 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Knowledge Distillation of LLMs With Counterfactual Explanations
Oct 24, 2025Knowledge distillation is a promising approach to transfer capabilities from complex teacher models to smaller, resource-efficient student models that can be deployed easily, particularly in task-aware scenarios. However, existing methods of task-aware distillation typically require substantial quantities of data which may be unavailable or expensive to obtain in many practical scenarios. In this paper, we address this challenge by introducing a novel strategy called Counterfactual-explanation-infused Distillation CoD for few-shot task-aware knowledge distillation by systematically infusing counterfactual explanations. Counterfactual explanations (CFEs) refer to inputs that can flip the output prediction of the teacher model with minimum perturbation. Our strategy CoD leverages these CFEs to precisely map the teacher's decision boundary with significantly fewer samples. We provide theoretical guarantees for motivating the role of CFEs in distillation, from both statistical and geometric perspectives. We mathematically show that CFEs can improve parameter estimation by providing more informative examples near the teacher's decision boundary. We also derive geometric insights on how CFEs effectively act as knowledge probes, helping the students mimic the teacher's decision boundaries more effectively than standard data. We perform experiments across various datasets and LLMs to show that CoD outperforms standard distillation approaches in few-shot regimes (as low as 8-512 samples). Notably, CoD only uses half of the original samples used by the baselines, paired with their corresponding CFEs and still improves performance.
Improving Consistency in Retrieval-Augmented Systems with Group Similarity Rewards
Oct 05, 2025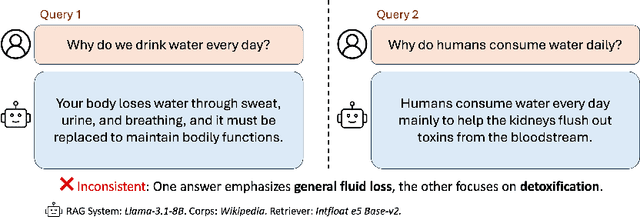
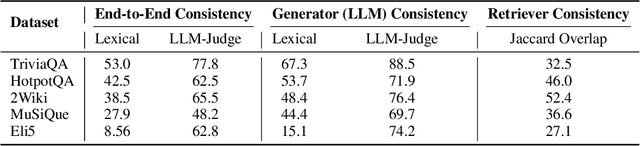
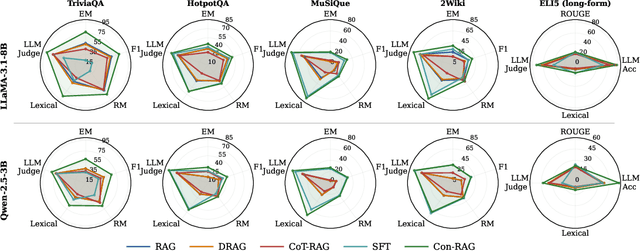
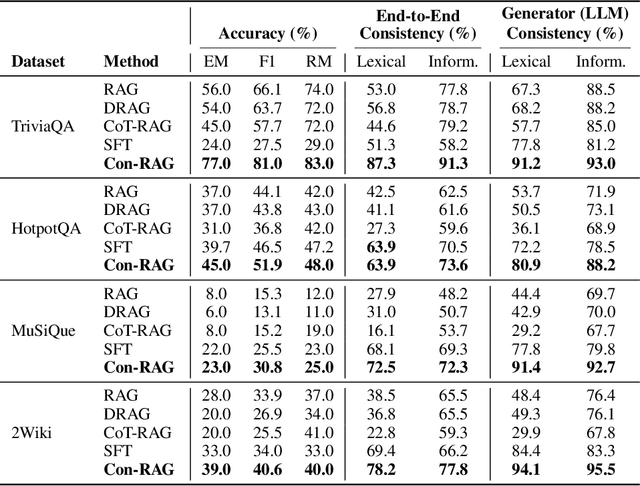
RAG systems are increasingly deployed in high-stakes domains where users expect outputs to be consistent across semantically equivalent queries. However, existing systems often exhibit significant inconsistencies due to variability in both the retriever and generator (LLM), undermining trust and reliability. In this work, we focus on information consistency, i.e., the requirement that outputs convey the same core content across semantically equivalent inputs. We introduce a principled evaluation framework that decomposes RAG consistency into retriever-level, generator-level, and end-to-end components, helping identify inconsistency sources. To improve consistency, we propose Paraphrased Set Group Relative Policy Optimization (PS-GRPO), an RL approach that leverages multiple rollouts across paraphrased set to assign group similarity rewards. We leverage PS-GRPO to achieve Information Consistent RAG (Con-RAG), training the generator to produce consistent outputs across paraphrased queries and remain robust to retrieval-induced variability. Because exact reward computation over paraphrase sets is computationally expensive, we also introduce a scalable approximation method that retains effectiveness while enabling efficient, large-scale training. Empirical evaluations across short-form, multi-hop, and long-form QA benchmarks demonstrate that Con-RAG significantly improves both consistency and accuracy over strong baselines, even in the absence of explicit ground-truth supervision. Our work provides practical solutions for evaluating and building reliable RAG systems for safety-critical deployments.
