 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMargin Matching Preference Optimization: Enhanced Model Alignment with Granular Feedback
Oct 04, 2024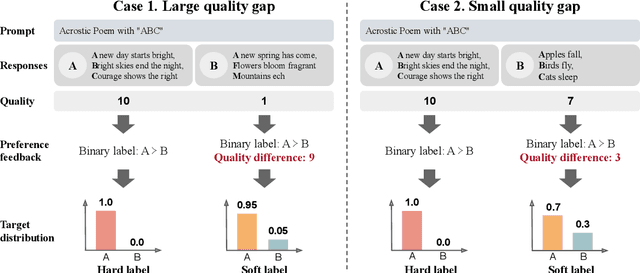
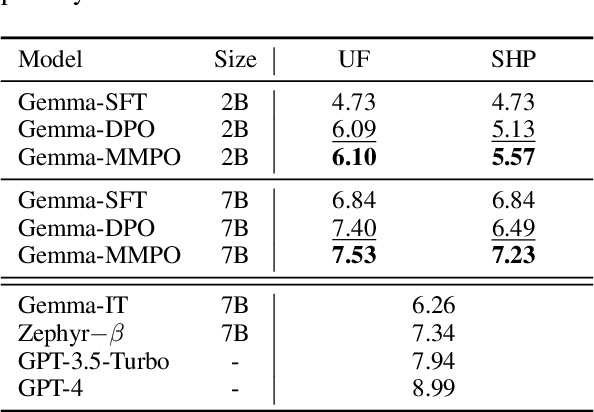
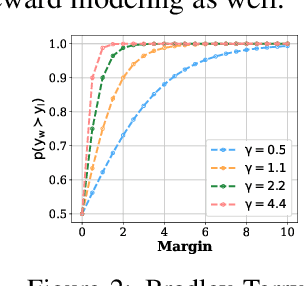
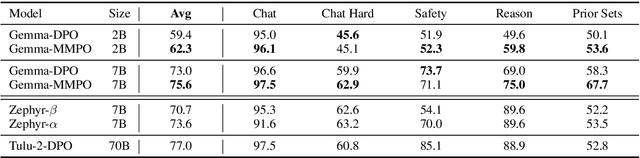
Large language models (LLMs) fine-tuned with alignment techniques, such as reinforcement learning from human feedback, have been instrumental in developing some of the most capable AI systems to date. Despite their success, existing methods typically rely on simple binary labels, such as those indicating preferred outputs in pairwise preferences, which fail to capture the subtle differences in relative quality between pairs. To address this limitation, we introduce an approach called Margin Matching Preference Optimization (MMPO), which incorporates relative quality margins into optimization, leading to improved LLM policies and reward models. Specifically, given quality margins in pairwise preferences, we design soft target probabilities based on the Bradley-Terry model, which are then used to train models with the standard cross-entropy objective. Experiments with both human and AI feedback data demonstrate that MMPO consistently outperforms baseline methods, often by a substantial margin, on popular benchmarks including MT-bench and RewardBench. Notably, the 7B model trained with MMPO achieves state-of-the-art performance on RewardBench as of June 2024, outperforming other models of the same scale. Our analysis also shows that MMPO is more robust to overfitting, leading to better-calibrated models.
Optimized Feature Generation for Tabular Data via LLMs with Decision Tree Reasoning
Jun 12, 2024Learning effective representations from raw data is crucial for the success of deep learning methods. However, in the tabular domain, practitioners often prefer augmenting raw column features over using learned representations, as conventional tree-based algorithms frequently outperform competing approaches. As a result, feature engineering methods that automatically generate candidate features have been widely used. While these approaches are often effective, there remains ambiguity in defining the space over which to search for candidate features. Moreover, they often rely solely on validation scores to select good features, neglecting valuable feedback from past experiments that could inform the planning of future experiments. To address the shortcomings, we propose a new tabular learning framework based on large language models (LLMs), coined Optimizing Column feature generator with decision Tree reasoning (OCTree). Our key idea is to leverage LLMs' reasoning capabilities to find good feature generation rules without manually specifying the search space and provide language-based reasoning information highlighting past experiments as feedback for iterative rule improvements. Here, we choose a decision tree as reasoning as it can be interpreted in natural language, effectively conveying knowledge of past experiments (i.e., the prediction models trained with the generated features) to the LLM. Our empirical results demonstrate that this simple framework consistently enhances the performance of various prediction models across diverse tabular benchmarks, outperforming competing automatic feature engineering methods.
Confidence-aware Reward Optimization for Fine-tuning Text-to-Image Models
Apr 02, 2024



Fine-tuning text-to-image models with reward functions trained on human feedback data has proven effective for aligning model behavior with human intent. However, excessive optimization with such reward models, which serve as mere proxy objectives, can compromise the performance of fine-tuned models, a phenomenon known as reward overoptimization. To investigate this issue in depth, we introduce the Text-Image Alignment Assessment (TIA2) benchmark, which comprises a diverse collection of text prompts, images, and human annotations. Our evaluation of several state-of-the-art reward models on this benchmark reveals their frequent misalignment with human assessment. We empirically demonstrate that overoptimization occurs notably when a poorly aligned reward model is used as the fine-tuning objective. To address this, we propose TextNorm, a simple method that enhances alignment based on a measure of reward model confidence estimated across a set of semantically contrastive text prompts. We demonstrate that incorporating the confidence-calibrated rewards in fine-tuning effectively reduces overoptimization, resulting in twice as many wins in human evaluation for text-image alignment compared against the baseline reward models.