 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTABED: Test-Time Adaptive Ensemble Drafting for Robust Speculative Decoding in LVLMs
Jan 28, 2026Speculative decoding (SD) has proven effective for accelerating LLM inference by quickly generating draft tokens and verifying them in parallel. However, SD remains largely unexplored for Large Vision-Language Models (LVLMs), which extend LLMs to process both image and text prompts. To address this gap, we benchmark existing inference methods with small draft models on 11 datasets across diverse input scenarios and observe scenario-specific performance fluctuations. Motivated by these findings, we propose Test-time Adaptive Batched Ensemble Drafting (TABED), which dynamically ensembles multiple drafts obtained via batch inference by leveraging deviations from past ground truths available in the SD setting. The dynamic ensemble method achieves an average robust walltime speedup of 1.74x over autoregressive decoding and a 5% improvement over single drafting methods, while remaining training-free and keeping ensembling costs negligible through parameter sharing. With its plug-and-play compatibility, we further enhance TABED by integrating advanced verification and alternative drafting methods. Code and custom-trained models are available at https://github.com/furiosa-ai/TABED.
ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs
Oct 06, 2025While most autoregressive LLMs are constrained to one-by-one decoding, diffusion LLMs (dLLMs) have attracted growing interest for their potential to dramatically accelerate inference through parallel decoding. Despite this promise, the conditional independence assumption in dLLMs causes parallel decoding to ignore token dependencies, inevitably degrading generation quality when these dependencies are strong. However, existing works largely overlook these inherent challenges, and evaluations on standard benchmarks (e.g., math and coding) are not sufficient to capture the quality degradation caused by parallel decoding. To address this gap, we first provide an information-theoretic analysis of parallel decoding. We then conduct case studies on analytically tractable synthetic list operations from both data distribution and decoding strategy perspectives, offering quantitative insights that highlight the fundamental limitations of parallel decoding. Building on these insights, we propose ParallelBench, the first benchmark specifically designed for dLLMs, featuring realistic tasks that are trivial for humans and autoregressive LLMs yet exceptionally challenging for dLLMs under parallel decoding. Using ParallelBench, we systematically analyze both dLLMs and autoregressive LLMs, revealing that: (i) dLLMs under parallel decoding can suffer dramatic quality degradation in real-world scenarios, and (ii) current parallel decoding strategies struggle to adapt their degree of parallelism based on task difficulty, thus failing to achieve meaningful speedup without compromising quality. Our findings underscore the pressing need for innovative decoding methods that can overcome the current speed-quality trade-off. We release our benchmark to help accelerate the development of truly efficient dLLMs.
UNCAGE: Contrastive Attention Guidance for Masked Generative Transformers in Text-to-Image Generation
Aug 07, 2025Text-to-image (T2I) generation has been actively studied using Diffusion Models and Autoregressive Models. Recently, Masked Generative Transformers have gained attention as an alternative to Autoregressive Models to overcome the inherent limitations of causal attention and autoregressive decoding through bidirectional attention and parallel decoding, enabling efficient and high-quality image generation. However, compositional T2I generation remains challenging, as even state-of-the-art Diffusion Models often fail to accurately bind attributes and achieve proper text-image alignment. While Diffusion Models have been extensively studied for this issue, Masked Generative Transformers exhibit similar limitations but have not been explored in this context. To address this, we propose Unmasking with Contrastive Attention Guidance (UNCAGE), a novel training-free method that improves compositional fidelity by leveraging attention maps to prioritize the unmasking of tokens that clearly represent individual objects. UNCAGE consistently improves performance in both quantitative and qualitative evaluations across multiple benchmarks and metrics, with negligible inference overhead. Our code is available at https://github.com/furiosa-ai/uncage.
Sparsified State-Space Models are Efficient Highway Networks
May 27, 2025State-space models (SSMs) offer a promising architecture for sequence modeling, providing an alternative to Transformers by replacing expensive self-attention with linear recurrences. In this paper, we propose a simple yet effective trick to enhance SSMs within given computational budgets by sparsifying them. Our intuition is that tokens in SSMs are highly redundant due to gradual recurrent updates, and dense recurrence operations block the delivery of past information. In particular, we observe that upper layers of SSMs tend to be more redundant as they encode global information, while lower layers encode local information. Motivated by this, we introduce Simba, a hierarchical sparsification method for SSMs based on token pruning. Simba sparsifies upper layers more than lower layers, encouraging the upper layers to behave like highways. To achieve this, we propose a novel token pruning criterion for SSMs, measuring the global impact of tokens on the final output by accumulating local recurrences. We demonstrate that Simba outperforms the baseline model, Mamba, with the same FLOPS in various natural language tasks. Moreover, we illustrate the effect of highways, showing that Simba not only enhances efficiency but also improves the information flow across long sequences. Code is available at https://github.com/woominsong/Simba.