Counterfactual Explanations for Model Ensembles Using Entropic Risk Measures
Mar 11, 2025



Counterfactual explanations indicate the smallest change in input that can translate to a different outcome for a machine learning model. Counterfactuals have generated immense interest in high-stakes applications such as finance, education, hiring, etc. In several use-cases, the decision-making process often relies on an ensemble of models rather than just one. Despite significant research on counterfactuals for one model, the problem of generating a single counterfactual explanation for an ensemble of models has received limited interest. Each individual model might lead to a different counterfactual, whereas trying to find a counterfactual accepted by all models might significantly increase cost (effort). We propose a novel strategy to find the counterfactual for an ensemble of models using the perspective of entropic risk measure. Entropic risk is a convex risk measure that satisfies several desirable properties. We incorporate our proposed risk measure into a novel constrained optimization to generate counterfactuals for ensembles that stay valid for several models. The main significance of our measure is that it provides a knob that allows for the generation of counterfactuals that stay valid under an adjustable fraction of the models. We also show that a limiting case of our entropic-risk-based strategy yields a counterfactual valid for all models in the ensemble (worst-case min-max approach). We study the trade-off between the cost (effort) for the counterfactual and its validity for an ensemble by varying degrees of risk aversion, as determined by our risk parameter knob. We validate our performance on real-world datasets.
Quantifying Knowledge Distillation Using Partial Information Decomposition
Nov 12, 2024



Knowledge distillation provides an effective method for deploying complex machine learning models in resource-constrained environments. It typically involves training a smaller student model to emulate either the probabilistic outputs or the internal feature representations of a larger teacher model. By doing so, the student model often achieves substantially better performance on a downstream task compared to when it is trained independently. Nevertheless, the teacher's internal representations can also encode noise or additional information that may not be relevant to the downstream task. This observation motivates our primary question: What are the information-theoretic limits of knowledge transfer? To this end, we leverage a body of work in information theory called Partial Information Decomposition (PID) to quantify the distillable and distilled knowledge of a teacher's representation corresponding to a given student and a downstream task. Moreover, we demonstrate that this metric can be practically used in distillation to address challenges caused by the complexity gap between the teacher and the student representations.
