth prefixes used during training and the model-generated prefixes used at inference time. Scheduled sampling is a simple and often empirically successful approach which addresses this issue by incorporating model-generated prefixes into the training process. However, it has been argued that it is an inconsistent training objective leading to models ignoring the prefixes altogether. In this paper, we conduct systematic experiments and find that it ameliorates exposure bias by increasing model reliance on the input sequence. We also observe that as a side-effect, it worsens performance when the model-generated prefix is correct, a form of catastrophic forgetting. We propose using Elastic Weight Consolidation as trade-off between mitigating exposure bias and retaining output quality. Experiments on two IWSLT'14 translation tasks demonstrate that our approach alleviates catastrophic forgetting and significantly improves BLEU compared to standard scheduled sampling.