ReVISE: Learning to Refine at Test-Time via Intrinsic Self-Verification
Feb 20, 2025Self-awareness, i.e., the ability to assess and correct one's own generation, is a fundamental aspect of human intelligence, making its replication in large language models (LLMs) an important yet challenging task. Previous works tackle this by employing extensive reinforcement learning or rather relying on large external verifiers. In this work, we propose Refine via Intrinsic Self-Verification (ReVISE), an efficient and effective framework that enables LLMs to self-correct their outputs through self-verification. The core idea of ReVISE is to enable LLMs to verify their reasoning processes and continually rethink reasoning trajectories based on its verification. We introduce a structured curriculum based upon online preference learning to implement this efficiently. Specifically, as ReVISE involves two challenging tasks (i.e., self-verification and reasoning correction), we tackle each task sequentially using curriculum learning, collecting both failed and successful reasoning paths to construct preference pairs for efficient training. During inference, our approach enjoys natural test-time scaling by integrating self-verification and correction capabilities, further enhanced by our proposed confidence-aware decoding mechanism. Our experiments on various reasoning tasks demonstrate that ReVISE achieves efficient self-correction and significantly improves reasoning performance.
Optimized Feature Generation for Tabular Data via LLMs with Decision Tree Reasoning
Jun 12, 2024Learning effective representations from raw data is crucial for the success of deep learning methods. However, in the tabular domain, practitioners often prefer augmenting raw column features over using learned representations, as conventional tree-based algorithms frequently outperform competing approaches. As a result, feature engineering methods that automatically generate candidate features have been widely used. While these approaches are often effective, there remains ambiguity in defining the space over which to search for candidate features. Moreover, they often rely solely on validation scores to select good features, neglecting valuable feedback from past experiments that could inform the planning of future experiments. To address the shortcomings, we propose a new tabular learning framework based on large language models (LLMs), coined Optimizing Column feature generator with decision Tree reasoning (OCTree). Our key idea is to leverage LLMs' reasoning capabilities to find good feature generation rules without manually specifying the search space and provide language-based reasoning information highlighting past experiments as feedback for iterative rule improvements. Here, we choose a decision tree as reasoning as it can be interpreted in natural language, effectively conveying knowledge of past experiments (i.e., the prediction models trained with the generated features) to the LLM. Our empirical results demonstrate that this simple framework consistently enhances the performance of various prediction models across diverse tabular benchmarks, outperforming competing automatic feature engineering methods.
Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs
Apr 16, 2024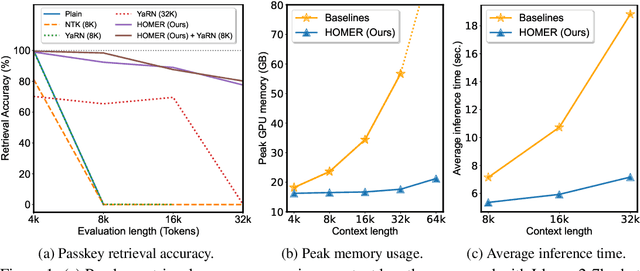
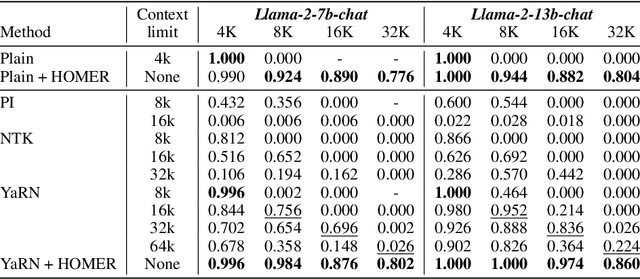
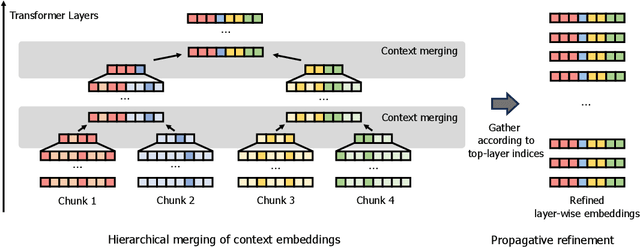
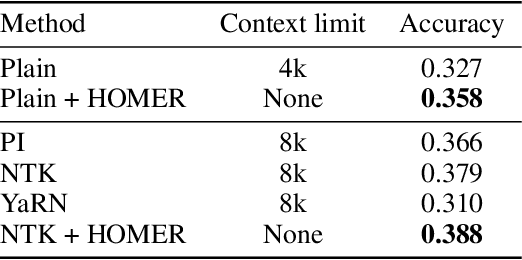
Large language models (LLMs) have shown remarkable performance in various natural language processing tasks. However, a primary constraint they face is the context limit, i.e., the maximum number of tokens they can process. Previous works have explored architectural changes and modifications in positional encoding to relax the constraint, but they often require expensive training or do not address the computational demands of self-attention. In this paper, we present Hierarchical cOntext MERging (HOMER), a new training-free scheme designed to overcome the limitations. HOMER uses a divide-and-conquer algorithm, dividing long inputs into manageable chunks. Each chunk is then processed collectively, employing a hierarchical strategy that merges adjacent chunks at progressive transformer layers. A token reduction technique precedes each merging, ensuring memory usage efficiency. We also propose an optimized computational order reducing the memory requirement to logarithmically scale with respect to input length, making it especially favorable for environments with tight memory restrictions. Our experiments demonstrate the proposed method's superior performance and memory efficiency, enabling the broader use of LLMs in contexts requiring extended context. Code is available at https://github.com/alinlab/HOMER.