Quantifying Prediction Consistency Under Model Multiplicity in Tabular LLMs
Jul 04, 2024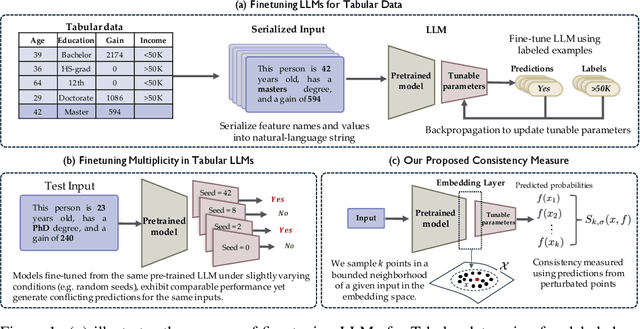
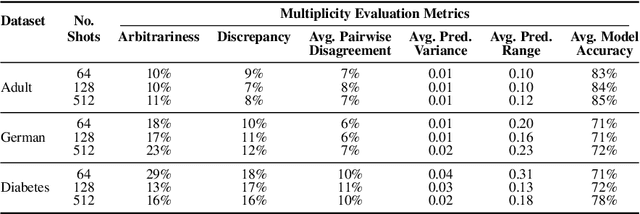
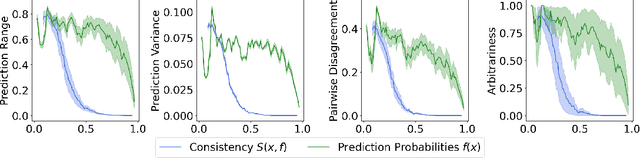
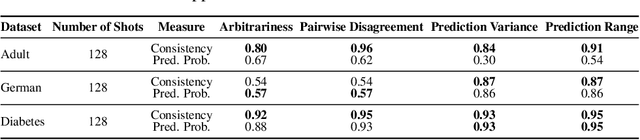
Fine-tuning large language models (LLMs) on limited tabular data for classification tasks can lead to \textit{fine-tuning multiplicity}, where equally well-performing models make conflicting predictions on the same inputs due to variations in the training process (i.e., seed, random weight initialization, retraining on additional or deleted samples). This raises critical concerns about the robustness and reliability of Tabular LLMs, particularly when deployed for high-stakes decision-making, such as finance, hiring, education, healthcare, etc. This work formalizes the challenge of fine-tuning multiplicity in Tabular LLMs and proposes a novel metric to quantify the robustness of individual predictions without expensive model retraining. Our metric quantifies a prediction's stability by analyzing (sampling) the model's local behavior around the input in the embedding space. Interestingly, we show that sampling in the local neighborhood can be leveraged to provide probabilistic robustness guarantees against a broad class of fine-tuned models. By leveraging Bernstein's Inequality, we show that predictions with sufficiently high robustness (as defined by our measure) will remain consistent with high probability. We also provide empirical evaluation on real-world datasets to support our theoretical results. Our work highlights the importance of addressing fine-tuning instabilities to enable trustworthy deployment of LLMs in high-stakes and safety-critical applications.
Quantifying Spuriousness of Biased Datasets Using Partial Information Decomposition
Jun 29, 2024



Spurious patterns refer to a mathematical association between two or more variables in a dataset that are not causally related. However, this notion of spuriousness, which is usually introduced due to sampling biases in the dataset, has classically lacked a formal definition. To address this gap, this work presents the first information-theoretic formalization of spuriousness in a dataset (given a split of spurious and core features) using a mathematical framework called Partial Information Decomposition (PID). Specifically, we disentangle the joint information content that the spurious and core features share about another target variable (e.g., the prediction label) into distinct components, namely unique, redundant, and synergistic information. We propose the use of unique information, with roots in Blackwell Sufficiency, as a novel metric to formally quantify dataset spuriousness and derive its desirable properties. We empirically demonstrate how higher unique information in the spurious features in a dataset could lead a model into choosing the spurious features over the core features for inference, often having low worst-group-accuracy. We also propose a novel autoencoder-based estimator for computing unique information that is able to handle high-dimensional image data. Finally, we also show how this unique information in the spurious feature is reduced across several dataset-based spurious-pattern-mitigation techniques such as data reweighting and varying levels of background mixing, demonstrating a novel tradeoff between unique information (spuriousness) and worst-group-accuracy.
