 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Prediction Consistency Under Model Multiplicity in Tabular LLMs
Paper and Code
Jul 04, 2024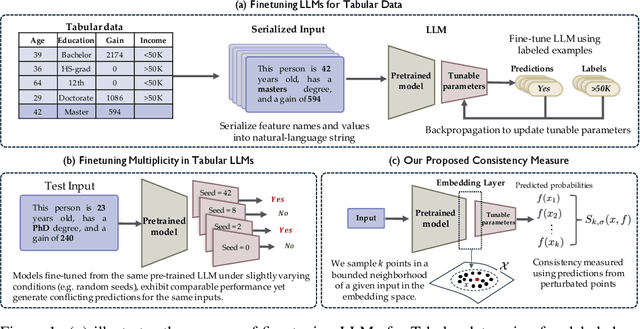
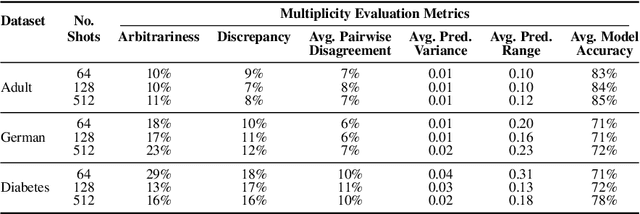
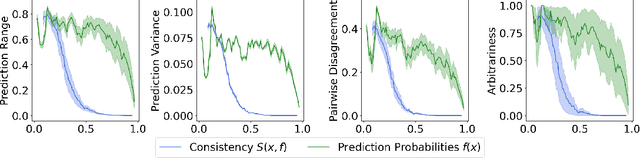
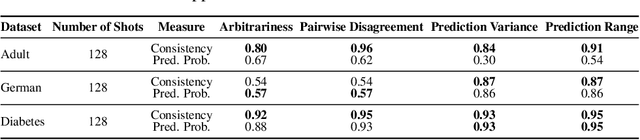
Fine-tuning large language models (LLMs) on limited tabular data for classification tasks can lead to \textit{fine-tuning multiplicity}, where equally well-performing models make conflicting predictions on the same inputs due to variations in the training process (i.e., seed, random weight initialization, retraining on additional or deleted samples). This raises critical concerns about the robustness and reliability of Tabular LLMs, particularly when deployed for high-stakes decision-making, such as finance, hiring, education, healthcare, etc. This work formalizes the challenge of fine-tuning multiplicity in Tabular LLMs and proposes a novel metric to quantify the robustness of individual predictions without expensive model retraining. Our metric quantifies a prediction's stability by analyzing (sampling) the model's local behavior around the input in the embedding space. Interestingly, we show that sampling in the local neighborhood can be leveraged to provide probabilistic robustness guarantees against a broad class of fine-tuned models. By leveraging Bernstein's Inequality, we show that predictions with sufficiently high robustness (as defined by our measure) will remain consistent with high probability. We also provide empirical evaluation on real-world datasets to support our theoretical results. Our work highlights the importance of addressing fine-tuning instabilities to enable trustworthy deployment of LLMs in high-stakes and safety-critical applications.