A Unified View of Group Fairness Tradeoffs Using Partial Information Decomposition
Jun 07, 2024This paper introduces a novel information-theoretic perspective on the relationship between prominent group fairness notions in machine learning, namely statistical parity, equalized odds, and predictive parity. It is well known that simultaneous satisfiability of these three fairness notions is usually impossible, motivating practitioners to resort to approximate fairness solutions rather than stringent satisfiability of these definitions. However, a comprehensive analysis of their interrelations, particularly when they are not exactly satisfied, remains largely unexplored. Our main contribution lies in elucidating an exact relationship between these three measures of (un)fairness by leveraging a body of work in information theory called partial information decomposition (PID). In this work, we leverage PID to identify the granular regions where these three measures of (un)fairness overlap and where they disagree with each other leading to potential tradeoffs. We also include numerical simulations to complement our results.
Demystifying Local and Global Fairness Trade-offs in Federated Learning Using Partial Information Decomposition
Jul 21, 2023In this paper, we present an information-theoretic perspective to group fairness trade-offs in federated learning (FL) with respect to sensitive attributes, such as gender, race, etc. Existing works mostly focus on either \emph{global fairness} (overall disparity of the model across all clients) or \emph{local fairness} (disparity of the model at each individual client), without always considering their trade-offs. There is a lack of understanding of the interplay between global and local fairness in FL, and if and when one implies the other. To address this gap, we leverage a body of work in information theory called partial information decomposition (PID) which first identifies three sources of unfairness in FL, namely, \emph{Unique Disparity}, \emph{Redundant Disparity}, and \emph{Masked Disparity}. Using canonical examples, we demonstrate how these three disparities contribute to global and local fairness. This decomposition helps us derive fundamental limits and trade-offs between global or local fairness, particularly under data heterogeneity, as well as, derive conditions under which one implies the other. We also present experimental results on benchmark datasets to support our theoretical findings. This work offers a more nuanced understanding of the sources of disparity in FL that can inform the use of local disparity mitigation techniques, and their convergence and effectiveness when deployed in practice.
Robust Counterfactual Explanations for Neural Networks With Probabilistic Guarantees
May 19, 2023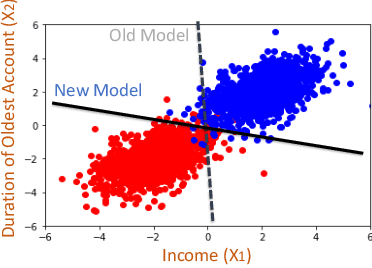
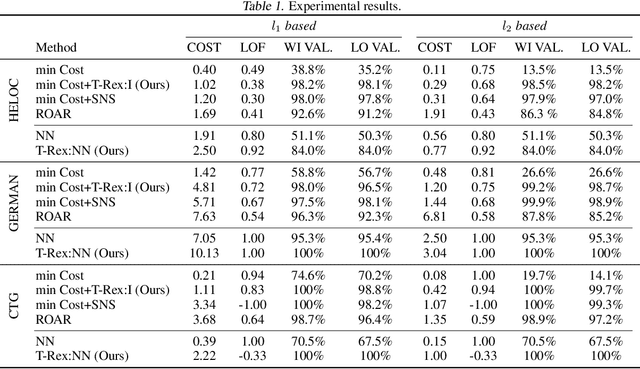
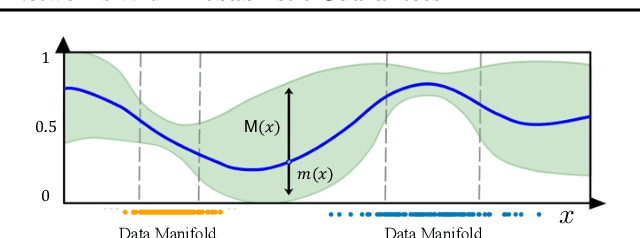
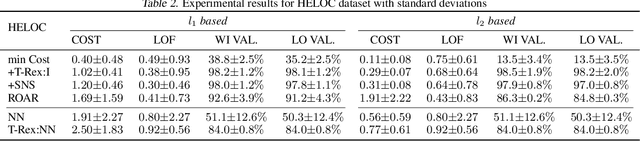
There is an emerging interest in generating robust counterfactual explanations that would remain valid if the model is updated or changed even slightly. Towards finding robust counterfactuals, existing literature often assumes that the original model $m$ and the new model $M$ are bounded in the parameter space, i.e., $\|\text{Params}(M){-}\text{Params}(m)\|{<}\Delta$. However, models can often change significantly in the parameter space with little to no change in their predictions or accuracy on the given dataset. In this work, we introduce a mathematical abstraction termed \emph{naturally-occurring} model change, which allows for arbitrary changes in the parameter space such that the change in predictions on points that lie on the data manifold is limited. Next, we propose a measure -- that we call \emph{Stability} -- to quantify the robustness of counterfactuals to potential model changes for differentiable models, e.g., neural networks. Our main contribution is to show that counterfactuals with sufficiently high value of \emph{Stability} as defined by our measure will remain valid after potential ``naturally-occurring'' model changes with high probability (leveraging concentration bounds for Lipschitz function of independent Gaussians). Since our quantification depends on the local Lipschitz constant around a data point which is not always available, we also examine practical relaxations of our proposed measure and demonstrate experimentally how they can be incorporated to find robust counterfactuals for neural networks that are close, realistic, and remain valid after potential model changes.
Can Querying for Bias Leak Protected Attributes? Achieving Privacy With Smooth Sensitivity
Nov 03, 2022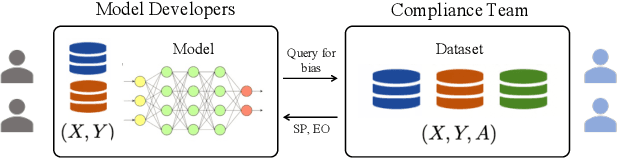
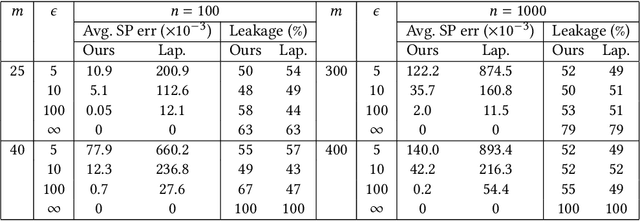

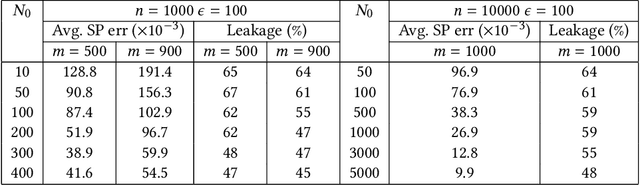
Existing regulations prohibit model developers from accessing protected attributes (gender, race, etc.), often resulting in fairness assessments on populations without knowing their protected groups. In such scenarios, institutions often adopt a separation between the model developers (who train models with no access to the protected attributes) and a compliance team (who may have access to the entire dataset for auditing purpose). However, the model developers might be allowed to test their models for bias by querying the compliance team for group fairness metrics. In this paper, we first demonstrate that simply querying for fairness metrics, such as statistical parity and equalized odds can leak the protected attributes of individuals to the model developers. We demonstrate that there always exist strategies by which the model developers can identify the protected attribute of a targeted individual in the test dataset from just a single query. In particular, we show that one can reconstruct the protected attributes of all the individuals from O(Nk log n/Nk) queries when Nk<<n using techniques from compressed sensing (n: size of the test dataset, Nk: size of smallest group). Our results pose an interesting debate in algorithmic fairness: should querying for fairness metrics be viewed as a neutral-valued solution to ensure compliance with regulations? Or, does it constitute a violation of regulations and privacy if the number of queries answered is enough for the model developers to identify the protected attributes of specific individuals? To address this supposed violation, we also propose Attribute-Conceal, a novel technique that achieves differential privacy by calibrating noise to the smooth sensitivity of our bias query, outperforming naive techniques such as Laplace mechanism. We also include experimental results on the Adult dataset and synthetic data (broad range of parameters).